

















 Copy Link
Copy Link Share on X
Share on X Share on Facebook
Share on Facebook Share on LinkedIn
Share on LinkedIn


Always Active
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Build intelligent AI systems that automate decisions, accelerate innovation, and scale business growth.
Design, build, modernize, and scale digital products that drive business growth.
Build secure, scalable, and intelligent platforms that power modern enterprises.
Build intelligent, connected, and autonomous systems that operate in the real world.
Flexible engineering capacity with predictable delivery, ownership, and outcomes.
Uncover the transformative potential of digital and mobile solutions for your industry

 Last Updated: Jul 8, 2026
Mar 25, 2026
Last Updated: Jul 8, 2026
Mar 25, 2026  675
675  25 min. Read
25 min. Read



Key Takeaways
Let’s evaluate your readiness and calculate your score in minutes
Picture this. A fintech firm spends 18 months building a fraud detection model. It trains on three years of proprietary transaction data, passes every benchmark, clears internal review, and goes live. Six months into production, a competitor’s model starts flagging the same obscure edge-case patterns, the ones your team spent weeks engineering. No breach alert fires. No dashboard turns red. Nothing in your security logs flags anything unusual. And yet, something came out of your pipeline that should never have left.
Variants of this scenario are playing out across enterprises right now, including healthcare, retail, e-commerce, and financial services. However, most organizations do not discover the problem until the damage is already done.
According to McKinsey & Company, 88% of organizations are already using AI in at least one business function, but the majority of them are still in the experimenting or piloting stages. At the same time, security capabilities have not evolved at the same pace. As adoption accelerates, the gap between AI deployment and AI pipeline security is becoming a measurable business risk.
There are two threats sitting at the center of this risk: data leakage in AI pipelines and model poisoning attacks. They are different in mechanism, different in timing, and different in the damage they cause. But they share one important characteristic: traditional security infrastructure is largely blind to both.
This blog will help you make a clear-eyed decision to protect the AI investments you are already making. The enterprises that get this right in the next 24 months will have a material advantage over those that do not.
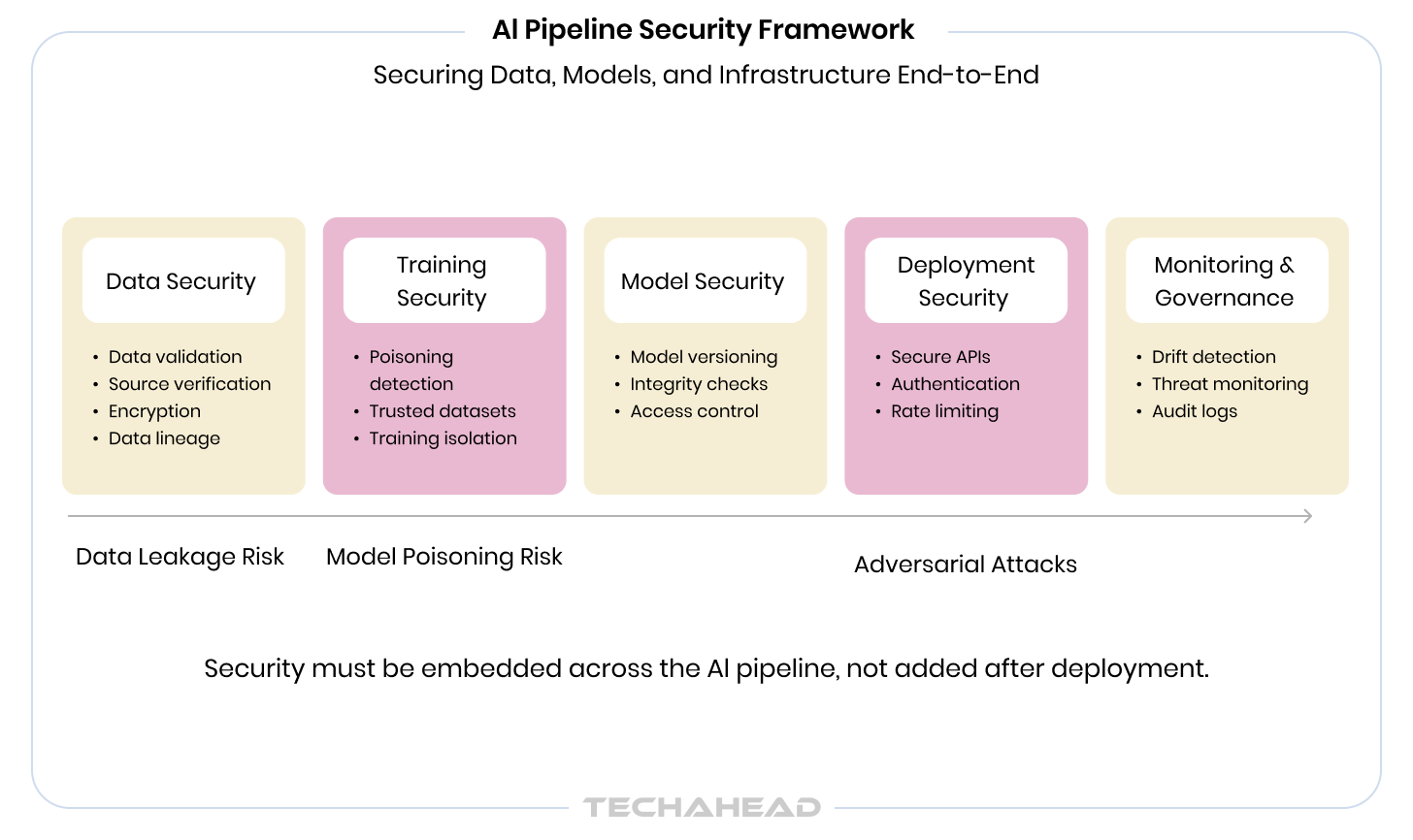
The first mistake most enterprise leaders make is handing AI security to the same team that manages perimeter defense. Firewalls, endpoint protection, and SOC dashboards are built to detect known intrusion patterns in relatively static systems. AI pipelines are neither static nor well-understood by conventional security tooling.
An AI pipeline is not a single system. It’s a chain of decisions: what data you collect, how you store and process it, what you train on, how you evaluate, where you deploy, and how you monitor. Each link in that chain carries its own category of risk. And the attack surface doesn’t live where most security teams are looking.
The more valuable your AI model, the more valuable it is as a target. Your competitive moat and security liability are the same asset.
Here’s how the risk actually breaks down. There are three layers where enterprise AI is most exposed:

The AI security risks that keep organizations up at night aren’t always about an external attacker breaking in. Sometimes, the vulnerability is baked into the model before it ever ships. And the impact looks different depending on your industry:
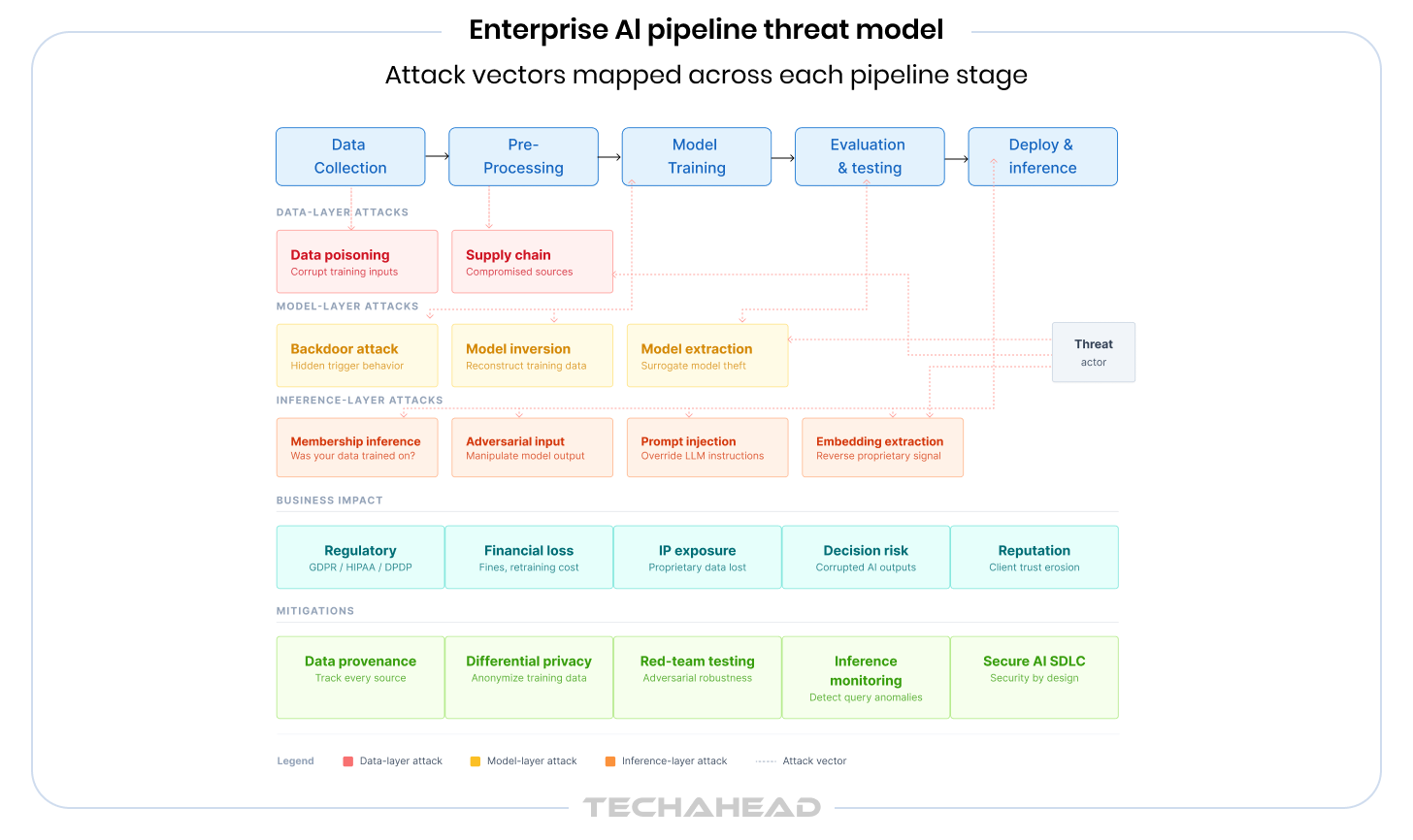
Most people assume data leakage in AI means a database was breached. It does not. The more insidious version requires no breach at all, just a well-crafted query to a model that’s already live.
Large models, particularly those trained on sensitive or proprietary datasets, have a tendency to memorize. Not in a conscious way, but in the statistical sense: patterns, sequences, and specific data points get encoded into model weights during training. With the right prompting strategy, an attacker can surface that encoded information without ever touching your database.
This is the mechanism behind these significant AI data security risks enterprises face today:
An attacker queries your model with variations of a specific record, like a customer’s transaction profile or a patient’s diagnostic inputs, and observes how the model responds. If the model shows statistically higher confidence in records that were in its training set, the attacker can determine whether that specific individual’s data was used to train the model. This is a direct GDPR Article 22 and HIPAA liability, and it requires no unauthorized system access, just your public-facing API.
Through carefully structured inference queries, an attacker can reconstruct approximate versions of sensitive training data directly from model outputs. In healthcare, this has been demonstrated on medical imaging models. In financial services, it’s been used to approximate behavioral profiles. The model becomes the leak.
Many enterprise AI systems, like recommendation engines, semantic search tools, and fraud classifiers, expose vector embeddings as part of their API response. These embeddings are mathematical representations of your data, and they carry more information than they appear to. A determined attacker who collects enough of them can reverse-engineer the underlying data distribution, effectively reconstructing what your model learned without ever accessing your training set. For e-commerce and retail companies whose competitive advantage lies in behavioral embeddings, this is a direct threat to proprietary signals.
If your enterprise has deployed a large language model, such as a customer-facing assistant, an internal knowledge tool, and a document summarization system, prompt injection is the attack surface you may be underestimating. An attacker crafts inputs designed to override the model’s instructions and coerce it into revealing information from its context window, its retrieval system, or its fine-tuning data. Unlike traditional SQL injection, there’s no static ruleset to block against. The vulnerability is in the model’s instruction-following behavior itself. Enterprises deploying RAG-based systems or LLMs with access to internal databases are particularly exposed.
Your model represents a significant investment, including months of data engineering, compute, and iteration. Model extraction attacks target that investment directly. By querying your model systematically at scale and observing its outputs, an attacker can train a surrogate model that approximates your model’s behavior, effectively stealing the intellectual property encoded in it without accessing your infrastructure. For companies that have commercialized proprietary AI, this is a business risk as much as a security one. Standard API rate limiting, while helpful, is not sufficient protection on its own.
Generative AI introduces a risk category that did not exist at scale three years ago. Models trained on internal documents, communications, or customer data do not just learn patterns, but they sometimes reproduce verbatim sequences from their training corpus when prompted in certain ways. This has been demonstrated on production LLMs, where specific prompting strategies caused the model to output email addresses, code snippets, and passages of text from training documents. For enterprises fine-tuning foundational models on proprietary data, this is an active and underappreciated exposure, one that sits squarely at the intersection of AI model vulnerabilities and data governance.
Also Read: Strategies for Gen AI and LLM Security
Data leakage in AI systems rarely happens because one thing fails catastrophically. It happens because several things are slightly wrong at once:
Note: A model does not need to be “hacked” to leak data. It just needs to ask the right questions. Therefore, you need to consistently monitor your inference to know what is happening.
Model poisoning attacks have a quality that makes them particularly dangerous for enterprise AI: by the time you see the damage, the cause is ancient history. The attack may have happened during data collection. Or during training. Or before you even touched the model, if it came from a third-party source.
Training data poisoning works by injecting corrupted, manipulated, or adversarially crafted data into the dataset before or during the training process. The model learns the wrong patterns, but because the poisoning is typically subtle and the test sets are clean, standard evaluation catches nothing. The model ships. It performs. And then, under the right conditions, it does exactly what the attacker intended.
Backdoor attacks are the most sophisticated variant of this. The model is trained to behave correctly 99% of the time. But when a specific trigger pattern appears in an input, a particular phrase, a pixel pattern, or a metadata flag, the model produces an attacker-controlled output. It’s not detectable through standard performance benchmarking. It will not show up in your accuracy metrics. It requires adversarial testing to find, and most enterprises do not do it.
Not all model poisoning attacks happen before deployment. Adversarial attacks in machine learning target the deployed model directly, using carefully crafted inputs designed to exploit blind spots in how the model learned to generalize.
The implications for automated decision pipelines are severe. A fraud detection model manipulated through adversarial inputs starts approving fraudulent transactions. A credit scoring engine produces systematically skewed outputs. A content classification system misses categories it was trained to catch. In each case, the model is functioning, just not correctly. And in fully automated pipelines with no human review, there’s nothing to catch.
Here’s the angle that most enterprise security briefings skip over entirely: the model itself may be the point of entry.
Most enterprise AI deployments today do not train models from scratch. They start with a pre-trained foundation model, from Hugging Face, from an open-source repository, or from a vendor, and fine-tune it on proprietary data. If that foundation model was compromised before you touched it, fine-tuning doesn’t clean it. It ships with your branding.
This is the AI equivalent of a software supply chain attack, and it’s underprotected almost everywhere. ML model security risks that originate upstream are invisible to teams that only audit their own code. The question you should be asking regarding the frontier enterprise AI stack: What do we actually know about where this came from?
These two threats operate differently and require different responses. Here’s how they compare across the dimensions that matter most to an enterprise risk conversation:
| Dimension | Data Leakage | Model Poisoning |
| How it happens | Model memorization, insecure pipelines, inference probing | Corrupted training data, supply chain compromise, adversarial triggers |
| When it strikes | Often immediately on deployment or via API probing | Weeks or months after training — often post-deployment |
| Detectability | Moderate — query anomalies can surface it | Low — model appears to function normally until triggered |
| Primary business risk | Regulatory exposure, competitive data loss | Decision corruption, operational sabotage |
| Recovery path | Model retraining + data governance overhaul | Full retraining from verified data; potential legal exposure |
| Who it affects most | Fintech (PII), Healthcare (PHI), EdTech (minor data) | Fraud detection, credit scoring, automated decision systems |

Before you can secure an AI pipeline, you need to know where it actually stands. This audit framework is the starting point we use when assessing enterprise AI environments. Work through it honestly. Every “no” or “not sure” is a gap. And that’s how threats find their way in.
| Audit Point | What It Checks | Self-Assessment | |
| 1 | Data Provenance Mapping | Can you trace every data source that touched your training set? | Yes / No / Partial |
| 2 | Access Control Audit | Who and what has read/write access to training data and model artifacts? | Yes / No / Partial |
| 3 | Training Data Integrity Checks | Are anomaly detection mechanisms flagging poisoned or corrupted inputs? | Yes / No / Partial |
| 4 | Third-Party Model Vetting | Have pre-trained or open-source models been evaluated for backdoors? | Yes / No / Partial |
| 5 | Differential Privacy Implementation | Is sensitive training data anonymized against inference attacks? | Yes / No / Partial |
| 6 | Adversarial Robustness Testing | Has your model been red-teamed with adversarial inputs before deployment? | Yes / No / Partial |
| 7 | Inference Monitoring | Are model queries logged and analyzed for extraction or probing patterns? | Yes / No / Partial |
| 8 | Output Filtering & Validation | Are guardrails preventing sensitive data from surfacing in model responses? | Yes / No / Partial |
| 9 | Model Drift & Behavioral Monitoring | Do automated alerts exist for unexpected behavioral shifts post-deployment? | Yes / No / Partial |
| 10 | AI Incident Response Plan | Does your IR plan specifically address AI model compromise scenarios? | Yes / No / Partial |
Scoring Guide: If you answered “No” or “Not sure” to 3 or more of these points, your AI pipeline has exploitable gaps. In our experience across enterprise engagements, most organizations flag 5 or more. That’s not unusual, but it is urgent.
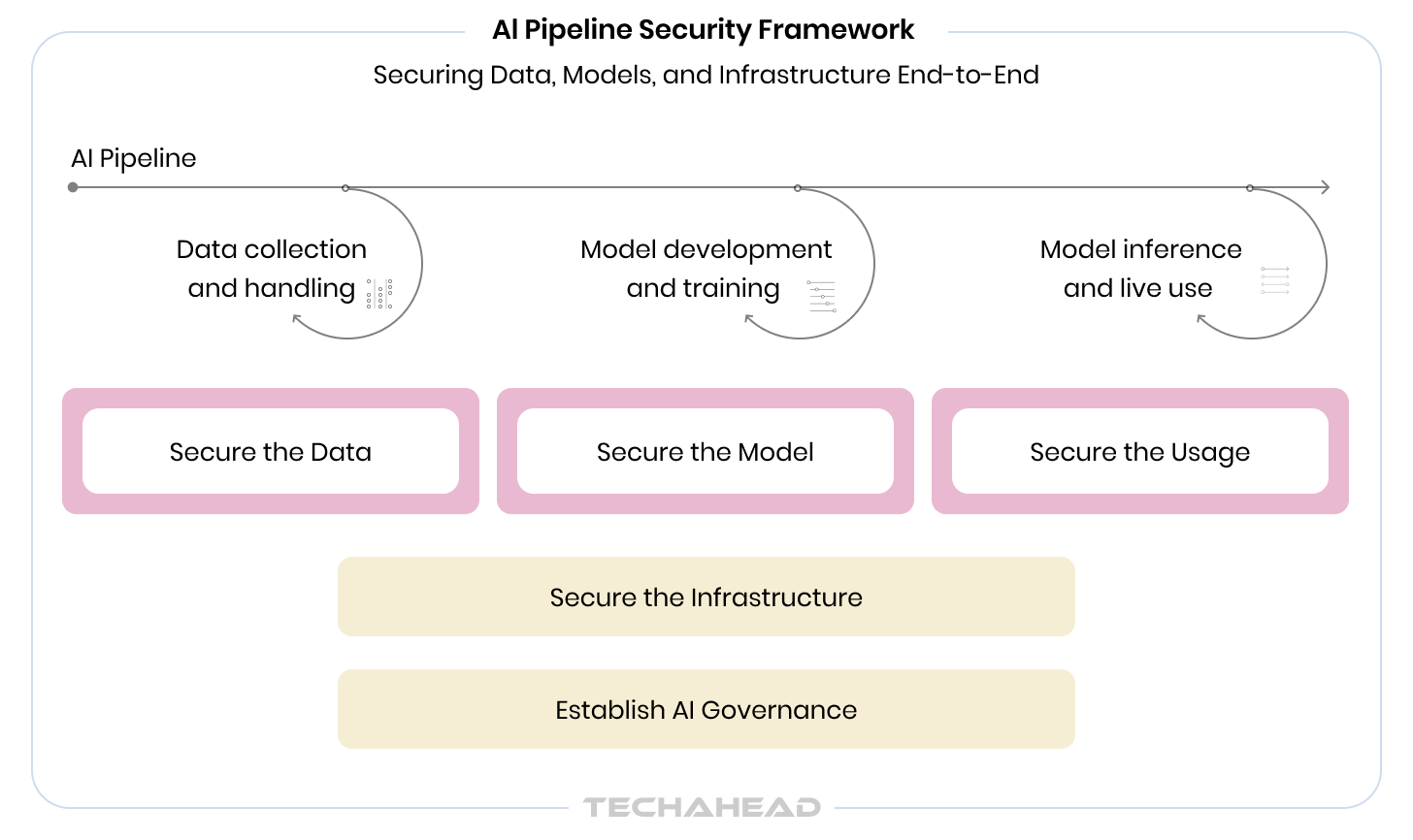
Securing machine learning models is not a phase in the development lifecycle. It’s a discipline that runs through every phase. The gap between an unsecured pipeline and a secure one is not a single decision, but a series of small choices made at each stage.
Here’s what that looks like in practice.
Each stage requires a different combination of expertise: data engineering, ML development, security architecture, and regulatory compliance. Your AI development company should excel at perimeter defense, equipped to handle all three stages well. This is why most enterprise AI security gaps do not come from negligence, but rather from the wrong team owning the problem.
Also Read: The Role of AI and ML in Threat Detection and Intelligence
The cost conversation usually starts with regulatory fines, and it should, as GDPR Article 83 penalties run up to 4% of global annual turnover. India’s DPDP Act introduces similar exposure. HIPAA violations in healthcare routinely reach eight figures. But the headline fine is rarely the highest cost.
Here’s how we think about the full cost of a compromised AI pipeline in an enterprise context:
A poisoned model is not patched. It’s rebuilt. That means reacquiring and re-sanitizing training data, restarting the training process, re-running evaluations, and repeating deployment, all while the compromised version either sits offline or, worse, continues running while you figure out what happened. For large enterprise models, this is a multi-month, multi-team effort.
Every business decision made on the outputs of a compromised model carries downstream financial risk. Loan approvals skewed by a poisoned credit model. Fraud allowed through by a backdoored detection system. Medical recommendations are influenced by a model that does not behave the way its performance metrics suggest. These are not hypothetical costs; they are liability events.
Proprietary training data, once exposed through model inference, cannot be recalled. The competitive signal embedded in your AI, such as years of customer behavior, transaction patterns, and clinical outcomes, is the most valuable thing your model encodes. If adversarial attacks in machine learning enable a competitor to approximate that signal, the advantage you built erodes permanently.
Enterprise clients and partners are increasingly asking hard questions about AI governance before signing contracts. A disclosed AI security incident resets trust relationships that took years to build. In business contexts, especially, the reputational tail on these incidents is long.
Most enterprise AI security failures don’t happen because organizations ignore security. They happen because security was handed to the wrong team, applied too late in the process, or treated as a compliance checkbox rather than an engineering discipline. At TechAhead, we have spent 16 years learning the difference and building accordingly.
TechAhead is a global AI consulting company that has delivered over 2,500 applications and digital platforms for Fortune 500 enterprises and high-growth startups across fintech, healthcare, retail, e-commerce, edtech, and so on. We have operated at the scale where AI security stops being theoretical, where a misconfigured training pipeline or an unvetted open-source model has real financial and regulatory consequences for the organizations we partner with.
What separates our approach is the fact that security architecture is designed into every engagement from the first technical conversation.
Enterprise AI security requires verified, audited, and independently validated practices. TechAhead holds the SOC 2 Type II certification, which is a testament that our security controls, processing integrity, confidentiality, and privacy practices have been independently audited and validated.
Moreover, we are an AWS Advanced Tier Partner with Security Services Competency, one of the most demanding validations in the cloud ecosystem, requiring demonstrated expertise in security engineering on AWS infrastructure. Our AI workloads run on architectures that meet AWS’s highest security benchmarks. And GDPR and HIPAA compliance frameworks are embedded into our data handling and model development practices.
The clients who come to us after a security incident consistently tell us the same thing: they wish the conversation had happened earlier. For clients who start with us, it does. Here is how we apply AI pipeline security discipline across engagements:
Every AI engagement begins with a security and data governance scoping session. We map your data sources, identify regulatory obligations, define access control architecture, and establish what security means specifically for your use case, whether that is HIPAA compliance for a healthcare AI or PCI-DSS alignment for a fintech model processing transaction data.
Our engineering teams operate under DevSecOps principles, as security controls are embedded in the development pipeline. Training data undergoes integrity validation before it enters any model. Third-party and open-source foundation models are evaluated for known vulnerabilities, backdoor risks, and provenance before being incorporated into any client architecture. Our MLOps practice includes behavioral monitoring configuration as a standard deliverable, not an optional add-on.
We instrumented and deployed models with inference anomaly detection, output filtering, and behavioral drift alerts from day one. Our AI Infrastructure Management service provides ongoing oversight of production AI environments.
That is the baseline we bring to every AI engagement. Are you building AI that processes sensitive data, makes consequential decisions, or encodes proprietary signals? Contact us to know how we can help you achieve this.
The threats covered in this piece, i.e., data leakage and model poisoning, are not edge cases. They are a natural consequence of building powerful AI systems on top of pipelines that were not designed with security as a first principle. As AI becomes more deeply embedded in enterprise operations, the organizations that treat AI risk management as a discipline will be the ones that scale with confidence.
The 10-point audit in this piece is a starting point. Work through it with your engineering and security leads. Identify your top three gaps. Those gaps are your AI roadmap.
If you have reached this point and the answer is “we are not sure where we stand,” that’s the most common answer we hear from enterprise technology leaders, and it’s a perfectly reasonable place to start.
Traditional cybersecurity monitors networks, secures endpoints, and blocks unauthorized access. AI pipeline security protects behavior. It addresses threats that exist entirely inside the model itself: data that was poisoned before training, outputs that can be reverse-engineered to expose sensitive records, or inputs crafted specifically to manipulate what the model decides. A firewall has no visibility into any of this. The attack surface is different, the tools are different, and the expertise required is different. That’s why most enterprises that rely solely on their existing security function to protect AI are underprotected, often without knowing it.
Significantly, yes. When you fine-tune a pre-trained model on proprietary data, you inherit whatever vulnerabilities exist in that foundation model. Researchers have demonstrated that backdoors can survive the fine-tuning process intact, meaning a compromised base model remains compromised even after you’ve trained it on your own data. This is one of the most underappreciated ML model security risks in enterprise AI today. Every pre-trained model entering your pipeline should be evaluated for provenance, known vulnerabilities, and behavioral anomalies before it touches your data or your production environment.
The regulatory landscape is converging fast. GDPR’s Article 83 allows fines of up to 4% of global annual turnover for data protection failures and membership inference attacks that expose whether an individual’s data was used in training, which is a direct Article 22 liability. HIPAA violations in healthcare can reach into the tens of millions. India’s Digital Personal Data Protection Act mirrors GDPR in scope and is actively being enforced. The EU AI Act introduces additional requirements for high-risk AI systems, including transparency, risk management, and data governance obligations. Beyond fines, the liability exposure from decisions made by a compromised AI model, such as credit approvals, fraud flags, and medical outputs, creates a second layer of legal risk that most enterprises have not fully mapped.
Before the first line of training code is written. The decisions made at the data collection and architecture stage determine what’s even possible in terms of security downstream. If you build a training pipeline without data lineage tracking, there’s no retroactive way to answer “which records trained this model?” If you don’t apply differential privacy at the data layer, you can’t unexpose that information later. The most expensive AI security engagements we see are the ones that start after something has already gone wrong.
Longer than most organizations expect. A poisoned model can’t be patched. It has to be retrained from scratch, which means reacquiring and re-sanitizing your training data, validating that the poisoning vector has been identified and closed, rerunning the full training process, re-evaluating for robustness, and re-deploying. For large enterprise models, this is typically a multi-month effort involving multiple teams. Meanwhile, you are either running a compromised model or running nothing. The retraining cost is just one dimension, like regulatory notification requirements, forensic investigation, downstream decision review, and client communication, all of which compound the timeline and the cost.
Secure software development focuses on code-level vulnerabilities like injection attacks, authentication flaws, and insecure dependencies. A secure AI development lifecycle covers all of that, plus an entirely different category of risks that do not exist in traditional software: training data integrity, model behavioral security, inference-time manipulation, and ongoing behavioral monitoring post-deployment. The AI model is a dynamic system whose behavior is determined by what it learned, from what data, under what conditions. Securing it requires continuous oversight across the full lifecycle, not just a security review before launch.
Let’s evaluate your readiness and calculate your score in minutes
We use cookies to ensure our website functions properly, improve performance, and provide a personalized experience. You can choose which types of cookies to allow below.
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Help us understand site traffic and user interactions so we can improve performance and usability.
Enable enhanced functionality and personalization such as language or region preferences.
Used to deliver relevant ads, track campaign performance, and measure advertising effectiveness.