

















 Copy Link
Copy Link Share on X
Share on X Share on Facebook
Share on Facebook Share on LinkedIn
Share on LinkedIn


Always Active
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Build intelligent AI systems that automate decisions, accelerate innovation, and scale business growth.
Design, build, modernize, and scale digital products that drive business growth.
Build secure, scalable, and intelligent platforms that power modern enterprises.
Build intelligent, connected, and autonomous systems that operate in the real world.
Flexible engineering capacity with predictable delivery, ownership, and outcomes.
Uncover the transformative potential of digital and mobile solutions for your industry

 Last Updated: Jun 18, 2026
Jun 8, 2026
Last Updated: Jun 18, 2026
Jun 8, 2026  324
324  14 min. Read
14 min. Read



Key Takeaways
Let’s evaluate your readiness and calculate your score in minutes
AI agents don’t just respond: They reason, plan, act, and learn.
Behind every capable agent is at least one large language model doing the cognitive heavy lifting. But here’s what most people get wrong: they treat “LLM” as a monolithic category.
It isn’t!
The reality is more architectural.
A GPT-class model excels at contextual generation but stumbles on multi-step planning.
While a Large Reasoning Model (LRM) handles deliberate problem decomposition but is computationally expensive for lightweight edge tasks.
On the other hand, a Small Language Model (SLM) runs efficiently on a hospital tablet with no cloud dependency, but can’t orchestrate the complex workflow a Large Action Model (LAM) can.
We need to understand that modern AI agents are composite systems.
They route tasks across specialized LLM types, each engineered for distinct cognitive functions. Understanding these types isn’t just academic or theoretical, because it directly determines what architecture you choose when building production AI agents.
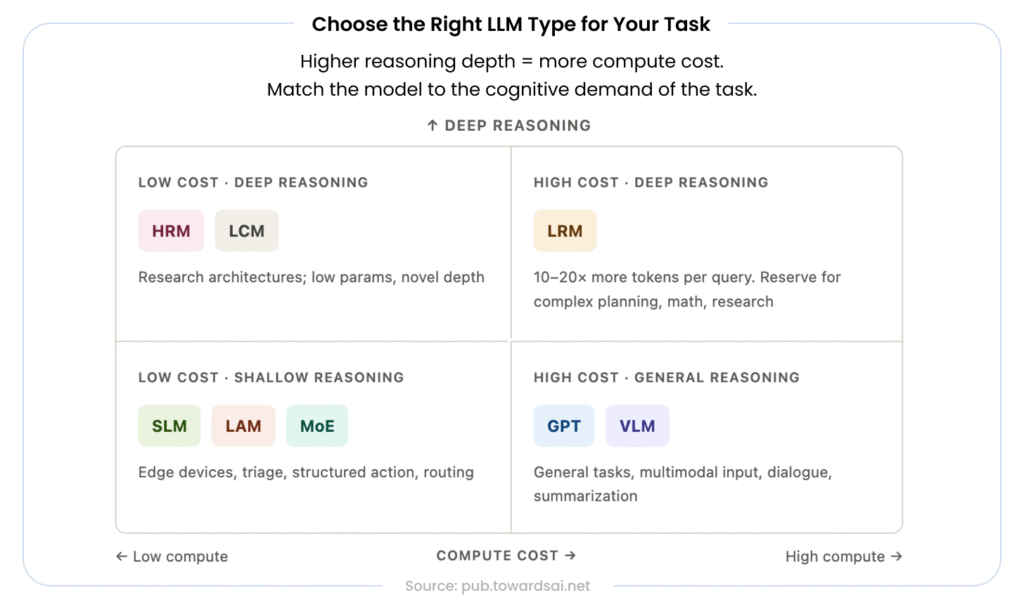
This blog breaks down 8 LLM types powering modern AI agents: what each one is, how it works architecturally, where it performs best, and which real models exemplify it.

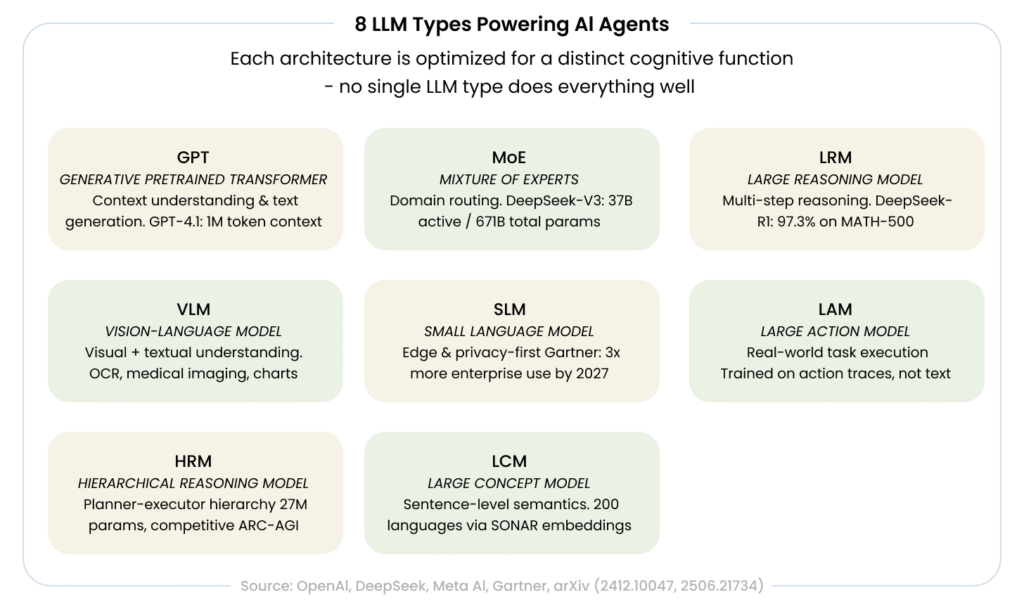
| LLM Type | Full Name | Primary Function | Best For |
| GPT | Generative Pretrained Transformer | Context understanding & text generation | General reasoning, summarization |
| MoE | Mixture of Experts | Routing to specialized sub-models | Efficiency & scalability |
| LRM | Large Reasoning Model | Multi-step reasoning & self-verification | Complex problem decomposition |
| VLM | Vision-Language Model | Visual + textual understanding | Image/video analysis |
| SLM | Small Language Model | Lightweight, low-latency tasks | Edge devices, cost-sensitive deployments |
| LAM | Large Action Model | Tool use & task execution | Autonomous agentic workflows |
| HRM | Hierarchical Reasoning Model | Planner-executor hierarchy | Structured decision-making |
| LCM | Large Concept Model | Concept-level semantic understanding | Abstract reasoning & knowledge discovery |
Generative Pretrained Transformer
GPT models are the foundation layer of modern AI. Pretrained on vast corpora using self-supervised learning, they develop rich contextual representations before fine-tuning shapes them for specific tasks. The transformer architecture, built on self-attention mechanisms, enables GPT models to model long-range dependencies in text, making them exceptional at understanding context and generating coherent, nuanced responses.
In agentic workflows, GPT models handle the generalist workload: synthesizing information, interpreting user intent, generating structured outputs, and managing conversational continuity. GPT-4.1, released in April 2025, supports a 1-million-token context window and demonstrates significant improvements in instruction-following and coding tasks: Key capabilities for agentic use. OpenAI’s Agents API enables GPT models to call tools, hand off tasks between agents, and manage state across complex multi-step workflows.
Use cases in AI agents: General-purpose reasoning, summarization, multi-turn dialogue, code generation, and structured output parsing.
Real models: GPT-4, GPT-4o, GPT-4.1, GPT-4.5
Mixture of Experts
Where standard dense transformer models activate all parameters for every input token, Mixture of Experts models are selective. An MoE architecture contains multiple “expert” sub-networks, but a learned gating mechanism routes each token to only the most relevant subset, typically 2 out of N experts per token. This means MoE models have a large total parameter count but low active parameter count per forward pass.
Popular LLMs (Source)
The efficiency gains are significant. A 671-billion-parameter MoE model like DeepSeek-V3 activates only 37 billion parameters per token, delivering performance comparable to dense models at a fraction of the compute cost. DeepSeek-V3 was trained for approximately $5.5 million, dramatically undercutting comparable dense model training costs.
For AI agents, MoE enables the kind of domain-specific specialization that generalist models can’t efficiently provide. Medical knowledge, legal reasoning, and code generation can each be routed to specialized experts without bloating inference costs.
Use cases in AI agents: Multi-domain task routing, knowledge-intensive applications, cost-efficient large-scale deployments.
Real models: DeepSeek-V3, Mixtral 8x7B, Mixtral 8x22B, Google’s Gemini (partially MoE)
Large Reasoning Model
Large Reasoning Models represent a qualitative shift in how AI systems handle complex problems. Where standard LLMs generate responses in a single forward pass, LRMs engage in extended chain-of-thought reasoning: decomposing problems, exploring intermediate steps, self-verifying, and backtracking before committing to a final answer.
DeepSeek-R1 demonstrated that reinforcement learning (specifically GRPO) applied to reasoning traces could produce chain-of-thought behavior without requiring expensive supervised fine-tuning on human-annotated reasoning data. On the AIME 2024 math benchmark, DeepSeek-R1 achieved 79.8% pass@1, matching OpenAI o1. On MATH-500, it scored 97.3%.
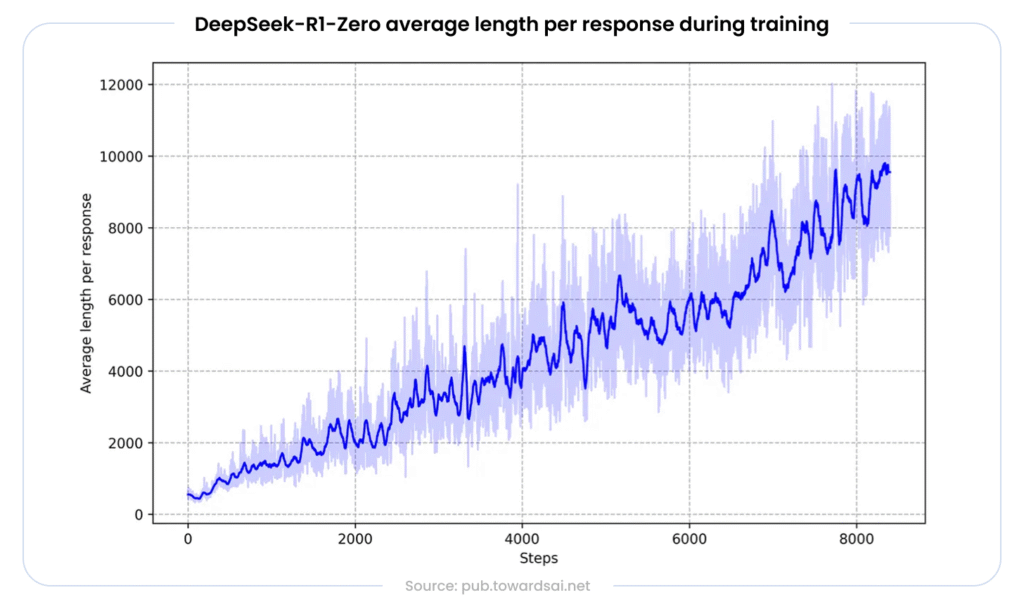
The tradeoff is compute. LRMs generate significantly more tokens per query, sometimes 10-20x more than a standard completion, due to their extended thinking traces. This makes them inappropriate for latency-sensitive or high-volume lightweight tasks, but essential for plan design, multi-step problem solving, and agentic tool use that requires deliberate verification.
Use cases in AI agents: Complex plan design, multi-step mathematical reasoning, scientific research, code debugging with reflection, tool orchestration.
Real models: DeepSeek-R1, OpenAI o1, OpenAI o3, Claude 3.5 Sonnet (reasoning mode), Qwen QwQ-32B
Vision-Language Model
Vision-Language Models extend transformer architectures beyond text by fusing visual encoders (typically based on CLIP or ViT) with language decoders. The result: models that understand, reason about, and generate text grounded in visual input: Images, charts, screenshots, documents, or video frames.
The architectural integration happens at the embedding level. Visual tokens from the image encoder are projected into the same semantic space as text tokens, allowing the language model to attend to both modalities simultaneously. DeepSeek-VL2, with a 4.5B parameter VoE (Vision-of-Experts) architecture, uses dynamic tiling to process high-resolution images and achieves state-of-the-art results on OCR, chart understanding, and visual question answering benchmarks.
For AI agents operating in the real world, browsing the web, reading documents, analyzing medical images, or interpreting manufacturing diagrams, VLMs are non-negotiable. They close the gap between digital visuals and actionable understanding.
Use cases in AI agents: Medical image analysis, document OCR and understanding, web browsing agents, equipment monitoring, and visual QA.
Real models: GPT-4V, GPT-4o, Gemini 1.5 Pro, DeepSeek-VL2, LLaVA-1.6, Claude 3 Opus
Small Language Model
Small Language Models occupy a critical niche: powerful enough for meaningful language tasks, small enough to run on-device or in resource-constrained environments. SLMs range from hundreds of millions to a few billion parameters, achieved through a combination of architectural efficiency, quantization (reducing weight precision from FP32 to INT4 or INT8), knowledge distillation from larger teacher models, and pruning of redundant weights.
Small Language Models (Source)
The strategic case for SLMs is compelling. Gartner predicts that by 2027, organizations will use task-specific SLMs three times more than general-purpose LLMs for enterprise AI deployments. The drivers: data privacy (on-premise inference with no cloud dependency), latency (sub-100ms responses for real-time applications), and cost (inference costs 10-100x lower than frontier models).
Meta’s Llama 3.2 1B and 3B models are designed to run on mobile devices, achieving competitive performance on instruction-following and reasoning benchmarks relative to their size. Microsoft’s Phi-4-mini (3.8B parameters) surpasses models 5x its size on math and coding tasks through targeted training data curation.
Use cases in AI agents: On-device healthcare triage, legal contract pre-screening, customer support routing, IoT and edge device applications, privacy-sensitive enterprise workflows.
Real models: Llama 3.2 1B/3B, Microsoft Phi-4-mini, Google Gemma 2 2B, Apple OpenELM
Source: TechAhead AI Team
Large Action Model
Large Action Models mark the boundary between AI that understands and AI that does. Where LLMs generate text descriptions of actions, LAMs are trained to generate executable action sequences: API calls, UI interactions, system commands, workflow triggers, and verify their outcomes.
The architectural distinction matters. LAMs are typically built on top of LLM foundations but fine-tuned on action traces: sequences of observations, decisions, tool calls, and success/failure signals. This trains the model to reason about preconditions, sequence dependencies, error handling, and goal verification, not just the next token.
Microsoft’s UFO (UI-Focused Agent) framework for Windows OS agents demonstrates LAM principles: the agent perceives the current screen state (via VLM), plans a sequence of UI actions, executes them, and verifies goal completion: All in a closed loop. Research from arXiv:2412.10047 formalizes LAMs as a framework separating action generation from text generation, with dedicated training pipelines for action-grounded tasks.
Use cases in AI agents: Windows/web OS agents, automated software testing, RPA (robotic process automation) replacement, API orchestration, multi-step business workflow execution.
Real models: Microsoft UFO agent, Adept ACT-1, xLAM (Salesforce), various fine-tuned Llama variants for tool use
Hierarchical Reasoning Model
The Hierarchical Reasoning Model is one of the most architecturally novel entries on this list. Proposed in a 2025 arXiv paper, HRM introduces a two-module recurrent architecture: a slow, high-level planning module that processes abstract goals and strategies, and a fast, low-level execution module that handles detailed computational steps. These two modules operate interdependently; the planner sets the direction, the executor handles the implementation, and they iterate.
The key result: a 27-million-parameter HRM scored competitively on the ARC-AGI benchmark, a test designed to measure abstract, general reasoning, without any chain-of-thought supervision data. This is significant because it demonstrates emergent hierarchical reasoning from architecture alone, rather than from prompted reasoning strategies.
For AI agents, HRM’s architecture maps naturally onto complex decision-making workflows: a high-level agent that decomposes a goal into subgoals, paired with a low-level agent that executes each subgoal efficiently. The separation of planning and execution depth allows significantly more computational depth than flat transformer architectures.
Use cases in AI agents: Complex logistics optimization, puzzle solving, multi-step planning tasks, structured workflow decomposition, ARC-style abstract reasoning.
Real models: HRM (27M parameter research model, arXiv:2506.21734), architectural inspiration for hierarchical multi-agent systems.
Large Concept Model
Meta AI’s Large Concept Model represents the most fundamental architectural departure from the standard LLM paradigm. Standard LLMs operate at the token level: they predict the next token in a sequence, one at a time. LCMs operate at the concept level, specifically, at the sentence level, using Meta’s SONAR embedding space, which encodes semantic meaning across 200 languages and 57 speech domains into a unified 1024-dimensional vector.
Source: TechAhead AI Team
Instead of predicting tokens, LCM predicts the next concept embedding, a semantic unit representing a full sentence or idea. This enables language-agnostic reasoning (the same conceptual processing regardless of whether input is in English, Hindi, or Swahili), better long-context coherence (because each step covers a full idea rather than a token), and reduced computational complexity for long-form generation.
The architecture uses a transformer backbone with diffusion-based generation for smooth sampling across the continuous embedding space, plus quantized discrete variants for efficiency. LCM is open-sourced on GitHub under facebookresearch/large_concept_model.
For AI agents, LCM’s promise is in abstract reasoning, knowledge discovery across languages, and creative ideation, tasks where semantic relationships matter more than token-level precision.
Use cases in AI agents: Cross-lingual knowledge synthesis, long-document reasoning, creative and conceptual planning tasks, and multilingual enterprise agents.
Real models: LCM (Meta AI, open-sourced), SONAR-based architectures

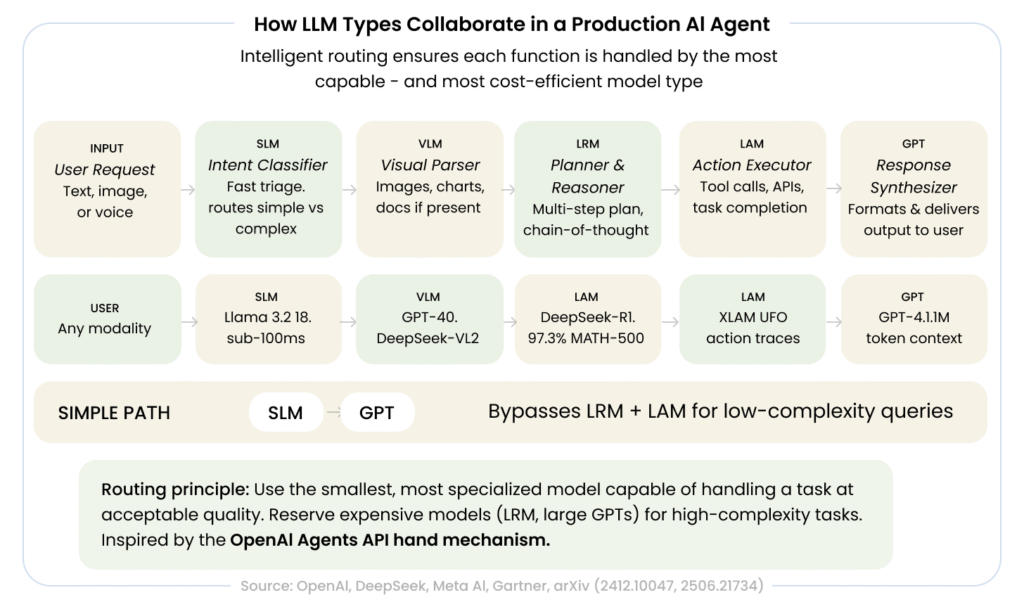
Modern production AI agents rarely rely on a single LLM type. The architecture that’s emerging across enterprise deployments, research systems, and developer platforms is hybrid and hierarchical.
A representative pattern: an LRM handles planning and goal decomposition at the top level. A LAM translates those plans into executable action sequences. A VLM processes any visual inputs, screenshots, documents, and camera feeds. SLMs handle high-volume, latency-sensitive preprocessing tasks. GPT-class models manage user-facing dialogue and output synthesis.
OpenAI’s Agents framework formalizes this with its handoff mechanism: specialized agents (each powered by different model types or configurations) can transfer tasks to each other based on capability matching. This is essentially runtime MoE logic applied at the agent level rather than the model level.
The routing principle is consistent: use the smallest, most specialized model capable of handling a task at acceptable quality. Reserve expensive, capable models (LRMs, large GPTs) for high-complexity tasks. Route simple classification, triage, and extraction tasks to SLMs. This architecture minimizes cost and latency while maximizing capability where it matters.
Healthcare: SLMs for on-device patient triage (HIPAA-compliant, no cloud exposure); VLMs for radiology image analysis and medical chart interpretation; LRMs for differential diagnosis reasoning support.
Finance: LRMs for multi-step investment analysis and risk scenario planning; LAMs for automated trade execution and regulatory reporting workflows; MoE for routing domain-specific compliance and market data queries.
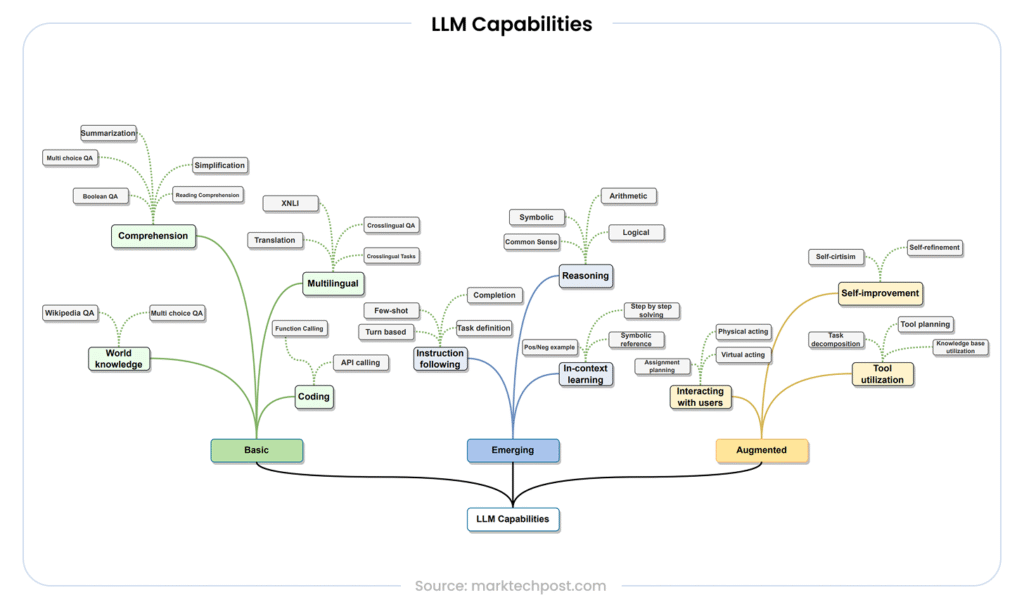
LLM Capabilities (Source)
Manufacturing: VLMs for equipment repair manual interpretation and defect detection; HRMs for production line optimization and logistics path planning; SLMs for real-time sensor data triage on edge devices.
Customer Service: SLMs for intent classification and ticket routing; GPT models for response generation and summarization; LAMs for automated resolution workflows (order changes, refund processing).
Research & Development: LCMs for cross-lingual literature synthesis; LRMs for hypothesis generation and experimental design; MoE for routing queries across domain-specific scientific knowledge bases.
Trends driving the field:
The shift from general-purpose to task-specific models is accelerating. Gartner’s 2027 SLM projection reflects a broader enterprise pattern: organizations want models they can own, control, and deploy efficiently, not solely frontier API dependencies. HRM architectures may represent a genuine step toward the kind of multi-level cognitive processing associated with AGI-class systems. LCM’s semantic-level processing could fundamentally change how agents handle multilingual and cross-domain reasoning.
Challenges that remain real:
LRMs generate significantly more tokens per inference, increasing cost and latency, “overthinking” on simple tasks is a documented failure mode. LCM is early-stage: Meta’s open-source release is promising, but production agentic use cases are still being validated. LAMs face significant challenges in real-world deployment: handling unexpected UI states, error recovery, and safety guardrails for irreversible actions. HRM remains primarily a research architecture with limited production deployment examples.
The era of “one LLM for everything” is giving way to specialized architectures designed for specific cognitive functions. GPTs handle generalist reasoning. MoE models deliver efficiency at scale. LRMs reason deliberately. VLMs interpret visual context. SLMs run efficiently at the edge. LAMs execute real-world actions. HRMs plan hierarchically.
LCMs reason at the semantic concept level.
For developers and architects building production AI agents, these distinctions matter. Choosing the wrong model type means building agents that are either overengineered (expensive, slow) or underequipped (missing the reasoning depth or action capability the task demands).
The most capable AI agents being built today are hybrid systems, routing tasks intelligently across multiple LLM types, each doing what it does best.
Which LLM type will power your next AI agent?

A standard LLM generates responses in a single forward pass using pretrained knowledge. An LRM (Large Reasoning Model) engages in extended chain-of-thought reasoning, it generates intermediate thinking steps, self-verifies, and iterates before producing a final answer. LRMs are specifically optimized for tasks requiring deliberate multi-step reasoning, like complex math, planning, and scientific problem-solving.
Yes, and increasingly, this is the norm in production systems. Modern agent frameworks like OpenAI’s Agents API support handoffs between specialized agents, each powered by different model types. A common pattern: LRM for planning, LAM for execution, SLM for preprocessing, VLM for visual input processing.
Three primary reasons: data privacy (SLMs run on-premise, so sensitive data never leaves your infrastructure), latency (SLMs can achieve sub-100ms inference vs. seconds for frontier API calls), and cost (frontier model API costs can be 10-100x higher per token). For tasks like classification, routing, and structured extraction, SLMs often match frontier model quality at a fraction of the cost.
All standard LLMs: GPT, MoE, LRM, SLM, etc., operate at the token level, predicting the next token in a sequence. Meta’s LCM operates at the sentence/concept level, predicting the next semantic unit using SONAR embeddings. This makes it language-agnostic across 200 languages and enables reasoning about ideas rather than words: A qualitatively different mode of processing.
As of mid-2025, HRM is primarily a research architecture. The 27M-parameter model demonstrated in arXiv:2506.21734 showed competitive ARC-AGI benchmark performance without CoT supervision, but production deployment frameworks, tooling, and large-scale validation are still developing. Its architectural principles are influencing hierarchical multi-agent system design, even if the specific HRM architecture isn’t yet production-standard.
Let’s evaluate your readiness and calculate your score in minutes
We use cookies to ensure our website functions properly, improve performance, and provide a personalized experience. You can choose which types of cookies to allow below.
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Help us understand site traffic and user interactions so we can improve performance and usability.
Enable enhanced functionality and personalization such as language or region preferences.
Used to deliver relevant ads, track campaign performance, and measure advertising effectiveness.