

















 Copy Link
Copy Link Share on X
Share on X Share on Facebook
Share on Facebook Share on LinkedIn
Share on LinkedIn


Always Active
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Build intelligent AI systems that automate decisions, accelerate innovation, and scale business growth.
Design, build, modernize, and scale digital products that drive business growth.
Build secure, scalable, and intelligent platforms that power modern enterprises.
Build intelligent, connected, and autonomous systems that operate in the real world.
Flexible engineering capacity with predictable delivery, ownership, and outcomes.
Uncover the transformative potential of digital and mobile solutions for your industry

 Last Updated: Jun 25, 2026
Jun 15, 2026
Last Updated: Jun 25, 2026
Jun 15, 2026  257
257  26 min. Read
26 min. Read



Key Takeaways
Every financial institution processes disputed transactions. How well they do it determines customer retention, regulatory standing, and operational cost in equal measure. The scale of that function has changed considerably, and the systems built to manage it have not kept pace.
Visa processed 106 million disputes globally in 2025, up 35% since 2019. The global value of chargebacks is forecasted to reach $46.1 billion by 2029, with volumes projected to grow 37% between 2025 and 2029, reaching 359 million transactions annually.
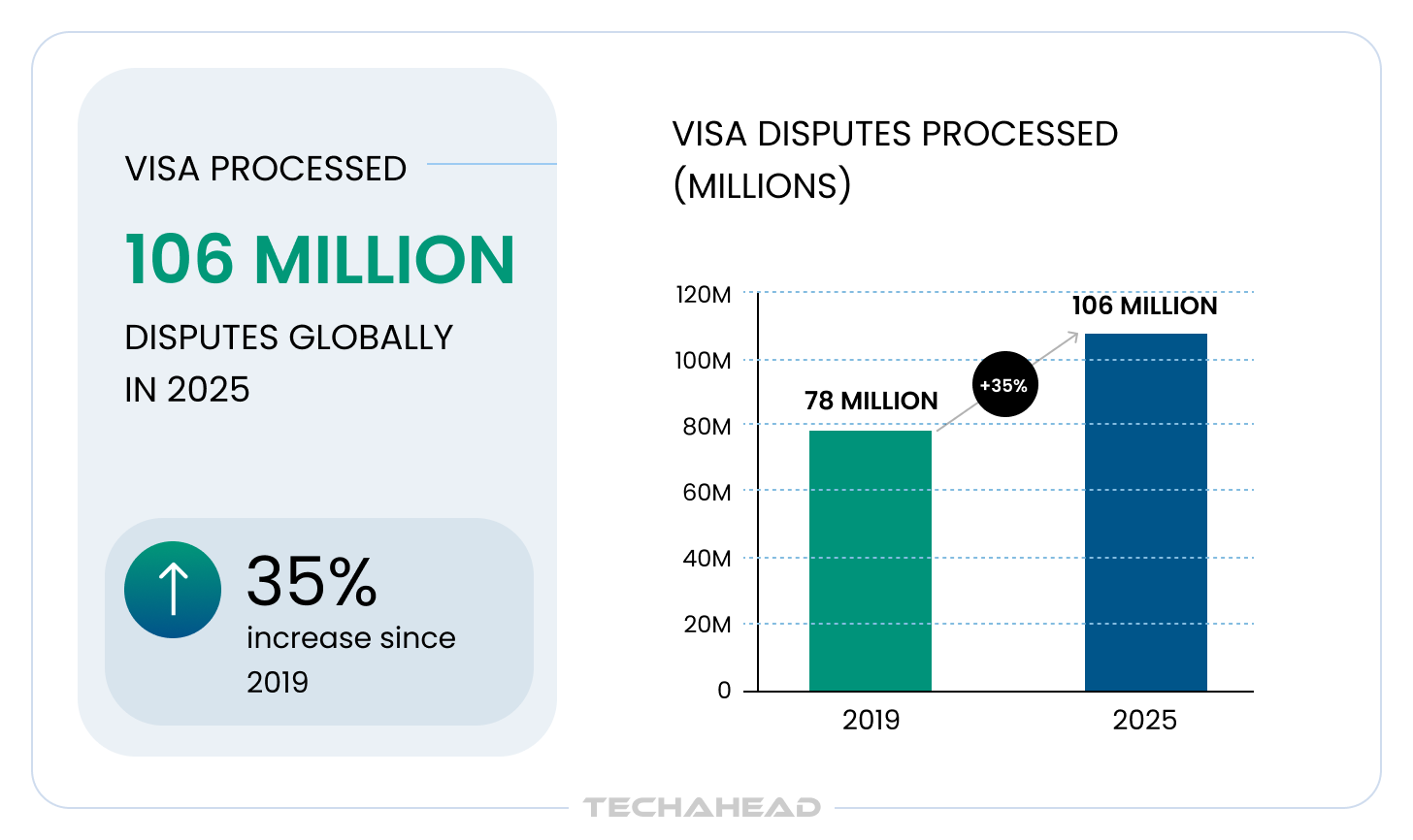
Behind every one of those numbers is a disputed transaction that someone had to investigate. And in most banks and fintechs, that someone is a human analyst working across four disconnected systems, under regulatory deadline pressure, assembling documentation manually before a single decision can be made.
That workflow was straining at 2023 volumes. At 2026 volumes, it is a structural liability.
AI dispute resolution does not fix this by automating around the edges of the existing process. It fixes it by replacing the architecture underneath: not with a single, all-purpose bot that handles everything with mediocrity, but with a coordinated system of specialized agents where each agent does one thing precisely, handoffs are clean, and every decision is auditable from intake to resolution.
This guide covers what that architecture looks like in practice, what real firms have already built, and how to make the decision most enterprises face before anything gets deployed: off-the-shelf platform or a custom system designed based on your organizational requirements.
Must Read: Vertical AI Agents in Fintech

The phrase “automate dispute resolution” makes it sound like a single workflow problem. It is not.
A single contested transaction can involve the customer, merchant, and bank as the relevant parties involved, along with transaction evidence retrieval, authentication log review, merchant verification, fraud cross-referencing, regulatory classification, provisional credit assessment, enterprise AI compliance documentation, and customer notification before a resolution decision is reached. Each function draws on different data sources, applies different logic, and produces output; the next step depends on being correctly structured.
When one AI agent is asked to handle all of that, it becomes generalized across too many distinct functions to do any of them with the precision a production financial environment demands. The result is a dispute management system that performs adequately under demo conditions and inconsistently under production ones. That is exactly the failure mode that appears in post-mortems six months after deployment.
The operational consequences are not just internal. Quavo’s Trust in Banking research found that 62% of consumers say their trust in a bank is shaped more by how their dispute is handled than by the fraud event itself.
The operational failure compounds into a retention failure. Both trace back to the same root cause: a workflow that was not built for the complexity it is being asked to carry.
Also Read: Agent Loop Explained
Why multi-agent AI dispute resolution structurally outperforms single-agent approaches:
Analysts in traditional automated dispute resolution banking environments spend 30–40% of their time gathering information before a single analysis step begins. Unlike traditional litigation, where legal costs rise with every manual handoff, this is not just an efficiency problem. That is what it costs when the architecture forces sequential, manual data retrieval before judgment can start.
Also Read: Agent2Agent Architecture
A mid-sized regional bank came to TechAhead with a dispute backlog growing over 40% quarter-on-quarter. Analysts were spending the majority of each case’s time pulling records across four separate systems before any analysis could begin. The multi-agent redesign compressed that evidence-gathering phase from hours to minutes, allowing analysts to focus entirely on judgment calls rather than data retrieval.
Agentic AI for dispute resolution in production is not one model with a sophisticated prompt. It is a coordinated system of purpose-built agents, each with a defined function, connected by an orchestration layer that manages state, sequencing, error handling, and human escalation paths.
Understanding how to implement multi-agent AI for financial dispute resolution starts with understanding what each agent is responsible for and why separating those responsibilities is what makes the system reliable at production scale.

Receives the dispute notification and uses artificial intelligence, including Natural Language Processing, to classify incoming disputes simultaneously across multiple dimensions: dispute type, applicable regulatory framework, deadline structure, preliminary priority score, and predictive analytics about likely case outcomes. It assembles the initial case file by querying connected systems before the next agent in the workflow is invoked, with AI models and large language models supporting that early assessment.
What this replaces is not just manual triage time. It replaces inconsistency. Human intake processes apply judgment that varies across analysts, shifts, and workload conditions. The intake agent applies the same classification logic at 2pm on Tuesday and 11pm on Friday, which reflects one of the key benefits and potential benefits here: more reliable early decision making in the resolution process, and every downstream agent inherits a consistently structured starting point either way.
Also Read: Building Autonomous Agents with LLMs
Pulls transaction records, authentication logs, merchant verification data, chargeback history, and prior dispute records from connected systems simultaneously, not sequentially, so the agent can process large volumes of records across systems and support a faster, more cost effective resolution process. AI systems can then analyze the assembled evidence, identify key issues, and in some cases predict settlement ranges or suggest fair, evidence-based resolutions for lower-value disputes such as contract disputes or intellectual property infringement cases. The output is structured into a case-ready format the decision agent can act on directly, without additional interpretation.
The speed improvement is real and visible. The more material improvement is completeness. Evidence gathering under deadline pressure tends to stop when enough has been assembled. An evidence agent pulls the full picture regardless, because it takes seconds either way, which supports better outcomes and fairer outcomes when evidence is reviewed consistently.
Applies the relevant regulatory and card network rule framework to the assembled evidence, helps sharpen legal arguments, supports decision making, generates a resolution recommendation with fully documented rationale, and flags ambiguities (partial evidence, conflicting records, unusual transaction patterns) for human judgment before the decision is finalized, all within defined rule boundaries.
That matters because AI generated analyses can reproduce historical biases from training data or produce confident but fabricated outputs if the underlying AI systems are not properly constrained.
The rationale is not a summary. It is a step-by-step reasoning record, retrievable on demand if the resolution is challenged by an internal audit team, a regulator, or a customer, because black box decision making falls short in regulated environments and explainability is necessary for fairness and justice.
Must Read: AI Model Cards & Data Provenance
Produces the regulatory-grade case record, supporting clear accountability structures with timestamped decision steps, archived supporting evidence, reasoning rationale, applicable rule citations, and a complete audit trail of the decision-making process. This is a dedicated agent whose sole function is generating documentation that satisfies examination standards at the moment of generation, not a logging layer bolted on after the build, and that documentation is critical for accountability, human oversight, and legal team review.
Drafts negotiation and settlement communications in language appropriate to the channel, jurisdiction, and customer profile. In some dispute resolution systems, AI tools can help identify parties’ underlying interests during negotiation to improve communication and support better outcomes. For institutions managing relationships across mobile, web, and branch channels, consistency and clarity in AI powered dispute resolution communications also strengthen broader conflict resolution across every touchpoint.
Moreover, AI mediation capabilities are increasingly integrated to assist human mediators and neutral third parties during the mediation process, enabling a more efficient and impartial resolution of commercial disputes.
Also Read: 7 Ways Multi-Agent AI Fails in Production
The five agents above are not useful without the system coordinating them. The orchestration layer handles the following:
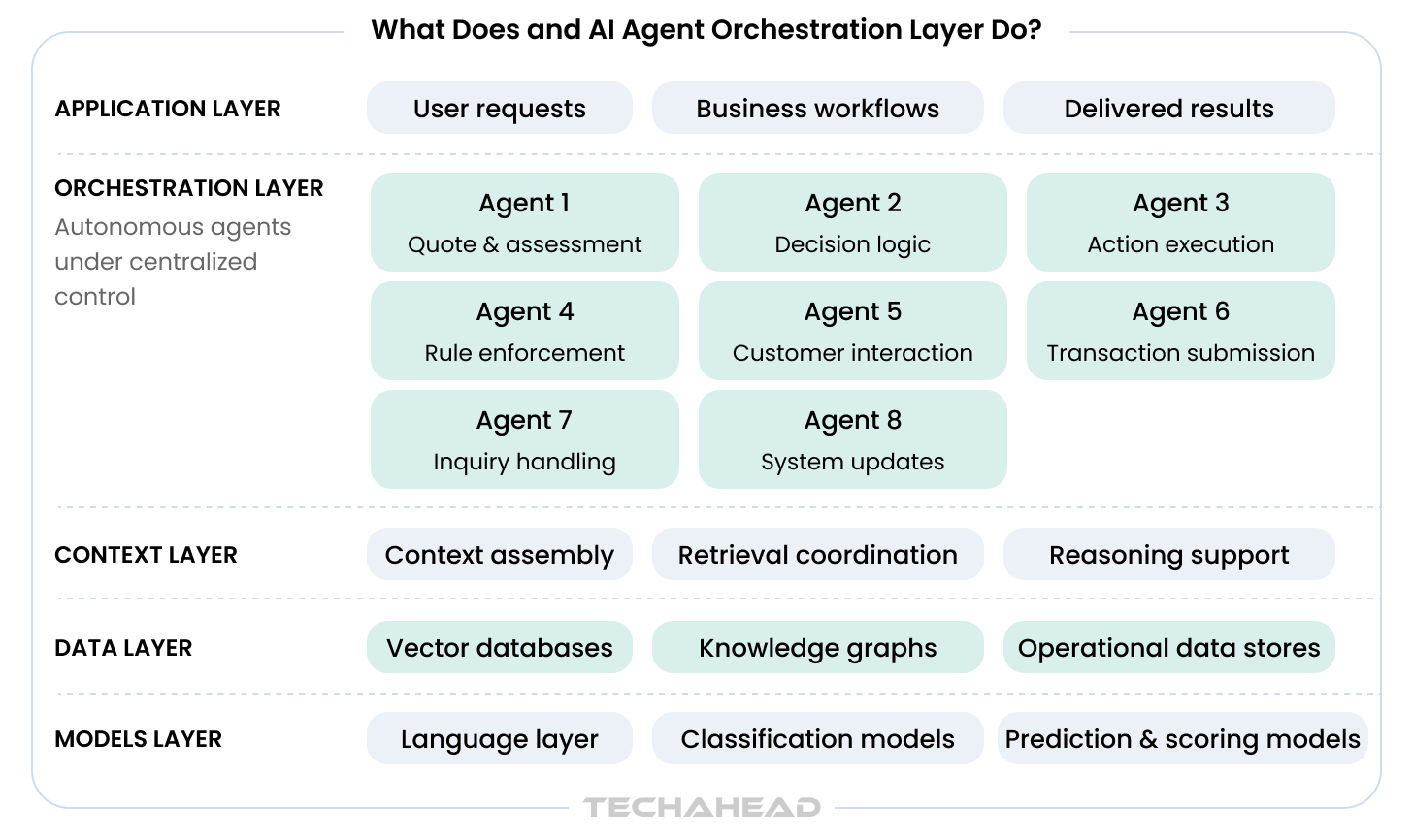
On human-in-the-loop design: escalation to human review is not a concession on automation. It is the architecture decision that makes the system deployable in a regulated environment. Reviewing analysts receive fully assembled case files and make judgment calls; they do not reconstruct context first. That distinction matters as much for throughput as it does for compliance posture.
“The dispute resolution workflow is one of the most architecturally demanding problems in financial AI: not because the technology is uniquely complex, but because the function requires so many distinct, specialized reasoning steps that no single agent can handle reliably at scale. The multi-agent approach is not a design preference. It is the architecture the problem demands.”
— Deepak Sinha, CTO, TechAhead
Recommended: 7 Ways Multi-Agent AI Fails in Production
Most multi-agent AI dispute resolution systems look clean in a sandbox. Tidy API calls, predictable case types, cooperative test data. What you see in a proof of concept is not what you encounter when the system is handling hundreds of concurrent disputes against a legacy core banking platform with inconsistent data schemas and a compliance team waiting on audit-ready documentation.
The institutions that have built this successfully share one thing: they identified these challenges at the architecture stage, not after go-live. Here are the four that most consistently determine whether a dispute resolution workflow automation project makes it to production; and how each gets addressed.
Bonus Read: Why AI Agent Costs Explode and How to Cap Them
| Challenge | Core Problem | How to Address It |
| Legacy System Integration | Core banking platforms were not built for API-first integration, causing evidence retrieval to break on live transaction records | Treat integration as a separate workstream before agent development. Map schemas, build custom connectors, and validate against real transaction samples first |
| Explainability at the Decision Layer | Default model output satisfies neither legal (plain-language rationale) nor regulators (rule-cited reasoning), undermining trust in resolutions | Engineer dual-format output by design: a regulatory record with rule citations and a plain-language summary generated in the same agent pass |
| Human Oversight and Escalation Calibration | Threshold set too sensitive floods analysts; too permissive creates regulatory liability. Automation bias risks reviewers deferring blindly to AI | Calibrate escalation thresholds against historical case data pre-go-live. Treat escalation logic as a tunable parameter monitored post-deployment |
| State Management at Production Volume | Agents running concurrently can overwrite each other’s case context or produce cross-contaminated evidence files at scale | Assign isolated state contexts per case at the orchestration layer. Load test against projected dispute volumes before production deployment |
Most financial institutions run on core banking platforms that were not built for API-first integration. Data security and privacy are also a major concern when AI technology connects to legacy banking systems and dispute records. Getting an evidence retrieval agent to query these systems reliably requires building custom connectors and normalizing data formats before agent development begins. This foundational work is frequently more complex than the agent build itself, and skipping it produces an evidence retrieval function that works on clean test data and breaks on live transaction records.
Bonus Read: Open Banking API Strategy
How to address it: Treat integration as a separate, sequenced workstream that runs before agent development starts, not alongside it. Map each source system’s data schema, build and validate custom connectors, and confirm normalized output against real transaction samples while planning for the secure handling of sensitive case data across connected AI systems before a single agent is written. The agent build is only as reliable as the data layer beneath it.
Explainability is essential in ai in dispute resolution because opaque outputs undermine trust in the dispute resolution process. A decision reasoning agent that produces a resolution recommendation needs to satisfy two audiences simultaneously: internal legal review and external regulatory examination. These are not the same standard. Legal needs plain-language rationale. Regulators need step-by-step documented reasoning tied to specific rule citations. Default model output satisfies neither.
Most people will accept automated support more readily when the resolution path is transparent instead of presented as a black-box recommendation.
How to address it: Engineer the decision reasoning agent to produce dual-format output by design: a structured regulatory record with rule citations and a plain-language summary generated in the same agent pass, stored separately, and linked to the case record at the moment of generation. This explainability layer should support the full workflow, not just the final output. This is a prompt architecture and output schema decision, not a post-hoc formatting task.
The threshold for when the system routes a case to human review is one of the most consequential decisions in the build. Set it too sensitive and analysts are flooded with cases the system should handle autonomously. Set it too permissive and the system makes decisions that create regulatory liability. This threshold cannot be set theoretically.
There is also a risk of automation bias: reviewers may defer too readily to system recommendations unless human judgment remains active.
How to address it: Run a calibration phase using historical case data before go-live, setting initial escalation thresholds against real dispute outcomes rather than assumptions. Use a hybrid approach in which human oversight remains central, with AI models informing reviewer decisions rather than replacing them. Post-deployment, monitor the threshold against resolution accuracy and analyst override rates on a defined review cycle. Escalation logic should be treated as a tunable parameter, not a one-time configuration, and well-calibrated review can also help correct bias in human decision making rather than simply replicate it.
When hundreds of cases run concurrently through the same AI pipeline, shared state management becomes a structural problem. Without deliberate architecture, agents operating in parallel can overwrite each other’s case context or produce cross-contaminated evidence files. This failure mode does not appear in low-volume testing. It surfaces at the scale your production environment will actually run.
How to address it: Assign isolated state contexts per case from intake at the orchestration layer, so no two cases share a memory space regardless of concurrent load. Load test against projected dispute volumes as a required phase before production deployment, and instrument the orchestration layer to flag any state collision events during staging.
Getting these right at the architecture stage is the difference between a system that impresses in a demo and one that holds up under live dispute volumes, a regulatory audit, and two years of evolving fraud patterns.
Readers Also Liked: Decoding MACH Architecture For Enterprise App Development

These are not pilot programs. These are automated dispute resolution banking deployments with documented outcomes, each illustrating a different dimension of what the architecture delivers when built correctly.
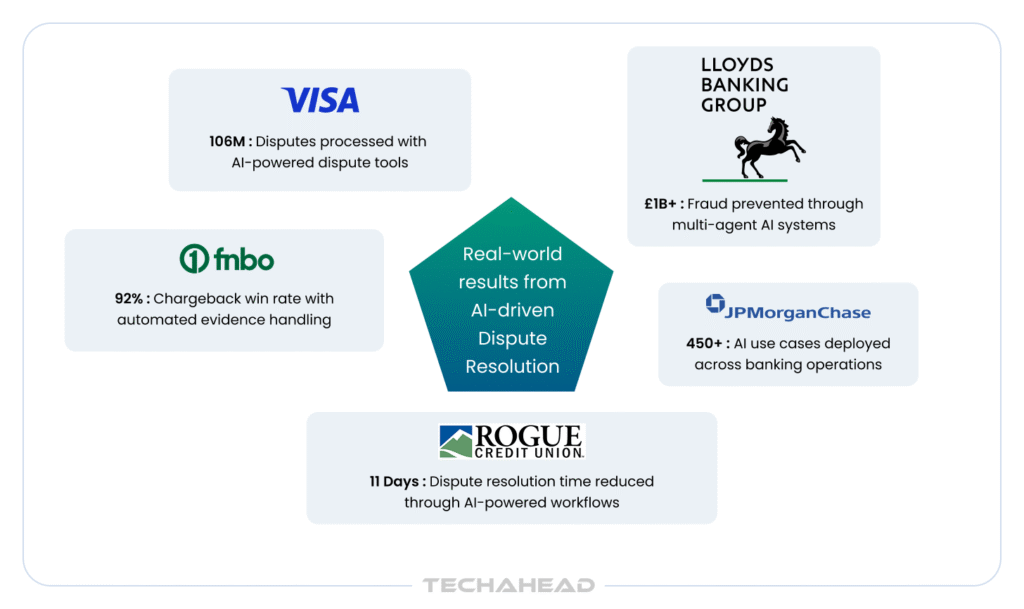
In April 2026, Visa launched six new AI-powered dispute tools covering case intake, document analysis, decision support, and recovery automation, directly responding to processing 106 million disputes in 2025. Dispute Intelligence applies predictive AI to prioritize case reviews; Dispute Doc Analyzer extracts and structures merchant evidence at intake for faster downstream decisioning. Both tools directly mirror the intake and evidence retrieval functions described in the architecture above. The scale of this deployment signals where the entire payments ecosystem is heading for issuers and acquirers alike.
Lloyds deployed a multi-agent agentic AI system built on their internal Envoy platform, running identity checks, transaction analysis, and scam risk assessment in parallel during dispute and fraud interactions. Complex dispute workflows that previously stretched across weeks now resolve in days. The bank prevented over £1 billion in fraud in 2025 and invested £100 million in fraud technology since 2023. The Lloyds deployment is a direct example of the parallel-agent processing that the orchestration layer enables across identity, transaction, and risk functions simultaneously.
JPMorgan’s EVEE generative AI system operates across call center dispute resolution workflow automation, integrating with policy documentation and transaction histories to resolve disputes and account issues faster while reducing human error. EVEE is one of over 450 AI use cases JPMorgan has in production. What makes it relevant here is how it connects to the institution’s existing knowledge infrastructure rather than operating as a standalone tool, which is exactly what makes the decision reasoning agent defensible in practice.
FNBO achieved a 92% chargeback win rate through automated chargeback dispute resolution, against an industry average of 20–30% for manually managed cases. That improvement is a direct function of evidence assembly quality and response accuracy at the point of submission. That is the precise function the evidence retrieval and compliance documentation agents are built to handle. When the right evidence reaches the card network on time and formatted correctly, win rates reflect it.
Rogue Credit Union reduced average dispute resolution time to 11 days through AI-powered automation. For a credit union competing against digital-first challengers, resolution speed is a retention metric as much as an efficiency one. 71% of consumers say long dispute timelines erode trust. Cutting resolution time to 11 days does not just reduce operational cost; that improvement traces directly to eliminating the sequential evidence-gathering delay that the intake and retrieval agents solve by design.
A digital payments firm came to TechAhead needing significantly faster dispute throughput without expanding its compliance team. We built a multi-agent orchestration system connecting their case management, transaction, and customer communication layers. The throughput improvement did not come from raw processing speed. It came from eliminating the evidence-gathering bottleneck at the source.
Most institutions evaluating AI dispute resolution hit the same decision point at some stage: do we implement a pre-built dispute automation platform, or build a custom system designed around our environment? Institutions should explore whether an off-the-shelf platform or a custom system is the more cost-effective path for resolving disputes at their scale.
Both have legitimate use cases. The benefits of AI depend on whether the chosen system matches the institution’s infrastructure and dispute complexity. The more useful question is which one fits your institution’s specific complexity, infrastructure, and growth trajectory.
Also Read: How to Align AI Capabilities with Business Outcomes
Pre-built platforms work well when:
Where pre-built platforms hit their ceiling:
| Situation | What It Means in Practice |
| Multi-product Complexity | Credit, debit, ACH, and digital payments each operate under different regulatory frameworks. Many platforms perform well in one payment type but lack consistency across others. |
| Integration Depth | Effective dispute resolution requires seamless integration with fraud detection and AML systems. This often depends on API access that pre-built platforms may not adequately support. |
| Explainability Requirements | Compliance and legal teams increasingly require decision-level reasoning and auditability rather than basic activity logs. Most off-the-shelf platforms do not provide this capability by default. |
| Volume Economics | At institutional transaction volumes, per-case pricing models can become cost-prohibitive and negatively impact overall unit economics. |
| Competitive Differentiation | Pre-built dispute management platforms are widely available and commonly used by competitors. Sustainable differentiation in AI-driven dispute management typically requires a solution tailored to specific organizational needs and advantages. |
What a custom-built system enables:
A custom dispute resolution AI for financial institutions is designed around your data infrastructure, your compliance requirements, and your operational workflows from the first architecture session, not inherited from a vendor’s default configuration. The regulatory logic is built in. The integrations are engineered. The governance layer (escalation conditions, autonomy thresholds, documentation standards) is defined by your compliance team and encoded into the architecture, which is where artificial intelligence can support a broader alternative dispute resolution ADR strategy through workflow design rather than abstract legal theory.
This matters most for institutions running complex multis-product dispute environments, operating on legacy core banking infrastructure that standard platforms do not support cleanly, or planning to connect AI powered dispute resolution intelligence into a broader agentic AI strategy spanning fraud detection, KYC, and risk modeling.
It also matters for institutions that have already tried a pre-built platform and discovered that the configuration ceiling is lower than it appeared in the sales process. That ceiling exists in every pre-built tool. The question is whether your institution hits it before or after the operation has been built around it.
Also Read: Which AI Agent Framework Should You Use for Enterprise? LangChain vs AutoGen vs CrewAI
The five-agent architecture, the shared state orchestration layer, the human escalation design, the compliance documentation function built at the point of decision: none of this comes from a configuration screen. It is an engineering outcome that requires precise decisions at every layer of the build, made by people who have built this in production financial services environments before.
People Also Read: Is Your Organization Ready for Enterprise-wide AI Adoption?
The institutions that have deployed multi-agent AI dispute resolution successfully share one starting point: they treated it as a systems integration problem before they treated it as an AI problem. The agents are only as reliable as the data they operate on, the connectors that feed them, and the orchestration layer that coordinates them. The system should improve the administration of justice in a repeatable way, not just automate tasks. Build the AI on a weak data foundation and you get a system that impresses in testing and quietly breaks on live dispute volumes. The foundation work is unglamorous. It is also the most important part.
Related: AI-Ready Data
A production-grade automated dispute resolution system runs on a specific, deliberate technical stack. Ethical considerations have to be designed into that stack from the start, because AI in dispute settings can directly affect fairness, accountability, and trust.
TechAhead builds and delivers these systems for financial services organizations as a development and consulting partner. Every engagement is held to a specific delivery standard:
These are not credentials on a proposal slide. They are the standards the work is held to from the first architecture session through to production deployment.
For institutions ready to move from evaluating agentic AI for dispute resolution to actually scoping a build, the right starting point is a conversation about your infrastructure, your compliance environment, and your dispute volumes. Contact TechAhead to discuss what a production-grade multi-agent dispute resolution system realistically looks like at your scale and what it takes to build it right.

RPA automates fixed steps. A single agent generalizes poorly under complexity. Multi-agent AI dispute resolution assigns each function (triage, evidence retrieval, decision reasoning, documentation) to a specialized agent. That separation is what makes outcomes consistent, defensible, and production-ready at scale, as a form of alternative dispute resolution support rather than a replacement for human judgment.
Yes, but not out of the box. Custom connectors normalize data from legacy core banking platforms before agent development begins. Skip that step and the evidence retrieval function breaks on live records, regardless of how well the AI dispute resolution agents are built.
The triage agent classifies each dispute under Reg E, Reg Z, or card network rules at intake and immediately applies the correct deadlines and documentation requirements from step one. In agentic AI for dispute resolution, compliance is architectural, not a post-resolution checkbox.
They move from evidence gathering to judgment review and exception handling. Automated dispute resolution routes fully assembled cases to humans at decision points requiring regulatory accountability, and human review remains essential in sensitive or ambiguous cases because AI lacks emotional intelligence. Less time on retrieval, more time on the calls that genuinely need a human in the loop.
The decision reasoning agent generates a step-by-step record tied to specific rule citations at the moment of resolution, retrievable on demand during regulatory examination. With multi-agent AI dispute resolution, the audit trail is produced automatically, not reconstructed from memory after the fact, and those explainable outputs matter because black-box recommendations raise fairness concerns.
Each case runs in an isolated state context at the orchestration layer, regardless of concurrent volume. Without this, parallel cases cross-contaminate evidence. The orchestration design in automated dispute resolution banking systems is specifically built to prevent that failure mode before it reaches production scale.
Four phases: workflow audit, connector build and data normalization, agent development with escalation calibration, and phased deployment. The integration layer consistently takes longer than the dispute resolution workflow automation build itself. Teams that underestimate it find out after go-live.
When dispute resolution workflow automation shares state with fraud detection and AML monitoring, patterns in one workflow inform the others in real time. That connected intelligence layer can improve outcomes, but only when governance prevents over-reliance on automated recommendations. That connected intelligence layer is what separates a custom-built AI dispute resolution system from a standalone tool.
We use cookies to ensure our website functions properly, improve performance, and provide a personalized experience. You can choose which types of cookies to allow below.
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Help us understand site traffic and user interactions so we can improve performance and usability.
Enable enhanced functionality and personalization such as language or region preferences.
Used to deliver relevant ads, track campaign performance, and measure advertising effectiveness.