

















 Copy Link
Copy Link Share on X
Share on X Share on Facebook
Share on Facebook Share on LinkedIn
Share on LinkedIn


Always Active
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Build intelligent AI systems that automate decisions, accelerate innovation, and scale business growth.
Design, build, modernize, and scale digital products that drive business growth.
Build secure, scalable, and intelligent platforms that power modern enterprises.
Build intelligent, connected, and autonomous systems that operate in the real world.
Flexible engineering capacity with predictable delivery, ownership, and outcomes.
Uncover the transformative potential of digital and mobile solutions for your industry

 Last Updated: Jul 15, 2026
May 19, 2026
Last Updated: Jul 15, 2026
May 19, 2026  551
551  31 min. Read
31 min. Read



Key Takeaways
Let’s evaluate your readiness and calculate your score in minutes
Most AI systems fail procurement reviews for reasons unrelated to technical capability. The question that blocks deals isn’t about performance metrics or system architecture – it’s about documentation:
“Can you show us your model card and demonstrate complete data provenance?”
The silence that follows costs deals. According to the 2026 Data Security and Compliance Risk Forecast Report, 78% of organizations cannot validate data before it enters AI training pipelines, and 77% cannot trace where their training data originated.
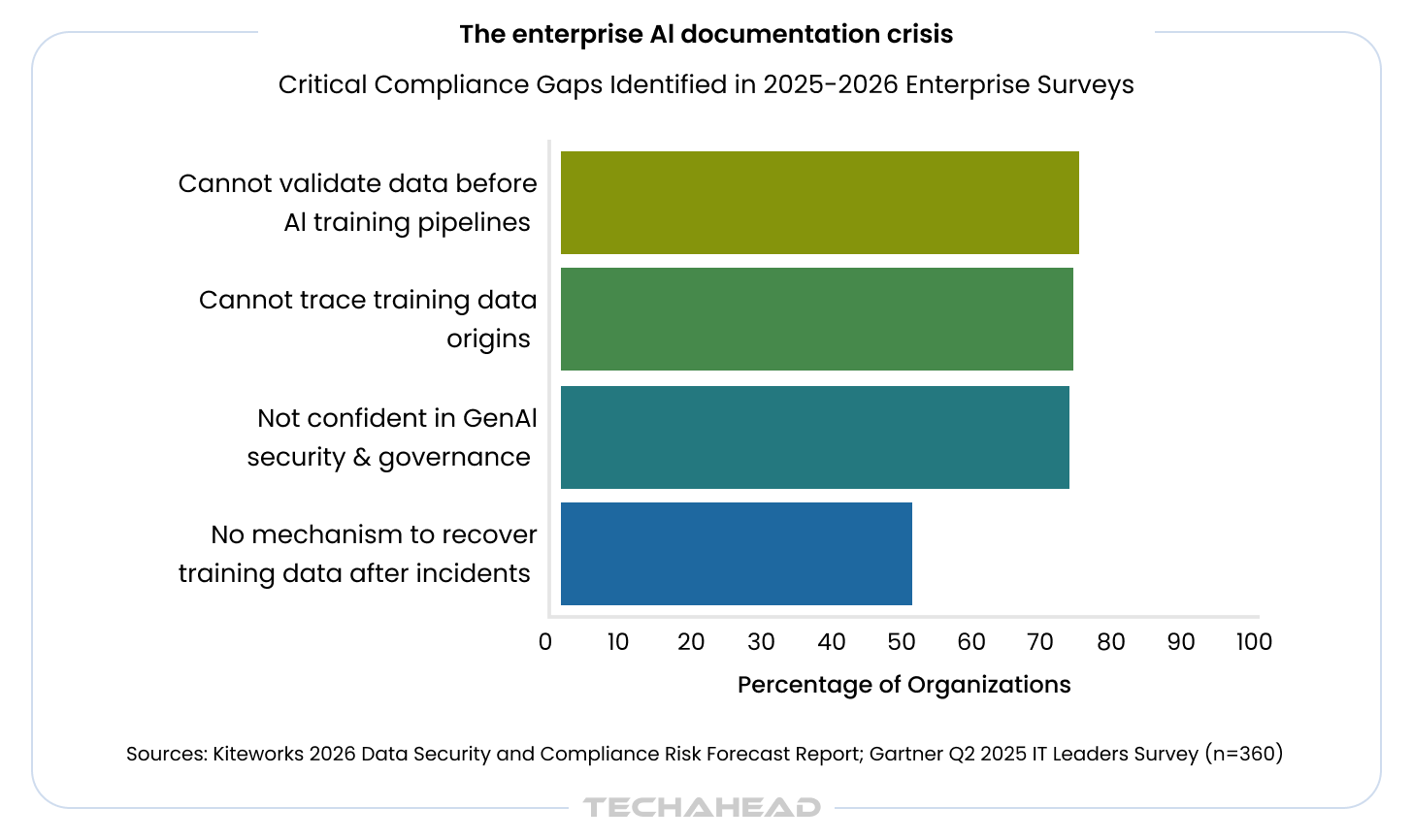
These aren’t edge cases. These are the organizations currently in your competitive pipeline, and most don’t know they have a documentation problem until regulators or customers demand proof – often because limited resources like time, budget, and personnel make compliance especially challenging for small teams.
Unlike a physical product box that lists specifications and details for consumers, AI models often lack such ‘inside the box’ transparency, making it difficult for stakeholders to understand what they are actually deploying. Model cards address this gap by providing clear, accessible documentation. Organizations often cannot validate data before it is used to train AI models, further complicating transparency and compliance.
This guide walks US enterprises through what AI documentation requirements actually mean in practice, how to implement them without drowning in manual work, and what to verify when evaluating development partners who claim compliance readiness.
Must Read: Enterprise AI Compliance & Governance Guide

AI model cards are short documents (typically one to two pages) that present relevant information about AI models in plain language, making complex technical details accessible and understandable for all stakeholders. Model cards serve as a standardized document to improve transparency and accountability across the AI lifecycle.
They disclose key features of the AI model, such as training data, capabilities, and performance metrics, to facilitate understanding among diverse stakeholders. They are also a key tool for responsible AI, promoting transparency and ethical development practices. Alongside data provenance tracking, these tools have moved from voluntary best practices to legal requirements between 2024 and 2026.

With the EU AI Act’s high-risk obligations mandatory from August 2, 2026, organizations in regulated industries such as finance and healthcare can use model cards to help meet compliance and auditability requirements, ensuring transparency and accountability as demanded by evolving industry standards.
Related: Responsible and Ethical AI
Artificial intelligence systems rely on detailed documentation of their technical attributes to ensure transparency, accountability, and compliance with evolving regulations. AI model cards provide this by capturing key information about the model’s architecture, training data, and performance metrics.
What makes model cards different from traditional technical documentation:
Beyond technical transparency, model cards address the broader societal implications of AI deployment. They promote fairness and ethical considerations by documenting how models perform across protected classes and vulnerable populations.
Bonus Read: Private AI for Enterprises
Who relies on model cards:
Through comprehensive and accessible documentation, AI model cards empower stakeholders to make informed decisions, fostering trust and accountability in artificial intelligence systems.
Must read our blog on EU AI Act Compliance Checklist for Software Vendors to know the best practices to hire software developers that take compliance into acute consideration.
The regulatory timeline driving urgency is straightforward. The EU AI Act entered into force on August 1, 2024, with grace periods ending and full enforcement hitting high-risk AI systems in August 2026. For AI used in credit scoring, recruitment, healthcare diagnostics, or insurance underwriting, technical documentation is no longer optional. This reflects a broader world movement toward responsible AI governance and transparency, as global stakeholders align on best practices.
The concept of model cards was first proposed in a 2018 paper as a solution to the lack of documentation for machine learning models deployed in high-stakes contexts. Unlike ad hoc documentation for other models, model cards enable standardized comparison across different machine learning models, supporting transparency and accountability in AI technology. They help organizations account for the development and deployment of their AI systems and meet regulatory requirements.
Must Read: Is Your Organization Ready for Enterprise-wide AI Adoption?
US organizations often assume this only affects European operations. Wrong. If your AI processes data from EU residents or you sell to enterprise clients with European operations, these requirements apply to you. More importantly, US enterprise buyers now demand the same documentation standards in security questionnaires, regardless of where you’re incorporated.
EU AI Act (Annex IV): Mandates structured technical documentation including model purpose, training data sources, performance metrics by demographic group, risk assessments, and human oversight mechanisms. High-risk systems need conformity assessments before market launch.
ISO 42001:2023: The international standard for AI Management Systems requires documented model governance processes. Organizations pursuing certification must demonstrate systematic documentation practices across all AI deployments.
NIST AI Risk Management Framework (RMF): While voluntary, NIST AI RMF’s MAP and MEASURE functions explicitly call for documentation of context, risks, evaluation methods, and results. US federal contractors increasingly reference NIST as baseline expectations.
Sector-specific overlays: Healthcare AI faces HIPAA requirements for PHI de-identification and FDA expectations for AI/ML software as medical devices. Financial services must satisfy SR 11-7 model risk management standards including comprehensive model governance documentation.
Related: How to Make Your Mobile App HIPAA Compliant
The regulatory velocity matters more than any single framework. Compliance Week’s 2026 survey found 83% of organizations already use AI tools, but only 25% have implemented strong governance frameworks. That gap represents the difference between organizations that can demonstrate compliance versus those paying consultants to retrofit documentation after deployment.
Margaret Mitchell, co-creator of the Model Cards framework, states that:
“Model cards are short documents accompanying trained machine learning models that provide benchmarked evaluation in a variety of conditions… [they] also disclose the context in which models are intended to be used, details of the performance evaluation procedures, and other relevant information.”
Recommended: Why Does Enterprise AI Need Audit Trails?
AI model cards serve as standardized documentation artifacts accompanying machine learning models. Think of them as nutrition labels for AI – transparent disclosure of intended use cases, benchmarked evaluation results, model details (including features), and other relevant information such as performance characteristics, known limitations, training data, and ethical considerations.
For example, if a model is designed to analyze a picture or other visual data, the model card should clarify this intended use and caution against misuse for unintended purposes. Model cards present these details to help stakeholders understand the trained machine learning model and its context.
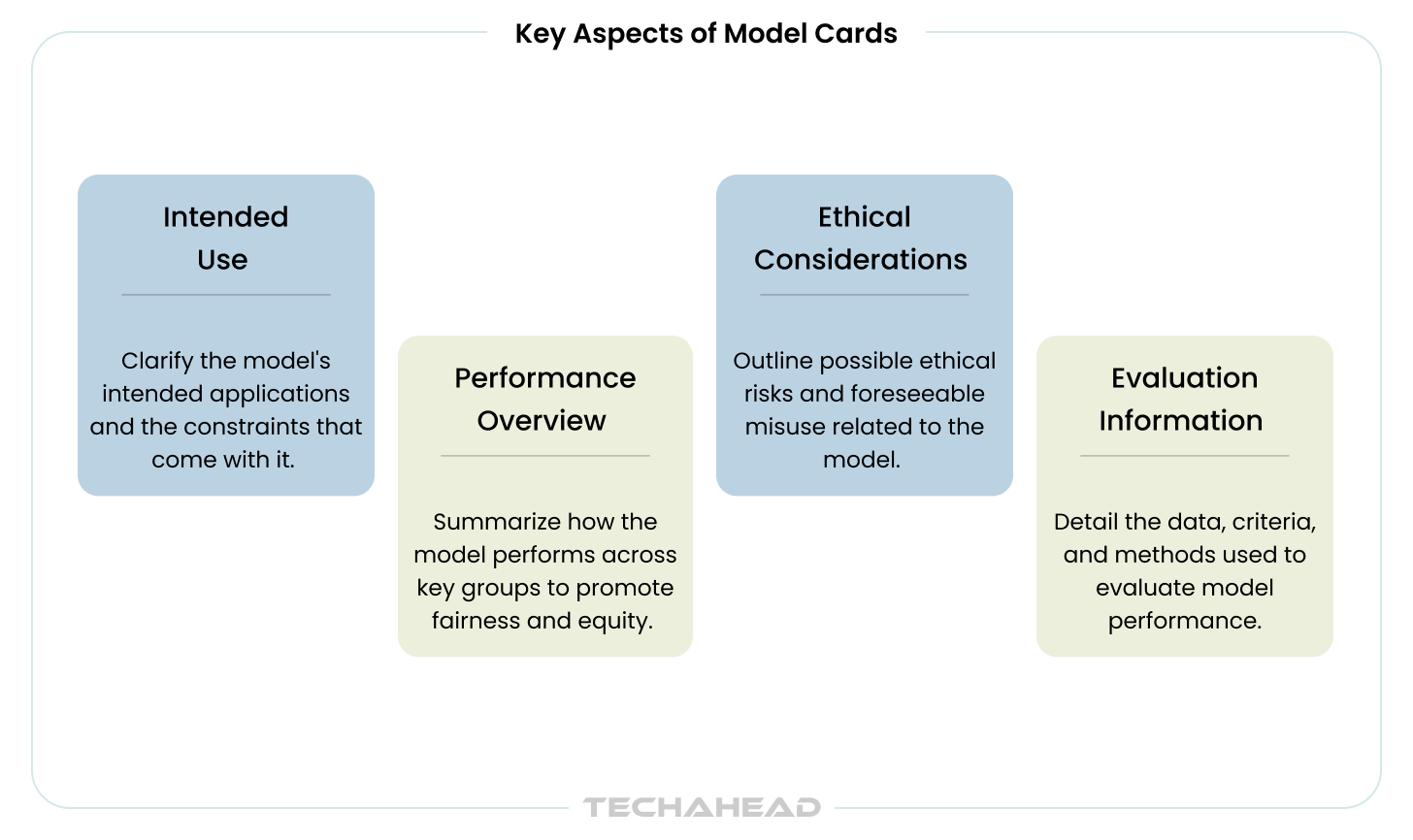
Originally introduced by Mitchell et al. at Google in 2019, model cards have evolved from research papers to regulatory compliance tools. A complete model card template addresses eight core areas that regulators and auditors actually check, including:
For instance, a model with 95% overall accuracy could actually have 99% accuracy for one group and only 70% for another, making disaggregated evaluation essential to reveal these disparities. Disaggregated evaluation also requires intersectional analysis, meaning performance should be tested not just on individual factors like race or gender, but also on combinations of these factors to uncover compounded disparities.
Regulatory frameworks including the EU AI Act and ISO 42001 converge on eight core documentation requirements that enterprises must maintain for high-risk AI systems. These sections form the minimum viable compliance standard across jurisdictions:
Also Read: AI Security Platforms (What Enterprises Should Actually Look For)
Document the model’s primary purpose, target users, and explicitly state out-of-scope applications. Regulators want to see clear boundaries. A credit risk model intended as decision support (not sole decision-making) must state that limitation clearly.
Specify data sources, collection methods, licensing, preprocessing steps, and known quality issues. This is where data provenance requirements start biting. You must prove where your data came from and whether you had rights to use it for model training.
Report accuracy across different demographic groups and operating conditions. The EU AI Act requires performance testing that surfaces disparate impact. A model with 95% overall accuracy but 73% accuracy for a protected class fails compliance.
Identify boundary conditions where the model underperforms. What happens when input data drifts from training distributions? What edge cases produce unreliable outputs? Organizations that document limitations proactively avoid nasty surprises during audits.
Detail fairness metrics, bias testing methodology, and mitigation strategies. For healthcare AI making diagnostic recommendations or finance AI determining creditworthiness, this section determines whether your system survives regulatory review.
Explain where human review happens in the workflow, who can override model decisions, and how you track those interventions. High-risk applications under EU AI Act Article 14 mandate demonstrable human oversight.
Track which base models, fine-tuning runs, and architectural decisions produced this version. When you retrain models, documentation must update in sync. Data lineage tracking connects model versions to the exact training data snapshots used.
Specify update frequency, monitoring metrics that trigger retraining, and who’s responsible for ongoing governance. Static documentation fails the moment you deploy model v2.0 without updating the card.
Recommended: What is AI-Ready Data?
| Regulatory Framework | Core Documentation Focus | Enforcement Timeline |
| EU AI Act (Annex IV) | Technical documentation, conformity assessment, risk management | August 2, 2026 (high-risk systems) |
| ISO 42001:2023 | AI Management System, model governance, quality controls | Certification available now |
| NIST AI RMF | Context documentation, evaluation methods, risk responses | Voluntary (increasingly required for federal procurement) |
| HIPAA (Healthcare) | PHI de-identification, audit trails, clinical validation | Enforced (applies to AI processing health data) |
| SR 11-7 (Finance) | Model risk management, bias testing, backtesting | Enforced (banking/lending AI) |
Organizations treating model cards as one-time documents discover problems during regulatory review. According to experts, the most common failures involve:
TechAhead’s Approach: Our ISO 42001:2023-certified documentation framework generates model cards automatically during development sprints through integrated MLOps pipelines. When clients retrain models, documentation updates in sync rather than requiring manual rewrites six months later. This embedded approach surfaces compliance documentation gaps during code review, not during customer security questionnaires.
Data provenance and data lineage tracking sound similar but solve different problems. Data lineage maps how data flows and transforms across systems. Data provenance tracks proof of origin – where data came from, who collected it, whether it’s trustworthy and legally usable.
Organizations need both. The EU AI Act Article 50, enforceable from August 2, 2026, requires machine-readable disclosure for AI-generated content. Without provenance infrastructure, you can’t prove compliance even if your AI performs flawlessly.
Building a single AI model might touch 15-30 data sources. Customer records from your CRM, transaction logs from payment systems, demographic data from third-party vendors, publicly scraped datasets, and historical performance data all merge into training pipelines. Now document the provenance chain for each source:
The complexity compounds when data quality issues emerge. If a dataset violates GDPR or was collected without consent, you need to identify exactly which models are “poisoned” by that data. Without data lineage tracking, that investigation takes weeks and often fails to provide definitive answers.
Healthcare organizations using AI for clinical decision support face layered complexity. HIPAA requires Protected Health Information de-identification before training data enters models. But demonstrating compliant de-identification demands documented provenance showing:
Source verification: Which patient records contributed to the training set, with audit logs proving authorized access
De-identification methodology: Exactly how you removed or masked identifiers, with evidence that the process met Safe Harbor or Expert Determination standards
Transformation tracking: Every preprocessing step between raw PHI and training-ready data, ensuring no reidentification risk emerges through data linkage
Model-to-data mapping: Which training data versions produced which model versions, allowing rapid response if data quality issues surface post-deployment
Healthcare AI data provenance requirements extend beyond regulatory compliance to clinical governance. Healthcare technology entrepreneurs must construct AI architectures that withstand FDA scrutiny, provide comprehensive audit trails for clinical decisions, and maintain detailed provenance records tracing every data transformation back to source.
Financial services AI determining creditworthiness faces Fair Lending requirements demanding transparency about what data influenced decisions. When a model denies credit to a protected class at higher rates, regulators will demand proof your training data didn’t encode historical discrimination.
Also Read: Real Time Fraud Detection
Documenting provenance for credit models means tracking not just what data you used, but why you believed it was appropriate, unbiased, and legally usable. That requires:
The documentation burden explains why compliance professionals estimate some development firms now charge 20-30% more to reflect certification costs and engineering overhead. Organizations without provenance infrastructure built in discover they’re funding their development partner’s learning curve.
Deepak Sinha, Chief Technology Officer at TechAhead, explains the implementation challenge:
“In 2026, Data Lineage is the essential first step for high-risk AI compliance. You need to be able to map the journey of a piece of data from its source to the moment it influences a model’s weights. Transparency is a technical requirement that sits at the core of legal compliance.”
TechAhead’s Infrastructure: Our SOC 2 Type II-certified monitoring infrastructure implements automated data lineage tracking from ingestion through deployment. For a fintech client’s credit decisioning AI, we architected provenance systems capturing data source, collection timestamp, preprocessing transformations, and consent status for every training record. When auditors requested evidence, the client produced complete lineage documentation within hours, not weeks of investigation.

Creating your first model card template doesn’t require a dedicated AI documentation team. Most organizations assign authorship across three existing roles: the ML engineer who built the model, the data scientist who designed evaluation, and the compliance/legal lead who understands regulatory requirements. In smaller organizations, one person might wear multiple hats.
The challenge isn’t creating the initial card. It’s maintaining accuracy as models evolve, training data changes, and regulatory requirements expand. Here’s a practical implementation framework that scales from your first AI deployment to enterprise-wide model governance.
Recommended: Building an Enterprise AI Roadmap in 90 Days
Many platforms and resources now offer free access to model card templates or compliance update tools, making it easier for organizations to get started and stay current without additional cost.
Before documenting individual models, catalog every AI system running in your organization. Over half of organizations lack systematic AI inventories, which means they can’t identify what needs documentation.
Build an inventory capturing: system name and business purpose, risk classification under relevant frameworks, model type and deployment architecture, data sources feeding the system, responsible parties and review cadences, current production status.
This inventory becomes your model governance foundation. Without it, you’re documenting in the dark, unsure which systems face high-risk obligations versus minimal documentation requirements.
Organizations face a fork: manually author model cards in Google Docs or implement automated generation through MLOps integration. Manual documentation costs less upfront but fails spectacularly at scale.
Manual documentation works when:
Automated documentation becomes mandatory when:
You likely have documentation fragments scattered across tools. The first model card template population pulls these together rather than creating from scratch:
Model overview: Extract from your project charter or initial requirements document
Training data: Pull from data engineering pipelines, ETL logs, or vendor contracts specifying data sources
Performance metrics: Export from your model evaluation scripts, training logs, or experiment tracking tools like MLflow
Ethical considerations: Reference bias testing reports, fairness analysis, or explainability studies already completed
Human oversight: Document the approval workflow and override capabilities already implemented in your production system
The documentation exists. It’s just fragmented across Jira tickets, Slack threads, Python notebooks, and PowerPoint decks. Your first model card consolidates rather than creates.
Static documentation dies the moment you deploy model v2.0. Establish clear triggers requiring model card updates:
Assign explicit ownership using RACI (Responsible, Accountable, Consulted, Informed) frameworks. Who updates the card when models retrain? Who reviews accuracy before publication? Who approves changes affecting compliance documentation?
Organizations implementing ISO 42001 document these ownership structures as part of their AI Management System. The framework forces operational clarity about who maintains documentation, preventing the “everyone’s responsible so nobody’s responsible” trap.
The gold standard: model cards live in your model registry alongside the models themselves, version-controlled and updated automatically when models deploy. When your ML engineer commits code to retrain a model, the documentation pipeline triggers, prompting updates to affected sections.
This integration pattern prevents documentation drift, where your model card describes v1.0 but production runs v3.2. Version-controlled cards linked to deployment pipelines ensure documentation accuracy without manual tracking overhead.
Vikas Kaushik, Founder & CEO of TechAhead, reflects on client implementation patterns:
“We see this pattern repeatedly with enterprise AI teams: they start with manual documentation in spreadsheets or wikis, and within weeks it’s hopelessly out of sync with production models. The solution isn’t better documentation discipline – it’s treating model cards as infrastructure. When we architect AI governance platforms for clients, model card generation is baked into the deployment pipeline. Data scientists can’t push a retrained model to production without completing the impact assessment and updating performance metrics.”
When evaluating software development firms for AI projects, AI documentation requirements capability separates partners who understand 2026 compliance from those learning on your budget. Most organizations discover their development team’s documentation gaps six months into a project – far too late to change course without massive costs.
Watch for these deal-breakers during RFP evaluation and technical discussions:
“We’ll document everything at the end of development”
This reveals fundamental misunderstanding. EU AI Act compliance requires design-stage documentation capturing architectural decisions and data source selections as they happen. You cannot retrofit this six months later with any credibility.
Cannot produce example model cards from previous projects
If they’ve built AI systems for other clients, they should have anonymized model card templates demonstrating their documentation methodology. Absence means you’re funding their first attempt.
Vague about data provenance tracking
Ask specifically: “How do you track training data lineage from source to model?” Competent partners describe automated systems. Firms without infrastructure mention “spreadsheets” or “documentation after model training.”
No mention of automated documentation generation
Partners treating model cards as separate from engineering workflows will burden you with manual documentation overhead that scales poorly as AI deployment grows.
Cannot explain their quality management system
ISO 42001 certification requires documented quality management systems for AI development. Partners without formal QMS can ‘t demonstrate systematic model governance to regulators.
Structure your vendor interviews around proof of capability, not promises. Request specific evidence:
Documentation Infrastructure
“Show us your model card template and explain how it populates during development.” Look for answers referencing MLOps pipelines, automated metadata capture, and version control integration.
Data Provenance Systems
“Walk us through how you track data lineage for a healthcare AI project.” Competent healthcare AI partners describe field-level tracking, consent management integration, and PHI de-identification verification built into ETL processes.
Previous Compliance Experience
“Provide client references who launched high-risk AI in EU markets with your documentation support.” Verify these references completed conformity assessments, not just development work.
Update Mechanisms
“When you retrain models, how do documentation and compliance artifacts stay synchronized?” The answer reveals whether they’ve thought through ongoing governance or just initial deployment.
Certification Evidence
“Share your ISO 42001:2023 and SOC 2 Type II certificates.” Certifications prove third-party auditors verified their AI governance infrastructure meets standards, not just internal claims.
| Capability Area | What to Verify | Green Flags | Red Flags |
| Model Cards | Documentation methodology | Automated generation during sprints, version-controlled templates | Manual creation at project end, generic internet templates |
| Data Provenance | Lineage tracking systems | Automated source tracking, consent management integration | Spreadsheet-based tracking, “we’ll document sources” |
| Quality Management | ISO 42001 certification | Current certificate with AI-specific controls | “Working toward certification” without audit dates |
| Compliance Experience | Previous high-risk AI launches | Client references with completed conformity assessments | No EU market launches, “we’re learning compliance” |
| Update Mechanisms | Documentation maintenance | Pipeline integration updating cards automatically | Manual quarterly reviews, documentation separate from code |
David Park, VP of Engineering at an enterprise software company, explains vendor selection criteria:
“We shortlisted five development partners for our AI initiative. Four had similar technical capabilities, but only one could demonstrate their documentation infrastructure in a live system. They showed us how model cards auto populated from training runs, how data lineage tracked back to source systems, and how their quality gates prevented deployment without complete documentation. That operational proof won the contract.”
TechAhead’s Proven Framework: Our clients don’t discover documentation gaps during customer security reviews because we surface them during initial requirements workshops. Before any development begins, we conduct risk classification sessions mapping AI features to Annex III categories and regulatory obligations. This pre-development compliance scoping identifies technical documentation requirements alongside functional specifications, ensuring model cards, data provenance tracking, and audit trails integrate into architecture from day one rather than bolting on months later at 4-5x the cost.
The direct penalties for non-compliant AI grab headlines – 35 million or 7% of global revenue under EU AI Act. But the operational costs of retrofit documentation dwarf regulatory fines for most organizations.
Retrofit documentation typically costs 4-5x more than embedded compliance because engineers must reverse-engineer decisions made months earlier. Data scientists who trained models can’t recall why they selected specific hyperparameters. No one documented which data sources fed which model versions. The team that built it moved to other projects.
Development firms with mature compliance infrastructure help their clients close enterprise deals 40% faster because buyers receive compliance documentation during security reviews instead of promises to “handle it later.” When your competitor provides audit-ready model cards and you’re still figuring out data lineage, you lose the deal regardless of technical superiority.
Launch delays compound costs. Every month you can’t sell in EU markets because AI model cards or conformity assessments aren’t complete represents revenue you never recover. For enterprise software companies where EU markets represent 30-40% of total addressable market, documentation blockers can sink entire product launches.
Investor diligence failures create existential risk. If you’re raising capital, investors conducting technical due diligence discover compliance gaps. This either tanks your valuation or blocks the round entirely until remediated. The due diligence checklist increasingly includes “Show us your model governance infrastructure” alongside revenue and growth metrics.

AI model cards and data provenance documentation work when they’re engineering infrastructure, not compliance theater completed after development. Organizations treating documentation as legal paperwork discover it provides no operational value while failing to satisfy regulators.
The operational benefits of embedded documentation extend beyond regulatory compliance:
When models behave unexpectedly, audit trails and data lineage tracking help teams identify root causes in hours instead of weeks. Was it algorithm changes, training data drift, or pipeline errors?
New engineers onboarding to AI projects use model cards to understand system behavior, limitations, and architectural decisions without hunting through Slack history.
When third-party models underperform, documented baselines and performance expectations provide concrete evidence for vendor accountability discussions.
Organizations with documentation infrastructure ship new models faster because compliance reviews become checkboxes, not months-long documentation archaeology projects.
The 2026 EU AI Act compliance deadline forces a choice: build documentation infrastructure that enables AI at scale, or retrofit compliance under regulatory pressure after August. Organizations taking the embedded approach discover documentation becomes competitive advantage rather than overhead.
Your AI strategy succeeds or fails based on whether you can prove your systems work safely and legally. Model cards, data provenance, and technical documentation aren’t obstacles to innovation, they’re the infrastructure that lets innovation scale beyond proofs-of-concept into production systems enterprises actually buy.
TechAhead’s ISO 42001:2023 and SOC 2 Type II certifications demonstrate third-party audited proof that our AI governance framework meets the highest standards available. Since 2009, we’ve launched 2,500+ platforms for clients including AXA, American Express, Audi, Starbucks, The Healthy Mummy, Plunge, and RaspberryFX across regulated markets where compliance documentation determines market access, not just technical performance. Our ISO 27001:2022 certifications further validate our commitment to security and quality management in AI-enabled medical devices and healthcare platforms.
What sets our model card implementation apart:
As Claude & OpenAI Services Partner and holder of AWS Advanced Tier Partner status, we architect AI systems where governance scales alongside innovation. Our 240+ engineers embed compliance controls into CI/CD workflows, making documentation a deployment gate rather than afterthought that surfaces during audits.
Ready to implement AI documentation infrastructure that accelerates deployment instead of blocking it? Contact TechAhead to discuss how our certified governance framework delivers compliant, market-ready AI products without the retrofit costs and launch delays plaguing organizations that treated documentation as an afterthought.
Start with eight core sections: model details, intended use, training data sources, performance across demographic groups, limitations, ethical considerations, testing methodology, and human oversight. Use standardized templates and automate from your MLOps pipeline. Model cards need version control. Updates trigger whenever systems undergo retraining or architectural changes.
Model cards document the AI system: architecture, performance, limitations, deployment guidelines. Datasheets document training data: provenance, collection methodology, biases, legal basis. They’re complementary. Your model card references the dataset; the datasheet provides detailed data provenance information. Under EU AI Act Annex IV, high-risk systems require both.
Update model cards whenever you retrain with new data, modify architecture, deploy to new use cases, or monitoring reveals performance drift or bias. ISO 42001 and EU AI Act require version control. Quarterly reviews are minimum for high-risk systems, but meaningful changes trigger immediate updates regardless of schedule.
Yes, but it’s resource-intensive and harder the longer you wait. Reconstruct training data sources, testing logs, and architectural decisions from existing documentation. Interview original developers while knowledge remains accessible. For systems without data lineage tracking, conduct new bias testing and performance evaluations. Retrofitting governance explains why August 2026 compliance costs more for late movers.
EU AI Act mandates model cards for high-risk systems only, but document all deployed models proportionally. High-risk systems need exhaustive technical documentation matching Annex IV. Low-risk internal automation needs abbreviated summaries. Risk classification itself requires documentation, and procurement teams increasingly demand model cards even for low-risk systems. Document everything; vary depth, not practice.
Request documented data lineage showing origin, collection methodology, and legal rights. Ask for contractual assurances and audit rights. Verify they can explain data’s journey from source to model weights. Red flags: vague “publicly available data” answers, refusal to specify datasets, or claims data provenance is proprietary. If they won’t disclose, walk away.
Absolutely. It’s the only scalable approach. Integrate model card generation as deployment gates. Data scientists can’t push retrained models without completing impact assessments. Pull metrics from MLOps, bias testing from data quality monitoring, architecture from version control. Automated model cards transform compliance documentation from overhead into engineering infrastructure preventing undocumented production deployments.
Ask specifics: Can you provide model cards for systems you’ll build? How do you document data provenance throughout the AI lifecycle? Do you maintain ISO 42001 or SOC 2 certification? Request sample technical documentation from previous projects. Verify they understand EU AI Act Annex IV if you operate in regulated sectors. Compliance-ready partners demonstrate it with artifacts.
ISO 42001 is the international AI Management Systems standard (ISO 27001 for AI governance). It provides certifiable framework covering risk management, data governance, transparency, and human oversight. While voluntary, 60-70% of EU AI Act documentation maps to ISO 42001 controls. Enterprise procurement teams now add “ISO 42001 certified or roadmap” clauses to vendor questionnaires.
Single high-risk model with existing documentation: 2-4 weeks. Entire portfolio without governance infrastructure: 4-8 months minimum (longer if reconstructing data lineage retroactively). Timeline includes templates, team training, CI/CD integration, and bias testing. Organizations starting now for August 2026 have runway. Those starting Q2 2026 will scramble. AI documentation requirements aren’t negotiable; only timing is.
Let’s evaluate your readiness and calculate your score in minutes
We use cookies to ensure our website functions properly, improve performance, and provide a personalized experience. You can choose which types of cookies to allow below.
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Help us understand site traffic and user interactions so we can improve performance and usability.
Enable enhanced functionality and personalization such as language or region preferences.
Used to deliver relevant ads, track campaign performance, and measure advertising effectiveness.