

















 Copy Link
Copy Link Share on X
Share on X Share on Facebook
Share on Facebook Share on LinkedIn
Share on LinkedIn


Always Active
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Build intelligent AI systems that automate decisions, accelerate innovation, and scale business growth.
Design, build, modernize, and scale digital products that drive business growth.
Build secure, scalable, and intelligent platforms that power modern enterprises.
Build intelligent, connected, and autonomous systems that operate in the real world.
Flexible engineering capacity with predictable delivery, ownership, and outcomes.
Uncover the transformative potential of digital and mobile solutions for your industry

 Last Updated: Jul 15, 2026
May 1, 2026
Last Updated: Jul 15, 2026
May 1, 2026  745
745  33 min. Read
33 min. Read



Key Takeaways
Let’s evaluate your readiness and calculate your score in minutes
AI adoption is no longer experimental. It is operational.
According to McKinsey & Company, 88% of organizations already use AI in at least one business function. The shift is clear: AI is moving from isolated pilots to embedded systems inside core workflows.
However, adoption does not equal maturity.
Most deployed systems still operate as stateless tools — responding to prompts without continuity, memory, or long-term context. This gap between adoption and capability is where enterprise value is either unlocked or lost.
Agent memory state management is critical for building advanced AI agents that deliver real business value. The primary goal is to enable agents to maintain an effective agent state, capturing and storing interaction data, conversation history, and system events within persistent memory. This allows AI agents to retain context, recognize patterns over time, and adapt based on past interactions, which is essential for creating personalized user experiences. Notably, the gap between having memory and not having memory is often larger than the differences between LLM backbones, making memory architecture and ongoing AI development crucial for agent performance and innovation.
In enterprise environments, this is not merely a technical inconvenience — it is a fundamental barrier to value. A customer support agent who cannot remember a user’s case history. A code assistant that forgets the architectural decisions made in yesterday’s sprint. A procurement agent that ignores supplier negotiations already in progress. These failures, rooted in absent or poorly designed agent memory systems, erode trust, waste time, and cap the ROI that organizations expect from AI investments.
This blog is structured as a practitioner’s guide for enterprise decision-makers who are moving from pilot to production. It covers the full lifecycle of agent memory state management: from theoretical foundations through architecture design, implementation patterns, failure modes, security governance, and a practical enterprise roadmap.
Beyond the Context Window: From Stateless LLM to Stateful Agent
At its core, agent memory refers to any information that an AI agent retains, accesses, or updates across the boundaries of a single inference call. This is a critical distinction. A large language model (LLM) in isolation is inherently stateless — feed it a prompt, receive a completion, repeat. The model itself carries no knowledge of what happened before or after any given call.
AI agents — systems that use LLMs as reasoning engines but surround them with tools, memory infrastructure, and orchestration logic — are designed to be stateful. Agent memory is the mechanism that makes stateful behavior possible. It is the bridge between what an LLM can do in a single call and what an AI system can accomplish across an extended, complex, goal-directed workflow.
| Stateless LLM | Stateful AI Agent |
| No memory between calls | Persists context across sessions |
| Context window is the only memory | Multiple memory tiers (short + long term) |
| Identical response to identical prompt | Response shaped by history & preferences |
| No user model | Builds and updates user preference model |
| Each call independent | Actions informed by past interactions |
| Simple, predictable | Complex, adaptive, personalized |
Understanding this distinction shapes every architectural decision that follows. When we talk about agent memory state management, we are talking about the engineering required to make AI agents behave as if they truly know the people and systems they serve because in a meaningful technical sense, they do.
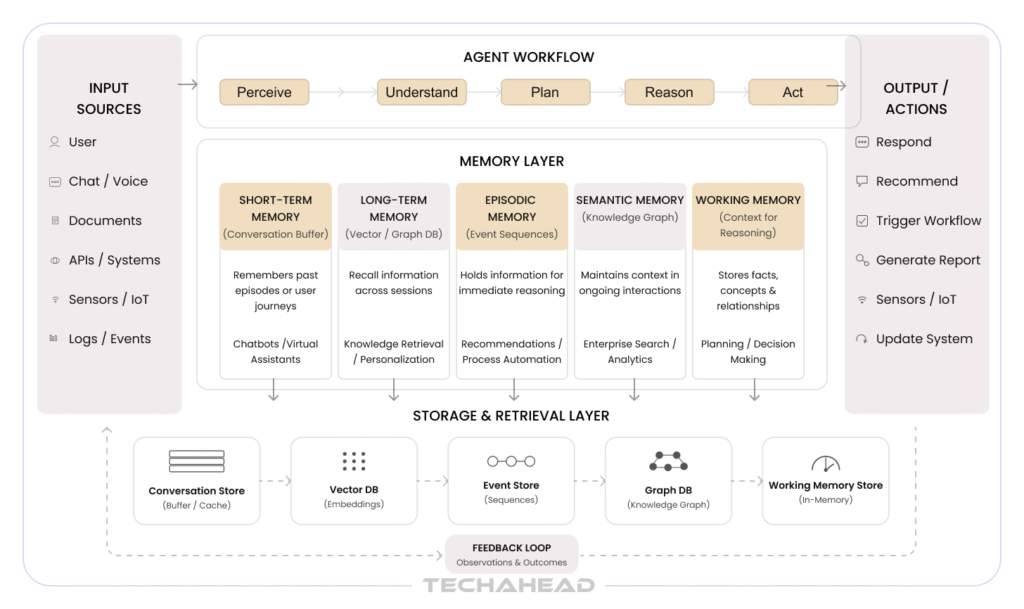
Cognitive science and computer science together give us a useful taxonomy for thinking about agent memory. The canonical categories map directly to different engineering approaches and infrastructure choices. Each type serves a distinct purpose in the broader memory architecture.
| Memory Type | Time Horizon | Primary Storage |
| Short-Term (Working) | Seconds to minutes | In-process / context window |
| Long-Term | Days to indefinitely | Vector DB / persistent store |
| Episodic | Event-scoped | Structured logs / graph DB |
| Semantic | Stable / slow-changing | Knowledge base / vector store |
| Procedural | Skills / workflows | Structured config / policy store |
Short-term memory — also called working memory in cognitive science — represents the immediate conversational context available to an AI agent within a single interaction session. This is the information residing in or adjacent to the context window: the current exchange, recently retrieved facts, tool call results from the last few steps, and any ephemeral state needed to complete the current task.
Unlike short-term memory in humans, which has rough biological limits, an AI agent’s working memory is bounded by the context window of the underlying model. For modern OpenAI models, this may be 128K tokens or more — substantial, but still finite. Effective agent memory state management treats the context window as a precious, managed resource, not an infinite buffer.
Implementation Pattern: Use thread-scoped data structures (per-session dictionaries or message queues) to manage working memory. Define explicit eviction policies — when a session exceeds 70% of the context window budget, trigger summarization of older turns rather than truncation. Truncation destroys information; summarization condenses it.
Key design decisions for short-term working memory include:
Long-term memory is the persistent layer of agent memory state management — the information that survives between sessions and accumulates over time. It is what allows an AI agent to recognize a returning user, apply lessons learned from past interactions, and maintain a coherent model of the world it operates in.
Unlike short-term memory, which lives within or adjacent to the context window, long term memory requires external storage infrastructure. The two dominant patterns are vector databases (for unstructured or semi-structured content requiring semantic retrieval) and traditional persistent databases (for structured user preferences, explicit facts, and operational records).
Recommended persistent storage options by use case:
| Use Case | Recommended Storage |
| User preferences & profile data | Relational DB (PostgreSQL, Supabase) |
| Conversation summaries | Vector DB (Pinecone, Weaviate, pgvector) |
| Domain knowledge & facts | Vector DB + knowledge graph |
| Task outcomes & decisions | Structured log + relational DB |
| Agent-generated documents | Blob storage + metadata index |
| Compliance audit trails | Append-only event store |
Consolidation policy — the rules governing when and how information moves from short-term to long-term memory — is one of the most consequential design decisions in any agent memory system. Consolidate too aggressively, and you store noise that degrades retrieval precision. Consolidate too conservatively, and valuable context is lost when sessions end.
Recommended consolidation cadence: Run consolidation at session end (immediate) for user intent signals, daily for conversation summaries, and weekly for semantic distillation of accumulated episodic records.
Episodic memory captures the specific events that define an agent’s history with a user or system: what happened, when it happened, what preceded it, and what followed. In cognitive terms, episodic memory is autobiographical — it is the record of experience rather than the distillation of knowledge.
For AI agents, episodic memory is the event log. It captures actions taken, decisions made, errors encountered, feedback received, and outcomes observed. This memory type is essential for:
Event logging for episodic memory should follow structured formats (JSON-LD or similar) and include: timestamp, session ID, agent ID, action type, inputs, outputs, latency, and a confidence or quality signal where available.
Semantic memory holds the stable, factual knowledge base that an agent draws upon when reasoning about the world. Unlike episodic memory (what happened) or short-term memory (what is happening now), semantic memory represents what is generally known: product specifications, company policies, regulatory requirements, domain ontologies, and any persistent knowledge that does not change with individual interactions.
Procedural memory captures how-to knowledge: the workflows, decision trees, tool-use patterns, and operational procedures that define how an agent accomplishes its goals. If semantic memory is the encyclopedia, procedural memory is the cookbook.
Both types are typically stored in vector databases for retrieval or in structured configuration systems for deterministic access. Update cadence matters significantly:
A common failure pattern: teams update semantic and procedural memory ad hoc, without versioning or validation. The result is an agent that behaves differently — and unpredictably — than expected, because the memory it draws on has silently changed.
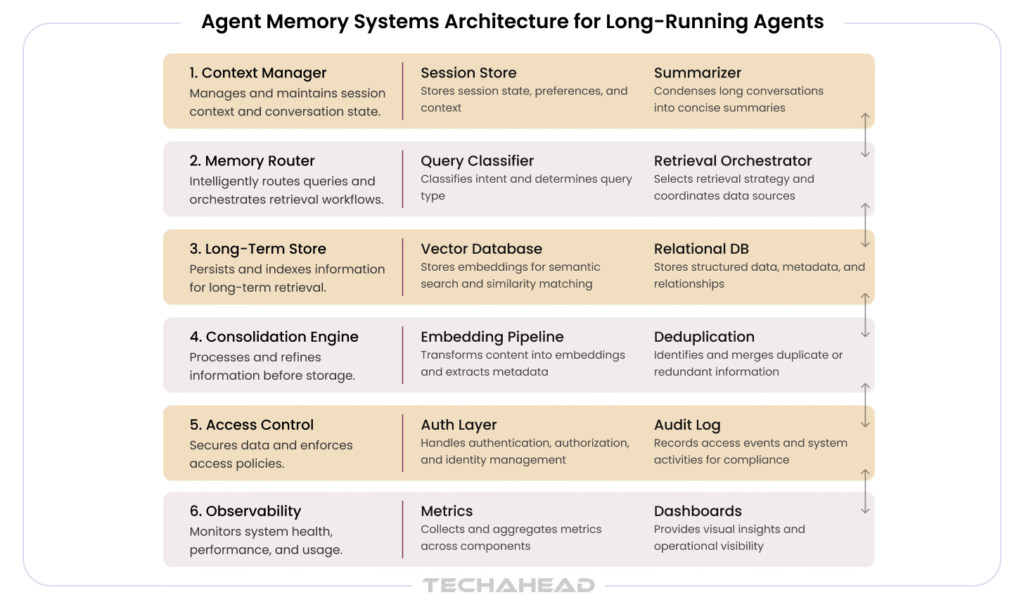
Agent memory state management at scale requires a layered architecture that separates concerns, allows independent scaling, and provides clear ownership of each memory type. The following describes a production-grade reference architecture designed for long-running enterprise agents.
| Layer | Responsibility | Key Components |
| Context Manager | Short-term memory lifecycle | Session store, summarizer, window monitor |
| Memory Router | Request routing to correct store | Query classifier, retrieval orchestrator |
| Long-Term Store | Persistent memory CRUD | Vector DB, relational DB, blob store |
| Consolidation Engine | Short→Long-term promotion | Embedding pipeline, deduplication, indexer |
| Access Control | Security & compliance | Auth layer, namespace isolation, audit log |
| Observability | Monitoring & alerting | Metrics, traces, memory health dashboards |
This architecture is intentionally modular. Each layer can be implemented independently and evolved as requirements grow. Start with the context manager and a simple key-value long-term store; graduate to vector databases and consolidation engines as usage patterns become clear.
Effective agent memory state management requires understanding which storage tier is appropriate for which type of memory, at which point in the memory lifecycle. The three-tier model — in-memory, vector database, cold archival — maps cleanly to the temporal and retrieval characteristics of different memory types.
| Storage Tier | Best Used For |
| In-Memory (Redis, local cache) | Active session context, hot user preferences, recent tool results |
| Vector Database (Pinecone, Weaviate) | Semantic search over conversation history, knowledge retrieval |
| Relational DB (PostgreSQL) | Structured user profiles, explicit preferences, audit records |
| Cold Archival (S3, GCS) | Compliance archives, infrequently accessed episodic records |
| Graph DB (Neo4j) | Relationship-rich knowledge, multi-hop reasoning, entity graphs |
Vector databases are the backbone of semantic retrieval in modern agent memory systems. They store embeddings — dense numerical representations of text — and enable retrieval based on semantic similarity rather than exact keyword matching. This is essential for finding relevant memories from previous conversations without knowing the exact words used.
Key implementation decisions for vector store integration:
Pure vector search is powerful but not always sufficient. Hybrid indexing — combining dense vector search with sparse keyword matching (BM25 or similar) — yields meaningfully better retrieval precision, particularly for domain-specific terminology and proper nouns that may not embed well in general-purpose models.
| Dataset Size | Recommended Index Strategy |
| < 100K documents | Pure vector search with HNSW index |
| 100K–10M documents | Hybrid: HNSW + BM25 with reciprocal rank fusion |
| > 10M documents | Distributed vector index + full-text search (Elasticsearch or OpenSearch) |
Define latency targets explicitly and enforce them in testing: sub-100ms for immediate conversational context retrieval, sub-500ms for broader historical memory retrieval during session initialization.
When designing agent memory state management, selecting the right index type is essential for balancing performance and scalability. For small datasets (up to 10,000 records), in-memory vector stores or lightweight databases like SQLite are sufficient. For medium datasets (10,000 to 1 million records), consider using scalable vector databases such as Pinecone or Weaviate. For large-scale datasets (over 1 million records), distributed solutions like Elasticsearch or Milvus are recommended.
It’s important to plan for rag memory updates, compression, and integration with semantic memory to prevent system degradation as your dataset grows. Regularly updating and maintaining rag memory ensures that the agent’s memory system remains efficient and accurate, supporting robust agent performance.
Latency targets should be defined based on the interaction type and user expectations. For real-time interactions (e.g., chatbots or virtual assistants), aim for sub-second response times (typically <500ms). For batch processing or analytics, higher latencies (1-5 seconds) may be acceptable.
Remember, memory architecture is crucial for AI agents—often, the gap between having memory and not having memory is larger than the differences between various language model backbones. Prioritizing a robust memory system, including effective rag memory management, will have a significant impact on overall agent performance and user experience.

The write-manage-read loop is the operational heartbeat of any agent memory system. Every piece of memory passes through this cycle: it is written when created or updated, managed to enforce retention and quality policies, and read when the agent needs to recall relevant context.
Memory is written at well-defined trigger points: at session start (initializing context from persistent store), at session end (consolidating working memory to long-term store), on explicit memory operations initiated by the agent or user, and asynchronously via background consolidation workers.
Instrumentation requirements for write operations: log write latency, memory type, namespace, embedding latency (for vector writes), and success/failure status. Alert on write failure rates exceeding 0.1%.
Memory management is the ongoing governance of what is kept, what is compressed, and what is deleted. Effective memory management requires:
Memory retrieval during the read phase must be both fast and precise. Relevant memories are retrieved via semantic search against the vector store, filtered by namespace and recency, ranked by a combined relevance+recency score, and injected into the agent’s context at the appropriate granularity.
Design principle: Inject memory summaries by default; inject full episodic records only on explicit need. Verbose memory injection bloats the context window and reduces the proportion available for active reasoning.
Agent memory state management is only as reliable as the policies governing it. Policies should be defined explicitly, version-controlled, and enforced programmatically — not left to ad hoc judgment during implementation.
| Memory Type | Retention Policy | Consolidation Rule |
| Working (in-session) | Session TTL + 24h idle expiry | Summarize at 80% context window |
| Episodic (event log) | 90 days active, then archive | Weekly distillation to semantic store |
| Semantic (knowledge) | Indefinite until superseded | Update on source change + validation |
| Procedural (workflows) | Versioned; previous kept 30d | Staged rollout with A/B validation |
| User preferences | Duration of user relationship | Update on explicit feedback or signal |
TTLs for short-term data must be defined at the namespace level, not globally. A customer-facing agent session may expire after 30 minutes of inactivity; a long-running analytical workflow may retain working memory for 72 hours. One-size-fits-all TTL policies are a common source of both data loss and unnecessary storage cost.
Context-aware AI agents are the product of thoughtful agent memory state management applied at every stage of the interaction lifecycle. The three key engineering moments are: context hydration at session start, selective context injection per request, and APIs for explicit memory management.
When a session begins, the agent must rapidly assemble a relevant picture of the user, their history, and the current task context. This process — context hydration — should be asynchronous where possible and structured to avoid injecting irrelevant or stale information.
A practical hydration sequence:
Not every request needs the full memory context. Agent memory state management at the request level means classifying each incoming request by its memory requirements and injecting only what is relevant.
Use a lightweight classifier (a custom LLM call or a rule-based router) to tag each request: Does it require user history? Domain knowledge? Procedural instructions? Previous conversation context? Route accordingly, and inject only the tagged memory types. This preserves context window budget for active reasoning and reduces latency.
Production agents must expose APIs for explicit memory management — both for users and for system administrators. At minimum:
To achieve this, leveraging vector databases is a best practice for storing and retrieving memories at scale. Vector databases enable fast similarity searches, allowing agents to efficiently surface relevant memories from large datasets. This is particularly valuable for long running agents that need to recall user preferences or previous conversations across multiple sessions. Additionally, implementing memory management techniques such as summarization, compression, and intelligent eviction policies helps reduce memory footprint and improves retrieval speed. These strategies ensure that only the most relevant information is retained, optimizing both storage and access times.
Effective memory systems also require careful orchestration of memory operations—writing, managing, and reading—so that agents can seamlessly update, consolidate, and retrieve memories as needed. Instrumentation and monitoring of these processes are critical for maintaining high performance and quickly identifying bottlenecks. By designing agent memory systems with these optimization strategies, enterprises can build production ready systems that deliver fast, context aware, and reliable AI experiences.
Agent memory is a cornerstone of high-performing AI agents, directly shaping their ability to deliver accurate, personalized, and context aware responses. Well-designed memory systems empower AI agents to maintain context, recall previous conversations, and adapt to evolving user preferences, resulting in more coherent and effective interactions. Unlike short term memory, which is limited to the immediate conversational context, long term memory enables agents to store and retrieve information from past interactions, supporting adaptive learning and continuous improvement over time.
Procedural memory further enhances agent performance by capturing behavioral patterns and learned skills, allowing agents to respond intelligently to new situations and execute complex tasks. By integrating these memory components, AI agents can remember user preferences, reference previous messages, and provide responses that are both relevant and consistent across multiple sessions.
Optimizing agent memory systems not only improves conversational context and response quality but also enables agents to scale effectively in real world applications. Enterprises benefit from agents that can retain context, remember key insights, and deliver persistent knowledge across diverse workflows. Ultimately, investing in robust agent memory architecture is key to enabling agents that are efficient, adaptive, and capable of meeting the demands of production systems in dynamic business environments.
Agent memory state management introduces failure modes that differ from traditional software systems. Many are subtle — the agent continues to operate, but its behavior degrades silently as memory becomes inconsistent, stale, or irrelevant. Understanding these failure classes is essential for building resilient systems.
| Category | Example Failures | Detection Signal |
| Context-Resident | Summarization drift, context poisoning | Output quality degradation |
| Retrieval | Low-relevance recall, embedding drift | Retrieval precision metrics |
| Knowledge Integrity | Stale facts, conflicting memories | Factual accuracy evaluations |
Summarization drift occurs when the iterative compression of conversation history introduces inaccuracies or omissions that compound over time. An agent operating on a drifted summary may make decisions based on a significantly distorted version of what actually occurred in previous conversations.
Mitigation: Detect drift early by comparing agent outputs against ground-truth conversation records on a sampled basis. Enforce context window audits periodically — automated tests that verify the agent’s stated understanding of past interactions matches the actual record.
Retrieval failures include returning low-relevance memories (embedding model mismatch), missing relevant memories (index gaps), and latency spikes that cause retrieval timeouts. Knowledge-integrity failures include operating on stale long-term facts and conflicting memories from different sources.
Security is one of the biggest blockers to enterprise AI adoption.
According to PwC, 83% of organizations identify data privacy as their primary concern when deploying AI.
57% of organizations identify data privacy, and 43% cite trust and transparency concerns as the biggest inhibitors of generative AI.
This becomes critical in memory systems, where:
Agent memory state management at the enterprise level is inseparable from security and compliance. Memory stores contain sensitive data — user behaviors, business decisions, personal preferences, potentially PII and PHI. Treating memory security as an afterthought is one of the most common and consequential mistakes in enterprise AI deployment.
Begin with a memory data classification exercise. Identify which memory types contain:
Implement role-based access control (RBAC) at the namespace level. Encrypted data at rest (AES-256) and in transit (TLS 1.3) is a baseline requirement. Access control policies must restrict memory reads to agents and users with legitimate need, with all access logged to an immutable audit trail.
GDPR, CCPA, HIPAA, and emerging AI-specific regulations all impose requirements on data retention and deletion. Agent memory systems must implement:
You cannot manage what you cannot measure. Agent memory state management requires dedicated observability infrastructure — metrics, traces, and alerts specifically designed for memory systems, not generic application monitoring repurposed for AI.
| Metric | Purpose / Alert Threshold |
| Memory write latency (p50, p99) | Alert if p99 > 200ms (sync) or > 2s (async) |
| Memory retrieval latency (p50, p99) | Alert if p99 > 100ms for working memory retrieval |
| Retrieval precision @ k | Alert if precision drops > 10% from baseline |
| Context window utilization | Alert if avg utilization > 85% |
| Memory consolidation lag | Alert if consolidation backlog > 1 hour |
| Memory deletion compliance rate | Alert if < 99.9% of requested deletions complete |
Build and maintain a synthetic test suite for agent memory systems that exercises the full read-write-manage cycle with known inputs and expected outputs. Include:
Enterprise use cases have requirements that casual or consumer AI interactions do not. Consider three representative scenarios:
In each case, agent memory state management is not a nice-to-have feature — it is a prerequisite for the agent to deliver measurable business value. The absence of effective memory systems is why many enterprise AI pilots fail to progress to production: the demos work, but the deployed systems do not remember.
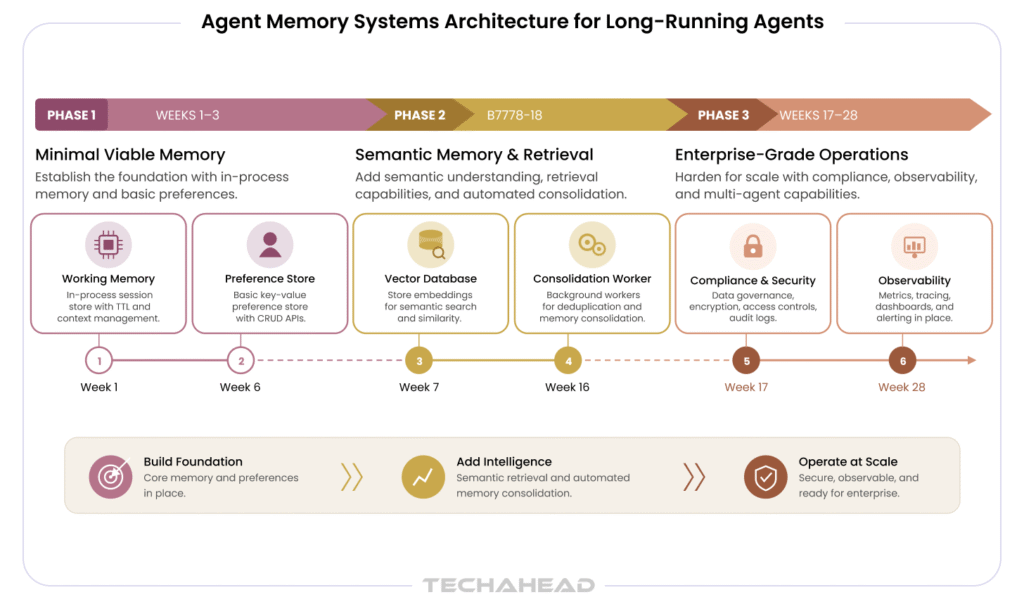
TechAhead’s work with enterprises as Claude & OpenAI Services Partner has produced a practical, phased approach to implementing agent memory state management that balances speed-to-value with architectural soundness. The roadmap below reflects patterns from deployments across financial services, healthcare, retail, and technology sectors.
Start with the simplest memory system that delivers measurable business value. Resist the urge to build the full architecture upfront.
Once Phase 1 is stable and validated, graduate to vector-based retrieval.
TechAhead Recommendation: Define your memory success metrics before your memory architecture. Organizations that measure memory quality from day one are significantly better positioned to iterate toward production-grade systems than those that optimize infrastructure without a clear definition of ‘good’.
Agent memory state management is the capability that separates AI agents from AI demos. It is what allows an enterprise AI system to know its users, remember its decisions, learn from its mistakes, and deliver the kind of sustained, personalized value that justifies the investment in AI development services.
The technical foundations are available today — OpenAI’s models and APIs, production-grade vector databases, mature observability tooling, and an established body of architectural patterns. What most enterprises lack is the discipline to implement these foundations systematically: with defined policies, rigorous testing, compliance-aware design, and operational monitoring built in from the start.
TechAhead, as Claude & OpenAI Services Partner, brings both the technical expertise and the enterprise deployment experience to help organizations navigate this journey — from architecture design through production rollout, with memory systems that meet the precision, scale, and compliance requirements of serious enterprise use.

Agent memory state management is the discipline of capturing, organizing, persisting, and retrieving the contextual information that AI agents need to operate coherently across multiple interactions and sessions.
Without it, every AI conversation starts from zero — the agent has no awareness of previous conversations, user preferences, or historical decisions. For enterprise deployments, effective agent memory state management is a prerequisite for AI that delivers sustained, compounding business value rather than one-off task completion.
AI agents use five canonical memory types, each serving a distinct operational purpose.
Short-term (working) memory holds the immediate conversational context within the current session. Long-term memory persists information across sessions — user preferences, historical decisions, accumulated knowledge. Episodic memory captures specific events: what happened, when, and in what sequence. Semantic memory stores stable domain knowledge — policies, product specs, ontologies. Procedural memory encodes how-to knowledge — workflows, tool-use patterns, and decision procedures.
Each type requires different storage infrastructure and retrieval strategies in a complete agent memory systems architecture.
Short-term memory in AI agents is session-scoped and lives within or adjacent to the model’s context window — it holds what is happening right now and is discarded when the session ends.
Unlike short-term memory, long-term memory is externally persisted and survives between sessions. It requires dedicated infrastructure: vector databases for semantic retrieval, or relational databases for structured preferences and explicit facts.
The critical design decision is consolidation — the rules governing what information moves from short-term to long-term storage, when that promotion happens, and how stale entries are eventually retired. Consolidation policy is what most teams underdesign.
AI agents maintain context across sessions through a process called context hydration. At the start of each new session, the agent retrieves relevant information from its persistent memory store and injects it into the active context window before any user interaction begins.
This typically involves: pulling the user’s preference profile from a structured database, querying a vector database for semantically similar summaries from previous conversations, and loading recent episodic records. The result is an agent that recognizes returning users and applies prior context without requiring the user to repeat themselves.
When multiple agents collaborate on shared tasks, agent memory state management adds coordination complexity. Each agent needs access to shared task context without one agent’s writes corrupting another’s working state.
The standard pattern uses namespace-based isolation with controlled sharing: each agent maintains a private namespace for session-specific short-term working memory, while a shared namespace — mediated by an orchestrator — holds task-level context accessible to all participating agents.
Write access to shared namespaces requires locking or optimistic concurrency control to prevent race conditions. Retrieval must also account for which agent generated which memory record, to prevent inappropriate cross-agent context bleed in context-aware workflows.
Agent memory systems face three primary failure categories, all of which allow the agent to keep operating — just incorrectly.
Context-resident failures: Repeated summarization of conversation history introduces drift — the compressed memory gradually diverges from what actually occurred. Detect this early with sampled ground-truth comparisons.
Retrieval failures: Vector databases return low-relevance results due to embedding model mismatch or index degradation. Prevent with a golden test set of query-memory pairs evaluated on every index update.
Knowledge-integrity failures: Long-term facts become stale as the world changes. Implement confidence-decay functions and staleness detection, with human review for high-stakes memory storage used in regulated decisions.
Agent memory stores contain sensitive enterprise data — behavioral signals, business decisions, and often PII or PHI. Security must be built in from day one.
The core requirements are: data classification (identify which memory components contain regulated data), encrypted data at rest (AES-256) and in transit (TLS 1.3), access control enforced at the namespace level with role-based permissions, immutable audit logging of all memory operations, and deletion workflows that satisfy GDPR right-to-erasure, HIPAA data governance, and CCPA compliance requirements.
Persistent knowledge stores that touch PHI must also meet HIPAA’s minimum-necessary standard — agents should retrieve only what the task requires, never full patient histories.
Let’s evaluate your readiness and calculate your score in minutes
We use cookies to ensure our website functions properly, improve performance, and provide a personalized experience. You can choose which types of cookies to allow below.
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Help us understand site traffic and user interactions so we can improve performance and usability.
Enable enhanced functionality and personalization such as language or region preferences.
Used to deliver relevant ads, track campaign performance, and measure advertising effectiveness.