

















 Copy Link
Copy Link Share on X
Share on X Share on Facebook
Share on Facebook Share on LinkedIn
Share on LinkedIn
Always Active
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Build intelligent AI systems that automate decisions, accelerate innovation, and scale business growth.
Design, build, modernize, and scale digital products that drive business growth.
Build secure, scalable, and intelligent platforms that power modern enterprises.
Build intelligent, connected, and autonomous systems that operate in the real world.
Flexible engineering capacity with predictable delivery, ownership, and outcomes.
Uncover the transformative potential of digital and mobile solutions for your industry

 Last Updated: Jun 3, 2026
Jun 2, 2026
Last Updated: Jun 3, 2026
Jun 2, 2026  380
380  32 min. Read
32 min. Read



Key Takeaways
Most organizations deploying artificial intelligence face a bias problem that nobody is looking for until it is too late. A credit scoring model quietly denies qualified applicants at higher rates for certain demographics, creating adverse impact that can lead to regulatory exposure and legal liability. A clinical triage system deprioritizes patients from specific groups, raising operational risks and ethical concerns. A resume screening tool filters out candidates before a human ever sees their name, resulting in biased outcomes that violate employment law.
None of these systems were designed to discriminate; they were designed to be efficient. And that is precisely the problem.
Bias in AI systems does not announce itself. It hides inside training datasets, emerges from proxy variables that seem neutral on paper, and compounds with every retraining cycle. By the time it surfaces in a regulatory review, a legal claim, or a procurement audit, the cost of correction has multiplied well beyond what it would have taken to test for it during development.
The scale of this gap is significant. According to Grant Thornton’s 2026 AI Impact Survey of nearly 1,000 senior U.S. business leaders, 78% of executives lack strong confidence that their organization could pass an independent AI governance audit within 90 days. The survey also found that nearly half of leaders, around 46% said AI underperforms specifically because controls and compliance are not working.
Meanwhile, the responsible AI platform market is projected to grow from $2.22 billion in 2024 to $8.88 billion in 2026 alone which is a 31.9% jump in a single year, signaling that the market is moving fast precisely because most enterprises are not yet ready.
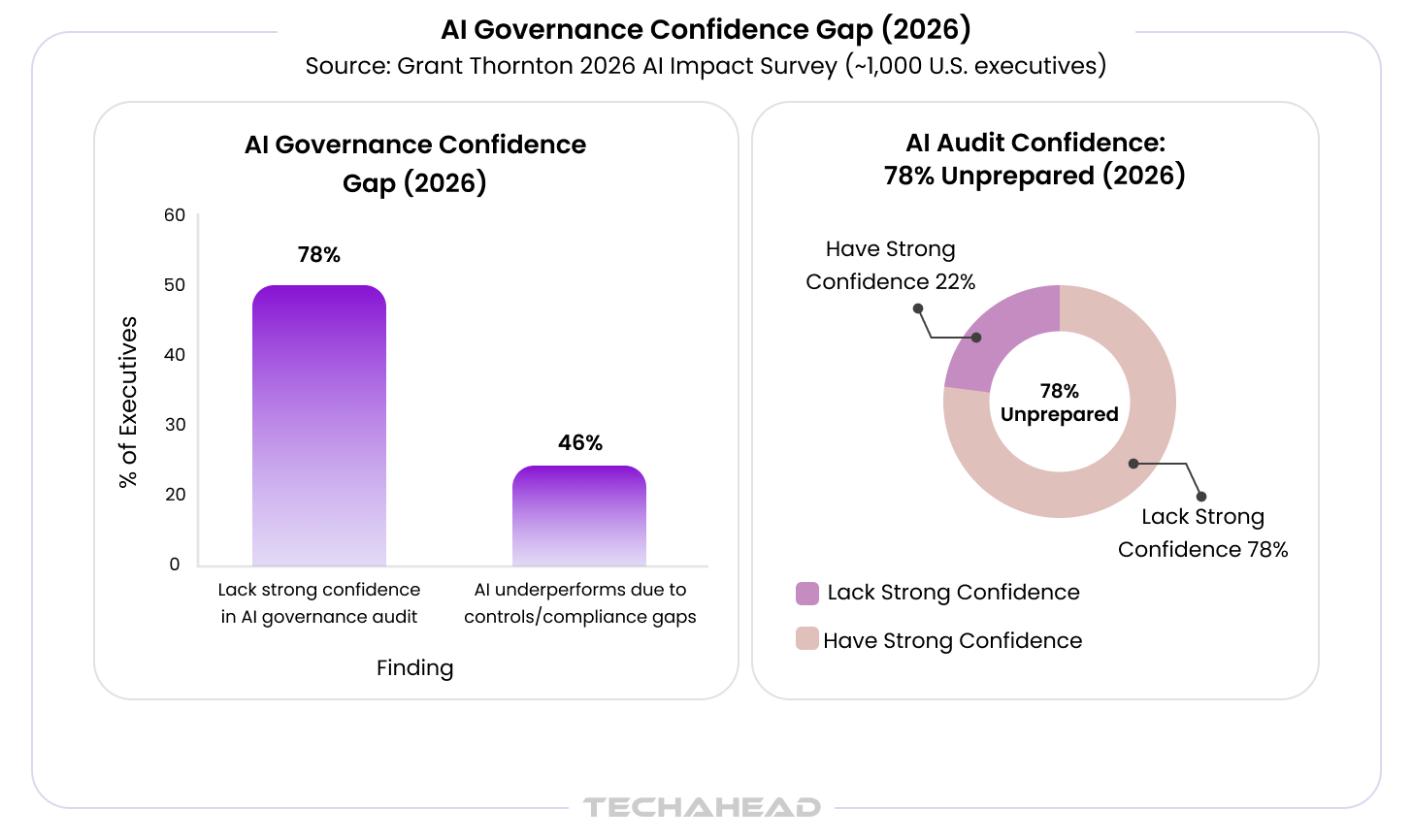
This blog is not a compliance checklist. It is a practical guide for CEOs, CTOs, and senior business executives who want to understand what AI bias audits actually involve, which bias testing methods enterprise teams use, what tools support the process, and most importantly – how to ensure the AI systems your team builds or procures are designed to be audit-ready from the start, not scrambled into shape after the fact.
Must Read: Enterprise AI Compliance & Governance: How to Proceed with it in 2026

An AI bias audit is a systematic, documented evaluation of whether an artificial intelligence system produces unfair or discriminatory outcomes for individuals based on protected characteristics, including race, gender, age, disability, and ethnicity. It measures whether the AI’s decisions – approvals, denials, scores, rankings, and recommendations differ across demographic groups at rates that indicate discrimination.
This is a distinct exercise from a security audit, a performance review, or a general quality assurance process. Those measure whether a system is functioning correctly. An AI fairness audit measures whether a correctly functioning system is producing equitable outcomes, and those are not the same questions. A model can achieve 94% accuracy overall while still systematically disadvantaging a specific demographic group. The aggregate metric will never surface that disparity.
Bonus Read: Why Does Enterprise AI Need Audit Trails?
It is also worth separating AI bias audits from AI validation testing from the outset, because enterprises frequently conflate the two.
| Dimension | AI Bias Audit | AI Validation Testing |
| Focus | Fairness across demographic groups | Functional accuracy and performance |
| Primary question | Who is disadvantaged by this output? | Does the model work correctly? |
| Regulatory driver | EU AI Act, EEOC, NYC Local Law 144 | ISO/IEC 42001, SOC 2 Processing Integrity |
| When conducted | Pre-deployment and ongoing | Primarily pre-deployment |
| Output | Bias audit report with disparity findings | Accuracy benchmarks and test logs |
Both are necessary. Neither replaces the other. When enterprises treat validation testing as a proxy for bias auditing, they are checking the wrong thing and regulators in 2026 know the difference.
Bias testing is also one of the eight required sections in a compliant AI model card under EU AI Act and ISO 42001 documentation standards. For more on that documentation framework, read our guide on AI Model Cards and Data Provenance.
The regulatory environment around algorithmic bias testing has shifted from guidance to enforcement in 2026. This is not a future risk enterprises can schedule for later. For organizations building or deploying AI healthcare solutions, or AI in lending, hiring, or any domain classified as high-risk under global frameworks, AI bias audit obligations are either active or imminent.
Here is where each major framework stands today.
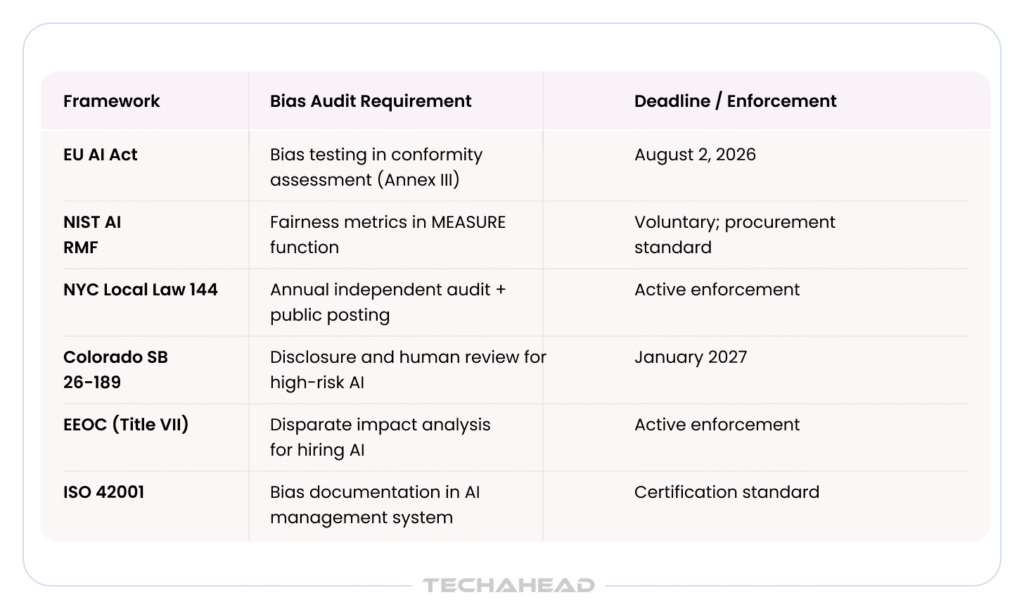
Article 10 of the EU AI Act explicitly mandates training data governance and bias screening for high-risk AI systems. Under Annex III, systems used in employment decisions, credit scoring, healthcare diagnostics via AI, and biometric identification must demonstrate disparate impact analysis as part of their conformity assessment. Full enforcement against high-risk AI systems begins August 2, 2026. Organizations that have not yet begun building bias testing documentation are already late. Penalties for non-compliance reach €15 million or 3% of global revenue.
The MEASURE function of the NIST AI Risk Management Framework names fairness metrics across protected classes as a required deliverable. While the framework remains voluntary, it has become the de facto standard for U.S. federal procurement and is referenced in an expanding set of enterprise customer security questionnaires. For a full implementation guide, see our NIST AI RMF Implementation blog.
New York City’s Local Law 144 requires any employer using automated employment decision tools to commission an annual independent algorithmic bias audit and publicly post the results on their website. There is no minimum employee threshold. A company with three employees using an AI hiring tool faces identical obligations to a Fortune 500 firm.
Colorado’s SB 24-205 was repealed in May 2026 before its effective date. Its replacement – SB 26-189 – shifts to a disclosure-and-human-review framework effective January 2027, removing formal bias audit requirements. However, discrimination liability under Title VII and the Colorado Anti-Discrimination Act remains fully intact for AI-assisted decisions.
The Equal Employment Opportunity Commission’s 2026 guidance extends Title VII disparate impact theory to AI hiring tools. Any automated system used in recruitment, screening, or promotion decisions is subject to analysis under the same disparate impact framework that has governed human employment decisions for decades.
The business cost of non-compliance runs well beyond regulatory fines. AI bias exposure creates class-action litigation risk, accelerates procurement losses when enterprise buyers request audit evidence you cannot produce, and generates the kind of reputational damage that does not resolve quickly.
Eighteen months ago, bias documentation was a nice-to-have in enterprise AI conversations. Today it is the first thing procurement teams ask for and the last thing most development companies can actually produce. The enterprises winning AI contracts in 2026 are not necessarily building smarter models, they are building models that can be proven fair.
Vikas Kaushik, CEO, TechAhead
The EU AI Act spoke in this cluster covers the full penalty structure in detail: EU AI Act Compliance Checklist.
Not all bias in AI systems originates from the same source. Enterprises that treat algorithmic bias as a single problem to test for once are consistently caught out by the types they did not look for. There are three primary categories that cause the most enterprise compliance failures and each requires a different testing approach.
Also Read: Top AI Security Risks & How to Prevent Them
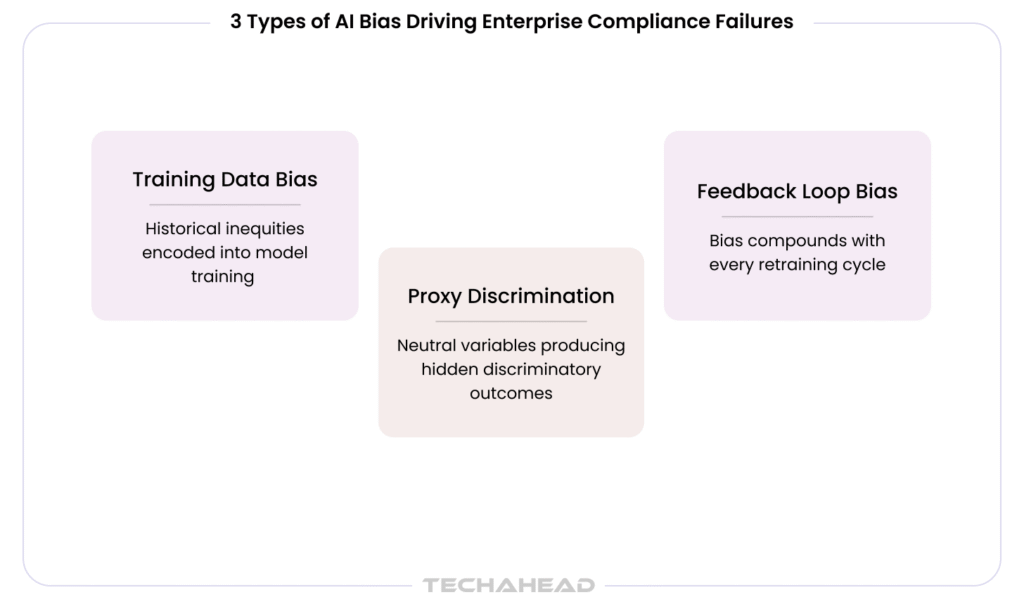
Training data bias occurs when the historical data used to train a model encodes past inequities. The AI does not invent discrimination – it learns it from the data it was trained on. One well-known example is Amazon’s AI hiring tool, which favored men because it was trained on biased historical hiring data. Similarly, a credit scoring model trained primarily on historical approval decisions from a period when lending discrimination was systemic will replicate those approval patterns at scale, regardless of how sophisticated the model architecture is.
A November 2025 academic review published by Real World Data Science confirmed this across financial algorithms, finding that female applicants received credit scores six to eight points lower than male counterparts with identical financial profiles – a disparity that persisted across multiple borrowing cycles. The source was not the algorithm’s logic. It was the data it learned from.
Training data bias is traceable – which is why data provenance documentation matters. Read more on that in our guide to AI Model Cards and Data Provenance.
Proxy discrimination is subtler and more dangerous precisely because it does not use protected attributes directly. Instead, the model uses seemingly neutral features – zip code, device type, browsing behavior, name – that correlate strongly with protected characteristics. The outcome is discriminatory, but the mechanism is hidden behind variables that appear legitimate.
A loan eligibility model that uses neighborhood-level data as a proxy for creditworthiness is not technically using race as an input. But if that neighborhood data correlates with race, which in many cities it does, as a direct legacy of historical redlining – the model produces racially discriminatory outcomes through a statistically clean-looking variable. Standard accuracy metrics will never surface this. It requires counterfactual testing to detect.
This is the type of bias most likely to survive a superficial audit and emerge later in regulatory enforcement or litigation.
Feedback loop bias is a compounding problem unique to AI systems that retrain on their own outputs. When a biased model’s decisions become the training data for the next model version, the bias does not stay static; it amplifies. Each retraining cycle makes the disparity larger and harder to reverse.
A 2024 University of Washington study analyzing over three million resume-job comparisons found that AI resume screening tools favor white-associated names 85% of the time. If those hiring decisions – skewed toward one demographic from the start, become the signal for the next model’s training, the next version learns from an even more skewed dataset. The bias does not self-correct through retraining. It self-reinforces.
This is why a clean pre-deployment AI bias audit is necessary but not sufficient. Feedback loop bias is a post-deployment problem that demands continuous monitoring to catch.
All three types require independent testing approaches. One methodology does not catch all three – which is precisely why bias testing methodology matters as much as audit completion.
Also Read: Responsible & Ethical AI
Understanding what an AI bias audit involves at the methodological level matters for every executive who will eventually sign off on one, procure a partner to build one in, or respond to a regulator asking how it was done. There are four primary methods enterprises use, and they address different bias types in different ways.

Disparate impact analysis is the primary statistical method for AI bias testing and the one most directly tied to regulatory thresholds. It measures whether an AI system produces significantly worse outcomes for a protected group relative to a comparison group.
The governing standard is the four-fifths rule (also called the 80% rule) – codified by the EEOC in its 1978 Uniform Guidelines on Employee Selection Procedures and referenced explicitly in NYC Local Law 144. The rule holds that if a protected group receives a positive outcome at less than 80% the rate of the highest-performing group, the disparity flags potential disparate impact.
To put that concretely: if an AI hiring tool advances 60% of Group A candidates and 40% of Group B candidates to the next stage, the impact ratio is 0.67 – below the 0.80 threshold, signaling a potential bias finding that would require documentation and mitigation before deployment.
The limitation is important to state clearly: satisfying the four-fifths rule does not guarantee fairness across all protected attributes or all decision contexts. It is a floor, not a ceiling. Multiple fairness metrics are required for a complete picture.
Subgroup performance analysis evaluates model accuracy, precision, recall, and error rates separately across demographic subgroups, rather than as an aggregate across the entire population.
This matters because aggregate metrics systematically hide disparity. A model can achieve 92% overall accuracy while producing 78% accuracy for one demographic group. The aggregate number looks strong. The subgroup number reveals a compliance problem. Regulators and auditors looking at aggregate metrics alone miss this entirely.
The fairness metrics applied in subgroup analysis include demographic parity (are positive outcome rates equal across groups?), equalized odds (are true positive and false positive rates equal across groups?), equal opportunity (are true positive rates equal for groups with the same actual outcome?), and predictive parity (are positive predictive values equal across groups?).
This is what the NIST AI RMF’s MEASURE function means in practice when it references “fairness metrics across protected classes.” See our NIST AI RMF Implementation guide for how the MEASURE function fits into a broader risk management program.
Counterfactual testing changes only a protected attribute in an otherwise identical input and measures whether the model output changes. If two identical loan applications differ only in applicant name – with one name statistically associated with one racial group and another with a different group – and approval odds differ between them, proxy discrimination is present.
Counterfactual testing is the most effective method for detecting proxy discrimination that disparate impact analysis misses, because it directly interrogates whether protected attributes, including their proxies, are influencing the model’s outputs. It requires careful construction of test pairs that are realistic and statistically valid, which is where development-stage bias testing has a significant advantage over post-deployment audits – the model’s feature set and training data are accessible.
Adversarial probing and red-teaming involve systematically constructing edge-case and worst-case inputs designed to expose bias behaviors that statistical methods cannot capture. A standard next step is to examine the AI model’s structure, especially in systems that reply on machine learning, before interpreting edge-case behavior exposed by adversarial testing. This is particularly important for large language models and generative AI systems, where bias manifests not just in binary decisions but in tone, framing, recommendation quality, and the nature of generated content across demographic groups.
Related: Build an Enterprise AI Roadmap in 90 Days
A model that produces confident, detailed responses when asked to describe the achievements of one demographic group and hedged, vague responses for another is exhibiting bias – but no disparate impact ratio will surface it. Adversarial probing will.
Human review is essential in interpreting red-team outputs. Statistical tools can flag anomalies; human judgment determines which anomalies are bias-driven and which require remediation. This is one of the points where human-in-the-loop design and AI bias auditing intersect directly.
| Bias Type | Primary Method | Supporting Method | Output Metric |
| Training data bias | Subgroup performance analysis | Dataset demographic audit | Representation ratio |
| Proxy discrimination | Counterfactual testing | Feature correlation analysis | Disparate impact ratio |
| Feedback loop bias | Longitudinal subgroup tracking | Model drift monitoring | Performance delta over time |
| LLM / GenAI bias | Adversarial probing / red-teaming | Output distribution analysis | Tone and recommendation parity |
Also Read: LLM Observability into Enterprise AI Systems

No single tool handles all AI bias audit requirements across all machine learning model types and all bias categories. Enterprise teams work with a combination of open-source fairness libraries, explainability and inspection AI tools, and continuous monitoring platforms, applied at different stages of the AI development and deployment lifecycle as an integral part of a broader responsible AI program.
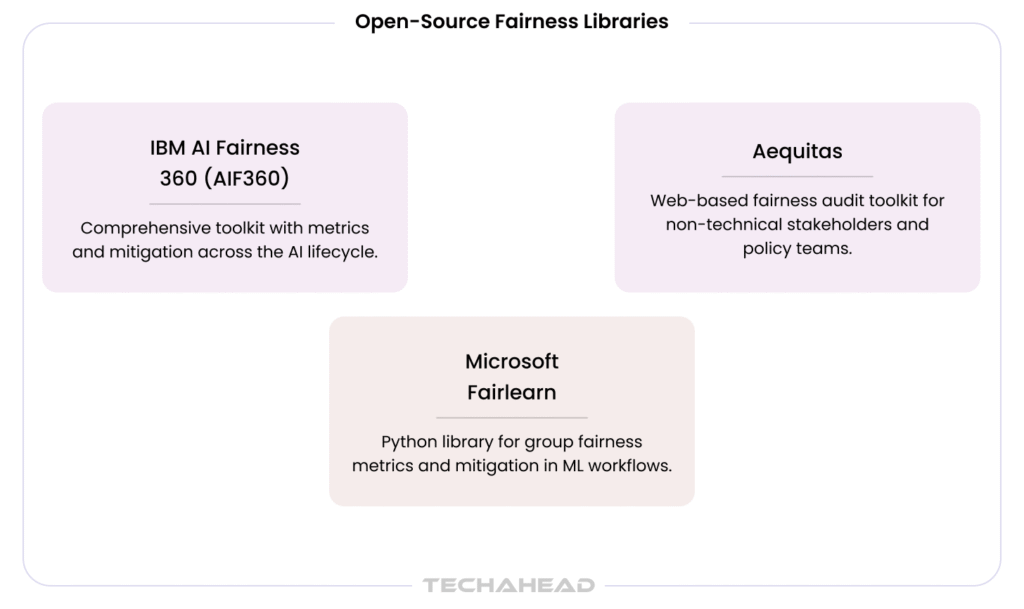
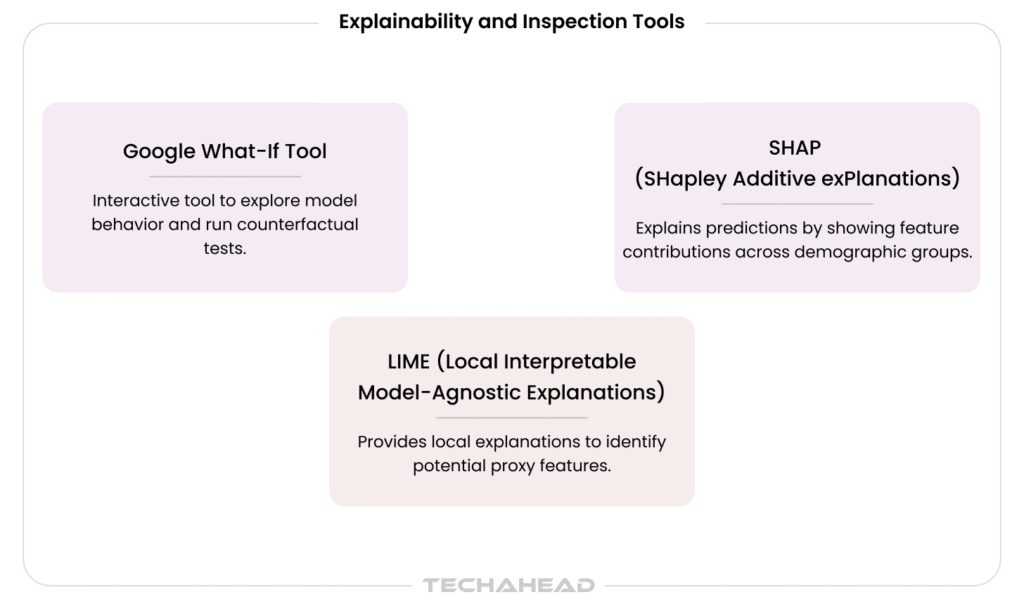
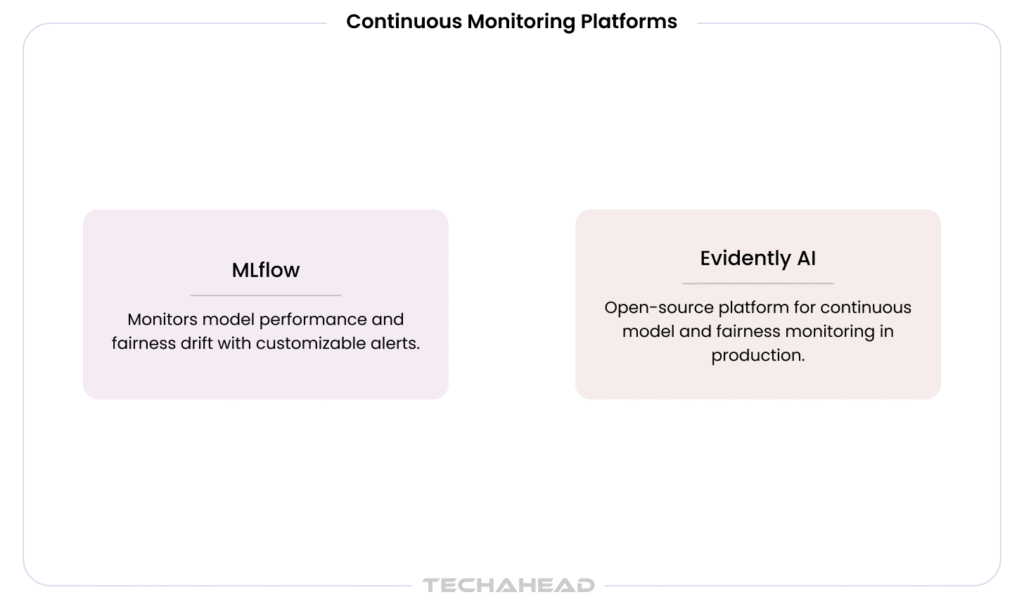
TechAhead integrates open-source fairness libraries into CI/CD pipelines during model development, ensuring bias metrics are tracked from the first training run rather than assessed retroactively ahead of a regulatory deadline. The tools listed above are part of that pipeline, not applied as standalone auditing instruments after a model is already in production.
An AI bias audit that produces no documentation is not an audit but a test. The documentation is the evidence. Regulators, enterprise procurement teams, and auditors do not want to know that bias testing happened. They want to see what was tested, how it was tested, what was found, with the final step being a detailed report of findings, and what was done about it.
A complete AI audit report contains seven core elements. Understanding what they are matters for any executive evaluating whether an AI development partner is producing audit-ready systems or just running tests.
1. System Description and Intended Use
What the AI system does, who it affects, what categories of decisions it influences, and which populations it operates on. This maps directly to EU AI Act Annex IV technical documentation requirements and is the foundation every regulatory reviewer starts with.
2. Protected Attributes Tested
Which demographic categories were included in the audit (race, gender, age, disability, ethnicity, and others depending on jurisdiction and use case), and how demographic data was sourced or inferred where self-declared data was unavailable.
3. Testing Methodology
Which bias testing methods were applied, at what stage of development, with what statistical parameters, and using which tools. A methodology section that says “bias tested” without specifying how is not compliant documentation under NYC Local Law 144, EU AI Act Annex IV, or NIST MEASURE requirements.
4. Fairness Metrics and Thresholds
Numerical results for each metric applied – disparate impact ratio, demographic parity difference, equalized odds gap, with explicit comparison to regulatory thresholds such as the four-fifths rule. Pass/fail labels are insufficient. Regulators want the numbers.
5. Findings and Identified Disparities
Specific subgroups where performance or outcome disparities were detected, with statistical significance noted and the bias type identified (training data, proxy, or feedback loop). This is where audit findings should clearly show what was observed and why it matters. This is the section NYC Local Law 144 requires employers to publicly post on their websites.
6. Bias Mitigation Actions
What was done to address identified bias: dataset rebalancing, feature removal, threshold adjustments, model retraining on augmented data. Each action should be documented with its effect on the relevant metrics.
7. Residual Risk Statement
What algorithmic bias risk remains after mitigation, with rationale for why that residual level is acceptable given the use case and regulatory context. This is required for EU AI Act high-risk conformity assessments and ISO 42001 documentation, and it is the element most frequently missing from bias audit reports produced by teams who approached the exercise as a checkbox rather than a systematic evaluation.
| Report Element | EU AI Act Annex IV | NIST MEASURE | ISO 42001 | NYC LL144 |
| System description | Required | Required | Required | Required |
| Protected attributes tested | Required | Required | Required | Required |
| Testing methodology | Required | Required | Recommended | Required |
| Metrics and thresholds | Required | Required | Required | Required |
| Findings and disparities | Required | Required | Required | Required |
| Public post required | N/A | N/A | N/A | N/A |
| Mitigation actions | Required | Required | Required | Recommended |
| Residual risk statement | Required | Required | Required | Optional |
This documentation connects directly to the broader AI audit trail and model card framework that high-risk AI systems require. For more on that documentation structure, read our guide on SOC 2 for AI Systems.
Here is where the development company framing matters most. Responsible AI development does not treat AI bias audits as a compliance event that happens before launch. It treats bias testing as a continuous quality discipline that runs from the first line of data engineering through every model update in production.
The argument is straightforward. IBM’s AI governance research and enterprise AI audit practitioners consistently find that retrofitting bias testing post-deployment costs four to five times more than embedding it during development. A model that reaches production with undocumented bias is not just a compliance risk but also a remediation project that pulls engineering resources, delays go-live timelines, and in regulated industries, may require regulatory notification before the fix is even deployed.
The right approach operates across three phases.
Before a single training run begins, the dataset itself should be audited for demographic representation. This means identifying which protected groups are present in the training data, which are underrepresented, which are absent, and whether historical decisions in the dataset encode past discrimination. Underrepresented groups produce models with lower accuracy for those populations and lower accuracy for one group almost always translates into disparate impact findings later.
Data provenance documentation – tracking every dataset’s source, collection methodology, known limitations, and demographic composition, is the foundation for defensible AI bias audit reports downstream. This work happens before the model exists, which means it must be part of how an AI development team sets up a project, not something asked for by compliance after the model is already trained.
Where real world data is insufficient or biased, synthetic data generation techniques can be used to augment datasets to improve representation and reduce bias. Synthetic data must be carefully validated to avoid introducing new risks or distorted distributions that could lead to biased outcomes.
Fairness metrics should be tracked alongside accuracy metrics from the first training run, not introduced at the evaluation stage. This means identifying and reviewing data sources for representation and signs of historical discrimination, then monitoring how model decisions affect outcomes in context. When disparate impact ratio and demographic parity difference are monitored throughout model development, teams catch bias patterns early (when they are still correctable through data adjustments, feature engineering, or architecture changes), rather than discovering them in a pre-deployment audit where the only option is retraining from scratch. Incomplete data can distort representation and lead to unfair downstream outcome
Bias testing integrated into CI/CD pipelines means every model version is evaluated for fairness automatically. Counterfactual testing runs during model evaluation as a standard step, not a special exercise. Adversarial probing is part of the testing suite before any model is promoted to staging. And when statistical tools flag edge cases that require human judgment to interpret, those cases are routed to human reviewers as part of the normal evaluation workflow to reduce bias, rather than being surfaced for the first time during a regulatory audit.
“When we onboard an AI project, fairness metrics go into the pipeline configuration before the first training job runs, not as an afterthought and not as a pre-launch checklist. I have reviewed bias audit reports from other vendors where the counterfactual tests were run three days before delivery. You can tell. The documentation is thin, the edge cases are missing, and the residual risk statement is a paragraph of legal hedging. That is not a bias audit. That is paperwork.”
Deepak Sinha, CTO, TechAhead
A clean pre-deployment AI bias audit does not protect against feedback loop bias or the demographic shifts that change how a model performs in production over time. Post-deployment monitoring for fairness metrics is what separates organizations that maintain audit readiness from those who pass their first audit and fail the second.
Re-audit triggers should be defined in advance and built into the monitoring infrastructure: a significant model update, the introduction of a new user demographic, a regulatory change that expands protected categories, or a performance disparity alert that crosses a defined threshold. Annual re-audits are the minimum standard under NYC Local Law 144. Quarterly re-audits are appropriate for high-risk systems. Any model retraining, for any reason, should trigger at minimum a targeted bias check on the affected decision pathways.
For the executive evaluating an AI development partner, here are the specific questions worth asking before a project begins.
These are not difficult questions for a development team that builds bias-tested AI as a standard practice. They are very difficult questions for a team that treats bias testing as a delivery milestone rather than a development discipline.
TechAhead’s 240+ engineers embed bias testing into AI development lifecycles through automated fairness metric tracking, ISO 42001-aligned documentation, and CI/CD-integrated bias screening as part of our role as an enterprise AI development company. Our SOC 2 Type II certification validates that these controls operate as designed across every production AI system we deliver – not as assurances, but as audited evidence.
While the general AI bias audit framework applies across industries, specific sectors carry additional testing standards and documentation requirements that go beyond the baseline four-fifths rule. Enterprises building or procuring AI in these sectors need to understand where the obligations are more prescriptive, not just more general.
Financial services AI systems face the most extensive bias documentation requirements of any commercial sector. Credit scoring, loan approval, fraud detection, and insurance underwriting models must satisfy fair lending examiners under the Equal Credit Opportunity Act (ECOA) and the Fair Housing Act – both of which apply disparate impact analysis to AI-assisted decisions.
Backtesting must demonstrate error rates below 5% across demographic groups. EBA and ECB guidelines in Europe add AI bias testing obligations for banking institutions operating across EU jurisdictions, including for connected AI and IoT modrnization initiatives.
Healthcare AI systems classified as high-risk under EU AI Act Annex III (clinical triage, diagnostic support, patient risk scoring) must demonstrate subgroup performance analysis across age, race, gender, and disability status. The standard for explainability in clinical AI is high: 95% explainability is the threshold referenced in healthcare AI governance frameworks.
Algorithmic bias in healthcare carries consequences that extend beyond regulatory fines – a diagnostic model that performs less accurately for one demographic group is a patient safety issue. Our HIPAA-Compliant AI Architecture guide covers the full architecture requirements for healthcare AI.
HR and recruitment AI faces the most active enforcement landscape in 2026. These audits help prevent harmful discrimination against protected classes and reduce unfair decisions affecting certain groups throughout the hiring process. Resume screening tools, candidate ranking systems, and AI-assisted performance evaluations are under scrutiny simultaneously from NYC Local Law 144, Colorado SB 24-205, EEOC guidance, and for EU employers – the EU AI Act’s classification of employment AI as high-risk under Annex III. Annual independent algorithmic bias audits are mandatory in New York City with no minimum size threshold, and employers should test outcomes across job titles to detect measurable gender bias.
A 2024 University of Washington study found that AI resume screening tools favor white-associated names 85% of the time across a dataset of over three million resume-job comparisons – a finding that illustrates why enforcement activity in this sector is accelerating. Regular audits also can enhance trust with users and stakeholders, help avoid costly legal liabilities tied to discriminatory outcomes, and can reduce exposure to financial penalties.
| Sector | High-Risk AI Use Cases | Bias Testing Standard | Key Regulation |
| Healthcare | Clinical triage, diagnostics, patient risk scoring | Subgroup analysis across age, race, gender; 95% explainability | EU AI Act Annex III, HIPAA, FDA |
| Financial Services | Credit scoring, loan approval, fraud detection, insurance | Four-fifths rule; ECOA disparate impact; backtesting <5% error | Fair Lending, SR 11-7, CFPB, EBA guidelines |
| HR / Recruitment | Resume screening, candidate ranking, performance scoring | Annual independent audit; four-fifths rule mandatory | NYC LL144, Colorado SB 26-189 (eff. Jan 2027), EEOC |
For detailed coverage of high-risk AI classification across these sectors, see our EU AI Act Compliance Checklist.
The direction of AI bias audit requirements is clear: more jurisdictions, more frequency, more specificity, and higher expectations for what counts as sufficient documentation.
New York City’s Local Law 144 has become the regulatory template. California, Illinois, Colorado, and New Jersey are all at varying stages of adopting similar algorithmic bias testing mandates. At the federal level, EEOC enforcement activity is extending the reach of Title VII disparate impact theory into AI hiring tools regardless of whether state-level AI laws apply.
Internationally, South Korea’s AI Framework Act, effective January 2026, specifically mandates fairness and non-discrimination requirements in healthcare AI. Japan passed its first AI-specific Basic Act in May 2025. The EU AI Act’s provisions for General-Purpose AI models extend bias obligations to foundation model providers, not just deployers – which means enterprises using external AI APIs and foundation models will need to evaluate the bias documentation of those models, not just their own fine-tuned outputs.
Point-in-time AI bias audits are giving way to continuous auditing as the expected standard. ISO 42001 certification – already cited by 36% of organizations as a regulatory influence in Stanford HAI’s 2026 AI Index – is becoming a procurement prerequisite in enterprise contracts, with bias documentation a core artifact in the certification evidence set.
For organizations building or procuring AI in 2026, the window for treating AI bias auditing as a future-state concern has already closed.

TechAhead builds AI systems for enterprises that need to operate in regulated environments, win procurement cycles, and scale with confidence. That means bias testing is not a pre-launch checklist item but an architectural commitment built into every model we deliver, from the data engineering phase through production monitoring.
Our ISO 42001:2023 certification, SOC 2 Type II, and ISO 27001:2022 certifications are audited evidence of how we build, not just what we claim. Enterprise clients including AXA, JLL, American Express, Audi, Waresport, and ESPN F1 have trusted TechAhead to deliver production AI systems that perform under audit scrutiny, not just in demos.
If you are evaluating an AI development partner for a system that will need to satisfy EU AI Act conformity assessments, pass NIST AI RMF reviews, or hold up under EEOC or NYC Local Law 144 requirements, the question is not whether bias testing will be needed. The question is whether it will be built in from the start or scrambled together before a regulatory deadline.
Contact TechAhead to discuss building responsible AI with bias-tested architecture from day one.
An AI bias audit is a structured evaluation that tests whether your AI system produces discriminatory outcomes across demographic groups – race, gender, age, disability. For enterprises, it is the difference between a defensible AI deployment and a regulatory or litigation liability.
AI validation testing checks whether a model works correctly. An AI fairness audit checks whether a correctly working model treats everyone equitably. A model can pass all accuracy benchmarks and still fail a bias audit – aggregate metrics routinely hide subgroup disparities.
Several. The EU AI Act mandates bias testing for high-risk AI systems from August 2, 2026. NYC Local Law 144 requires annual independent algorithmic bias audits for employment AI. EEOC enforcement extends disparate impact analysis to AI hiring tools. ISO 42001 makes bias documentation a certification requirement.
No, and this is where many enterprises get caught out. If you deploy a vendor’s AI tool in your hiring or lending workflow, the compliance obligation stays with you – the employer or deployer of record. You need audit documentation for every AI tool in your stack, regardless of who built it.
Annually at minimum – that is the NYC Local Law 144 standard. High-risk AI systems warrant quarterly reviews. Any model retraining, new demographic entering your user base, or significant regulatory change should also trigger a targeted bias check, not just a scheduled one.
Seven elements: system description and intended use, protected attributes tested, testing methodology with statistical parameters, fairness metrics and thresholds with actual numbers, findings and identified disparities, bias mitigation actions taken, and a residual risk statement. Pass/fail labels alone do not satisfy EU AI Act, NIST, or NYC LL144 requirements.
Depends on the regulation. NYC Local Law 144 explicitly requires an independent third-party auditor, and internal teams do not qualify. For EU AI Act conformity assessments and ISO 42001, internal testing is permissible for most Annex III systems, provided the methodology is rigorous and documented. However, enterprise procurement teams and courts consistently treat third-party verified results as more credible than self-reported bias testing.
The four-fifths rule – also called the 80% rule, states that if a protected group receives a positive outcome at less than 80% the rate of the best-performing group, it signals potential disparate impact. It is the primary regulatory threshold in disparate impact analysis and is referenced explicitly in NYC LL144 and EEOC guidance. It is a floor, not a ceiling – satisfying it does not mean your system is fully fair.
Algorithmic fairness testing embedded during development runs fairness metrics alongside accuracy metrics from the first training run, integrates counterfactual testing into model evaluation, and tracks subgroup performance through every model version. The result is audit documentation that exists when a regulator asks for it, not assembled retrospectively before a deadline.
Ask whether they track fairness metrics from the first training run, which bias testing methods they apply beyond the four-fifths rule, how their documentation maps to EU AI Act Annex IV requirements, whether their deployment pipelines include fairness metric drift alerts, and whether they can share a sample AI bias audit report section from a comparable project. If they cannot answer all five, the system they build will not be audit-ready.
We use cookies to ensure our website functions properly, improve performance, and provide a personalized experience. You can choose which types of cookies to allow below.
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Help us understand site traffic and user interactions so we can improve performance and usability.
Enable enhanced functionality and personalization such as language or region preferences.
Used to deliver relevant ads, track campaign performance, and measure advertising effectiveness.