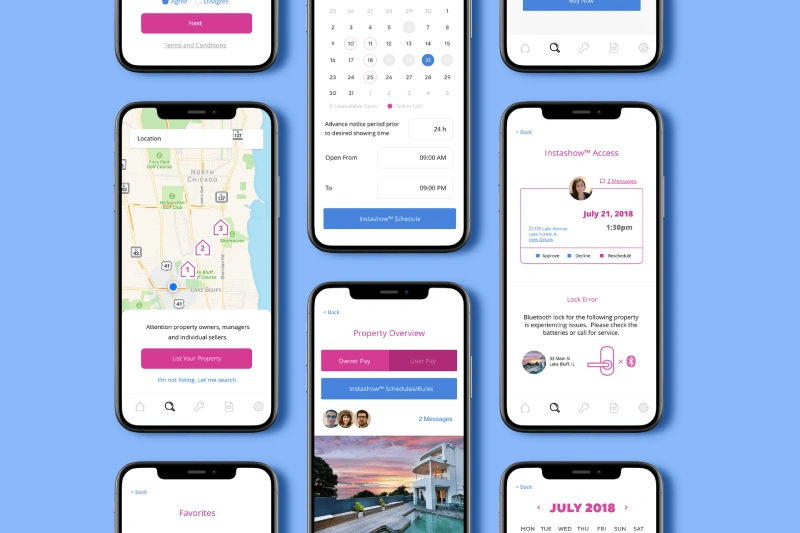
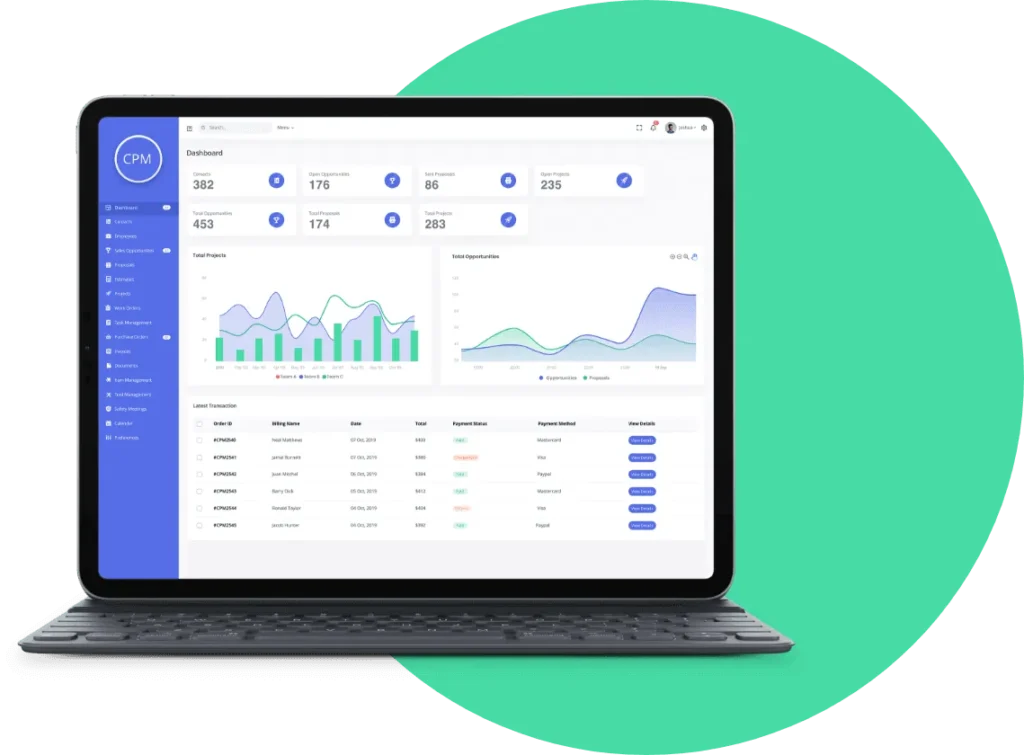
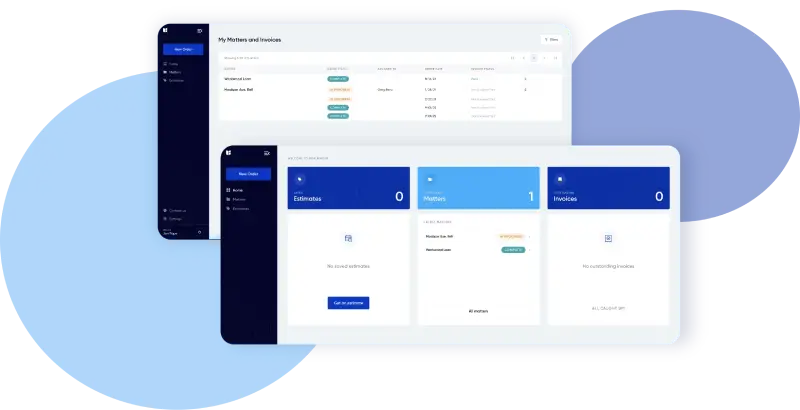
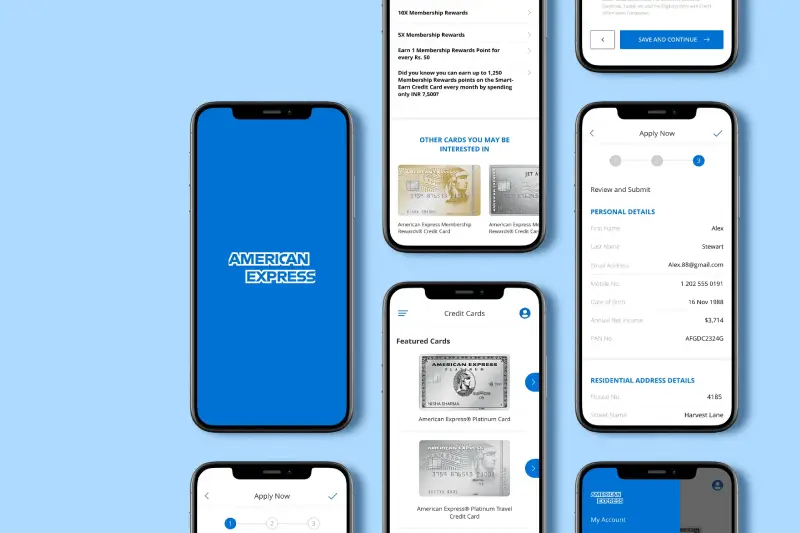
Mobile App • iOS • Android
The Healthy Mummy
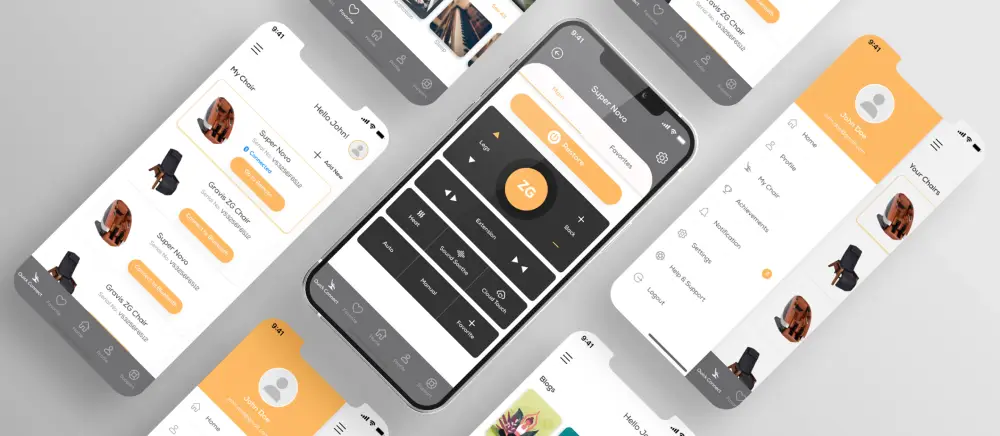
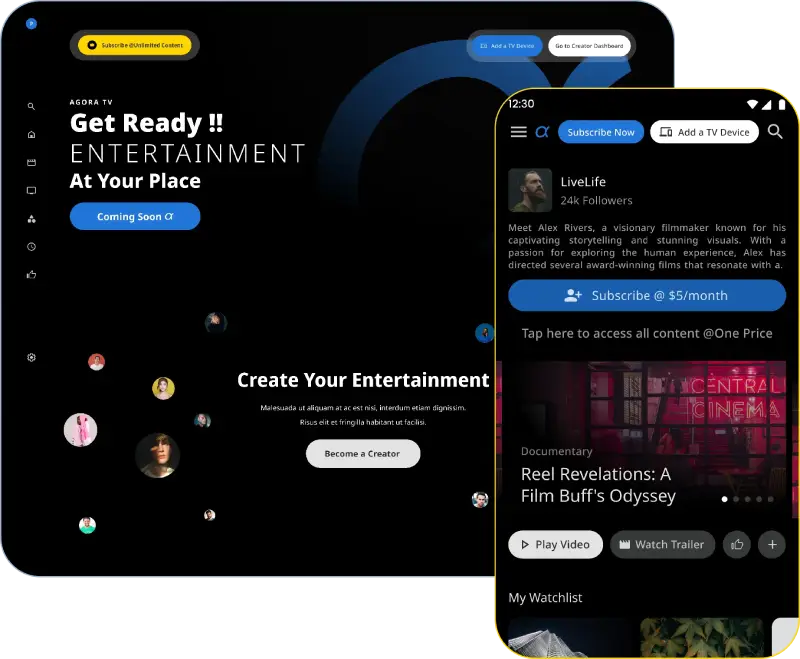
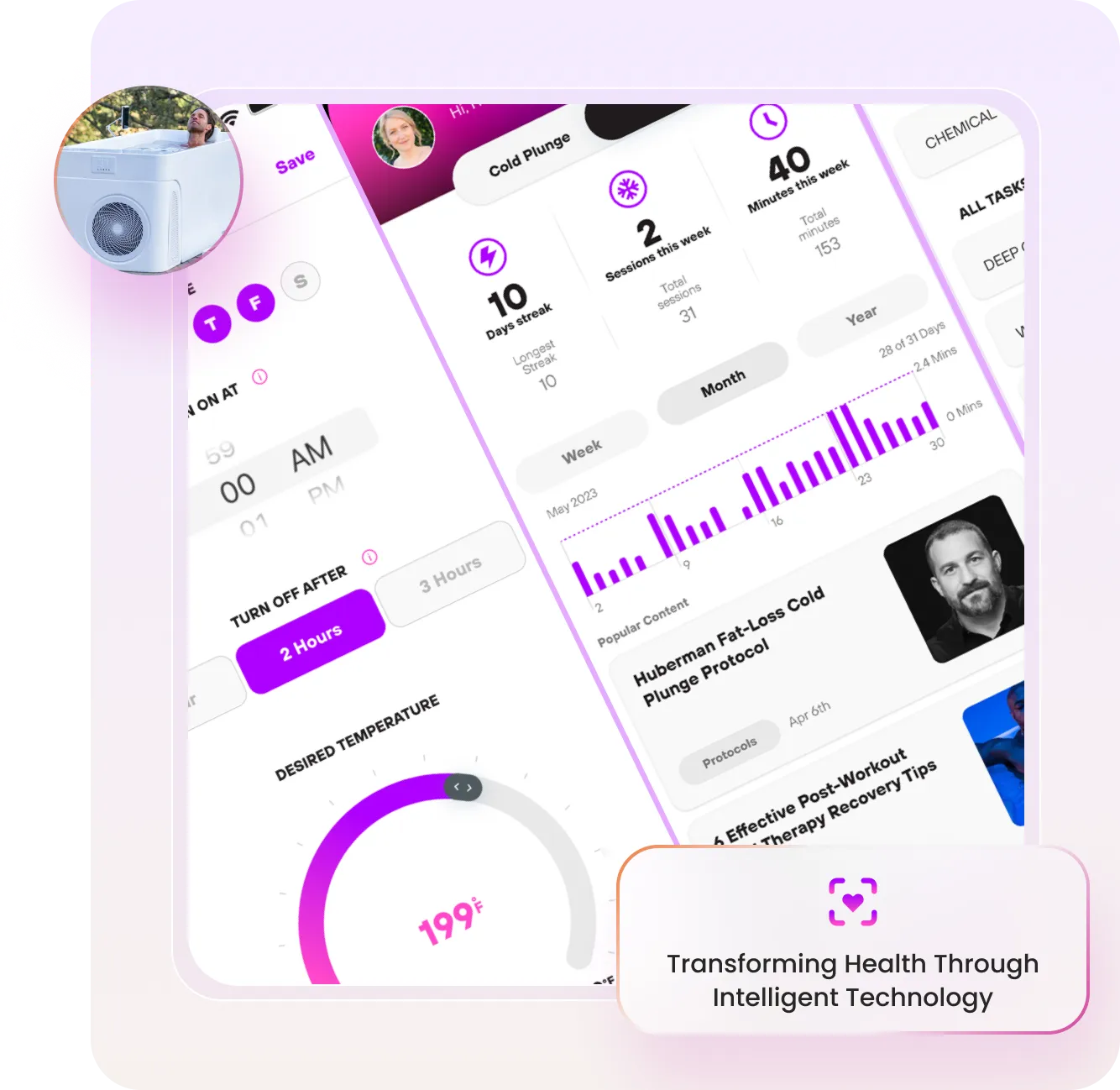
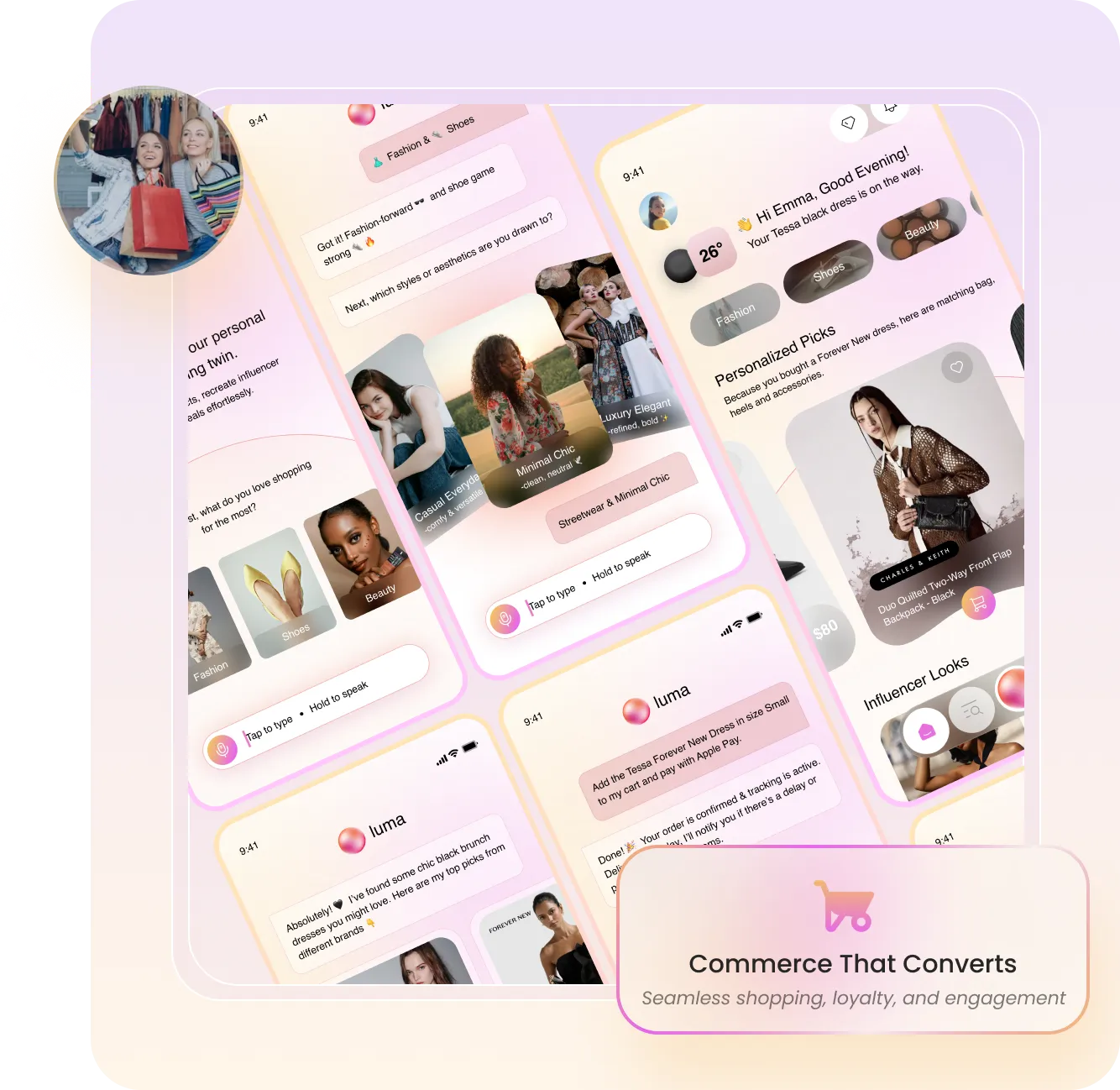
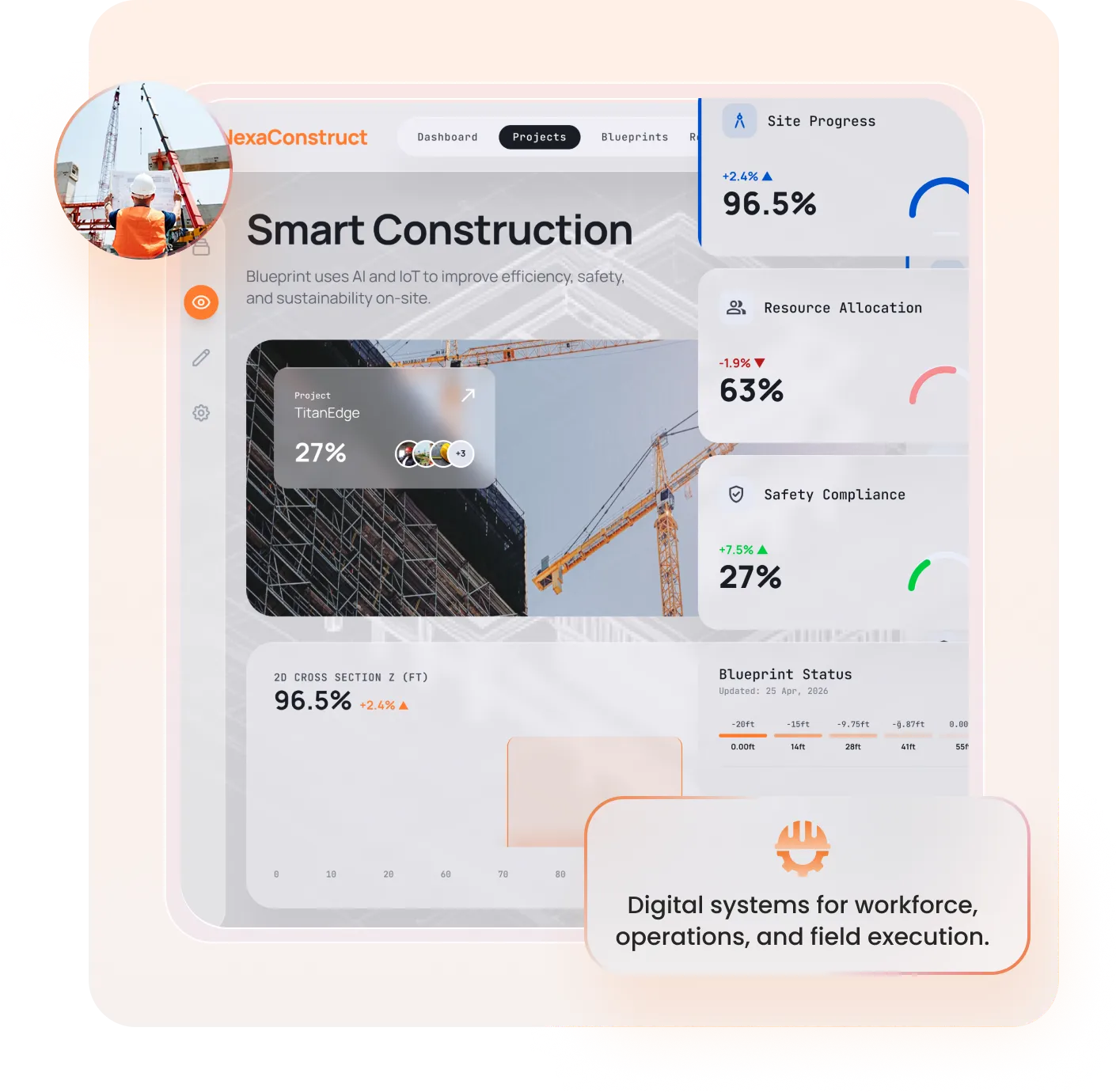
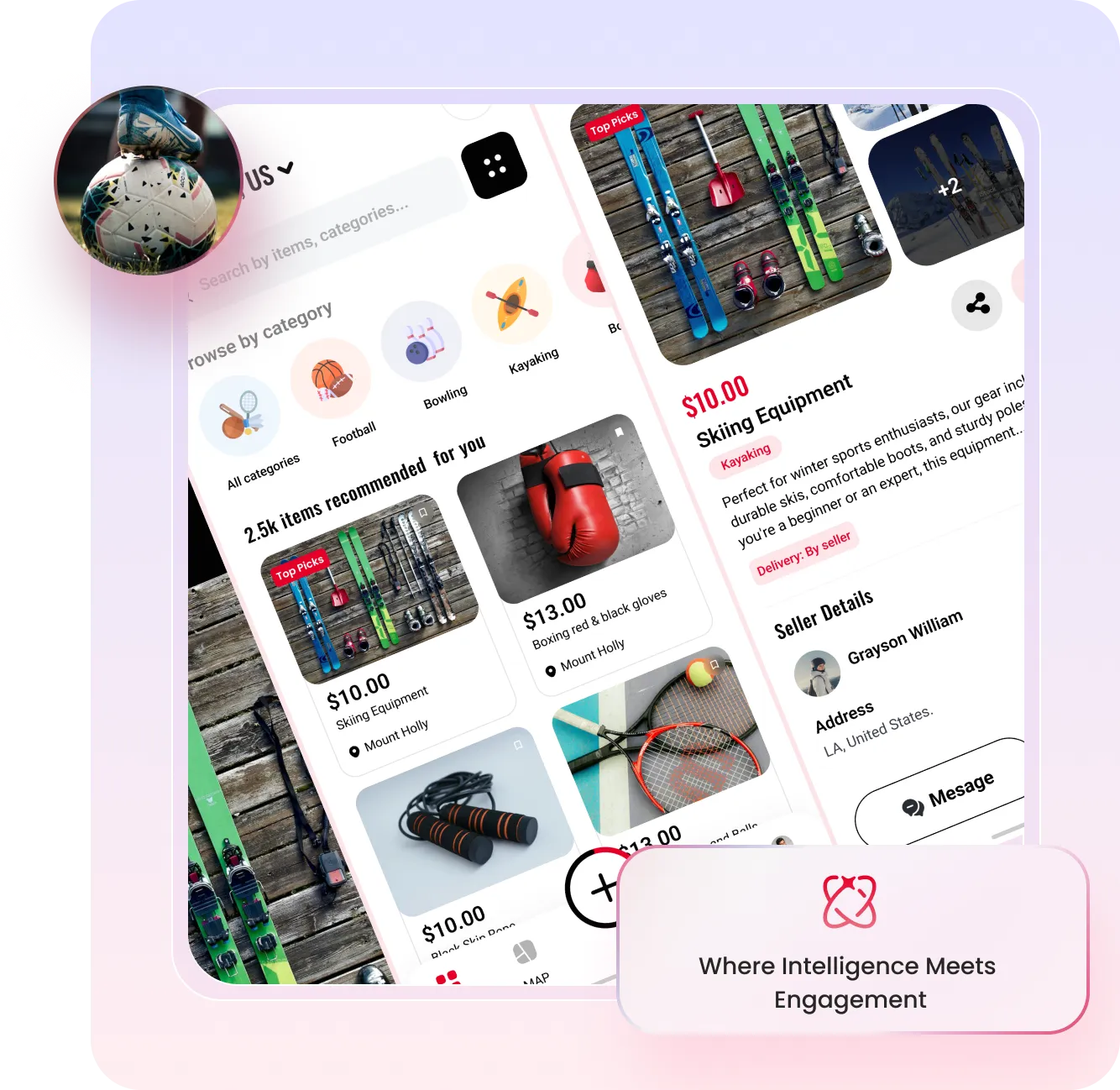
A comprehensive fitness and wellness platform empowering mothers with personalized nutrition plans and workout programs.
1M+ active users • Top-rated fitness app • Global community
Read Case Study