

















 Copy Link
Copy Link Share on X
Share on X Share on Facebook
Share on Facebook Share on LinkedIn
Share on LinkedIn


Always Active
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Build intelligent AI systems that automate decisions, accelerate innovation, and scale business growth.
Design, build, modernize, and scale digital products that drive business growth.
Build secure, scalable, and intelligent platforms that power modern enterprises.
Build intelligent, connected, and autonomous systems that operate in the real world.
Flexible engineering capacity with predictable delivery, ownership, and outcomes.
Uncover the transformative potential of digital and mobile solutions for your industry

 Last Updated: Mar 23, 2026
Feb 28, 2024
Last Updated: Mar 23, 2026
Feb 28, 2024  3246
3246  10 min. Read
10 min. Read



Key Takeaways
Data is a valuable asset to streamline effective decision-making, and businesses strive to harness the power of their data for powering up analytics and forming predictive models. Data warehousing, in particular, plays a pivotal role in modern businesses by centralizing and organizing data for analytical purposes. Amazon Redshift is a fully managed data warehouse service on AWS that stands out as a robust solution for organizations seeking to streamline their data warehousing processes.
Let’s deeply dive into Amazon Redshift and uncover its key features and benefits, including its massively parallel processing (MPP) architecture, columnar storage format, and integration with other AWS services.
Amazon Redshift, introduced by AWS, is a cloud-based, fully managed data warehouse service designed for high-performance analysis. The petabyte-scale system is built on a PostgreSQL base, which includes advanced features and optimizations to deliver high-performance analytics for businesses of all sizes. For organizations looking to maximize the potential of Amazon Redshift, AWS Cloud Consulting Services can provide expert guidance, helping businesses optimize their data workflows and analytics strategies.
The technology leverages a combination of machine learning and a columnar storage format that offers the scalability and speed needed to handle large datasets efficiently. Here are some of the best features and capabilities of Amazon Redshift:
 MPP is where massive data sets are processed parallelly, resulting in increased efficiency of the data processing systems. Amazon Redshift distributes query execution across multiple nodes, allowing for parallel processing and faster query performance leading to improved scalability for handling large data sets, increasing both storage and processing power.
MPP is where massive data sets are processed parallelly, resulting in increased efficiency of the data processing systems. Amazon Redshift distributes query execution across multiple nodes, allowing for parallel processing and faster query performance leading to improved scalability for handling large data sets, increasing both storage and processing power.

Unification of Data with Zero-ETL
Amazon Redshift facilitates the unification of diverse datasets without the need for extensive Extract, Transform, Load (ETL) processes. This is achieved through its ability to directly query and analyze data in various formats, such as CSV, Parquet, ORC, and more, without pre-processing or transforming the data beforehand. This feature streamlines the data integration process, allowing users to analyze disparate datasets seamlessly within the Redshift environment. This zero-ETL approach accelerates the time-to-insight by eliminating the complexities associated with traditional data integration.
Utilizes Comprehensive Analytics and Machine Learning
Redshift offers comprehensive analytics capabilities, enabling users to perform complex analytical queries on large datasets. With support for advanced analytics and machine learning (ML) through integration with tools like Amazon SageMaker, users can derive valuable insights from their data.
Redshift’s extensibility allows for the integration of custom machine-learning models, enhancing the platform’s capabilities in predictive analytics and data-driven decision-making. The platform’s compatibility with various BI (Business Intelligence) tools further maximizes its value by providing users with flexible options for data visualization and reporting.
Streamlines Rapid Innovation with Secure Data Collaboration
Amazon Redshift promotes secure and collaborative practices that allow users to share and collaborate on data securely through features such as fine-grained access controls, encryption at rest and in transit, and Virtual Private Cloud (VPC) isolation.
The platform supports data sharing across different Redshift clusters, enabling organizations to innovate faster by fostering a collaborative data environment. Redshift’s integration with AWS Identity and Access Management (IAM) ensures that data access is controlled and auditable, providing a secure foundation for collaborative analytics and innovation.
Automatic Workload Management (AWM)
Amazon Redshift dynamically allocates resources to queries based on its workload requirements to ensure optimal performance as critical queries receive the necessary resources. This is done through query queuing that analyzes all queries submitted and allocates resources fairly among them. Queries are placed in a queue and processed in the order they are received, preventing resource contention and ensuring no single query monopolizes the cluster resources.
Concurrency Scaling is a feature within AWM that allows Redshift to automatically add additional computing resources (such as extra compute nodes) to handle increased query concurrency. When the cluster experiences high demand, the scaling system automatically provisions additional resources to ensure efficient query processing. The Redshift architecture will be explained in more detail in the below sections.
Optimal Price-Performance for any Analytics Scale
Redshift is designed to deliver optimal price performance, allowing organizations to scale their data warehouse infrastructure according to their needs. Users can easily resize their Redshift clusters, adding or removing nodes to match the evolving demands of their analytical workloads.
The best advantage of Redshift is that it offers features like automatic workload management, which optimizes query performance by dynamically allocating resources based on the workload requirements. This ensures that users achieve the best price-performance ratio, making Redshift cost-effective for both small-scale and large-scale data analytics.
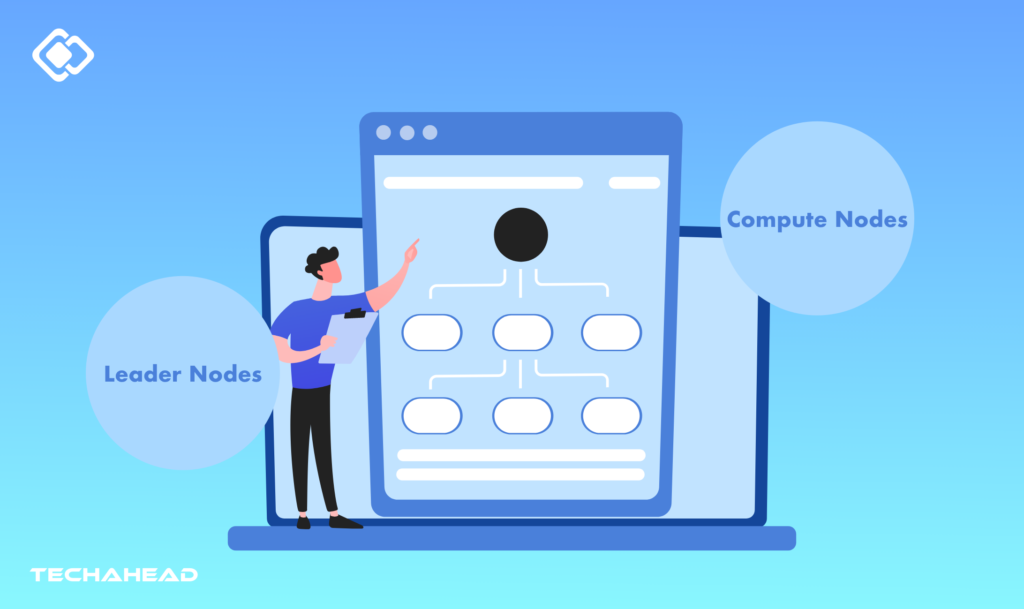
Amazon Redshift is made on a cluster-based architecture that is a collection of nodes working simultaneously to process queries and store data. The data is distributed evenly across all nodes, which makes parallel processing possible and allows efficient data retrieval when a query is executed. Here are the 2 main types of nodes that Redshift architecture comprises:
Leader Nodes
These are nodes that manage queries within the database, distributing workloads to other types, known as compute nodes. They aggregate the results but do not store any data as they solely focus on query coordination and optimization, promoting efficient data management.
Compute Nodes
Compute nodes are responsible for handling the actual processing of queries and storing data. The more compute nodes a cluster architecture contains, the better the performance of the system and the more the storage capacity.
Amazon Redshift Data Loading
Amazon Redshift supports various methods for loading data into its data warehouse, catering to several use cases and preferences. Some common methods include:
Amazon S3 Integration
Amazon S3 is a scalable and highly durable object storage service from where users can load their data into Redshift. This involves copying data files stored in S3 buckets directly into Redshift tables. This method is handy for large-scale data loading and is often preferred for its simplicity and efficiency.
COPY Command
The “COPY” command is a powerful tool for bulk-loading data into Redshift. It allows users to efficiently load large amounts of data from various sources, including Amazon S3, Amazon EMR, or data stored on local machines. The “COPY” command can handle parallel data loading, improving the speed of the process.
Data Migration Services (DMS)
Data Migration Services (DMS) is a great service provided by Amazon AWS that supports migrating data from various sources, including on-premises databases, to Amazon Redshift. This is helpful when transitioning from existing data infrastructure to Redshift.
Data Pipeline Services
AWS Data Pipeline allows users to create, schedule, and manage data pipelines for automated data movement and transformation. It can be configured to move and transform data between different AWS services, providing flexibility and automation in data-loading workflows.

Amazon Redshift can seamlessly integrate with several AWS services, enhancing its capabilities and providing a comprehensive data processing ecosystem. Key integration includes:

Table structures must be fine-tuned for efficiency, carefully considering distribution keys aligned with common joins, optimized sort keys, and effective column compression. Regular execution of “VACUUM” and “ANALYZE” commands, coupled with query tuning and the use of materialized views, contributes to optimal performance. Concurrency Scaling and partitioning large tables based on relevant criteria further enhance efficiency.

Read about the robust security elements featured by Amazon Redshift in the cloud-based data warehouse to safeguard data:
Network Isolation
The Redshift clusters mentioned above operate in a Virtual Private Cloud (VPC), providing network isolation that ensures secure communication by controlling inbound and outbound traffic.
Encryption
SSL/TLS is used to encrypt the data in transit, securing communication between clients and Redshift clusters. Apart from that, data at rest is encrypted using AWS Key Management Service (KMS), providing an additional layer of protection.
Authentication Mechanisms
AWS Identity and Access Management (IAM), database user authentication, and temporary session tokens are authentication mechanisms supported by Amazon Redshift. Furthermore, Role-based access controls (RBAC) manage user privileges by enabling fine-grained authorization.
Audit Logging
Audit logs such as login attempts, queries, and changes to the database schema are all maintained by Redshift, which enables admins to monitor and analyze user activities for security and compliance.
Challenges and Considerations Concerned with Amazon Redshift
Organizations using Amazon Redshift may face challenges related to query performance, data loading times, and cost management. Large datasets and complex queries can impact performance, and loading significant data volumes may be time-consuming. Cost optimization while ensuring efficient performance is an ongoing consideration.
Strategies to address these challenges include thoughtful selection of sort and distribution keys, activation of concurrent scaling, and efficient use of data compression to reduce storage costs. Regular maintenance, including executing VACUUM and ANALYZE commands, is essential for maintaining optimal performance. Query optimization through regular review and refinement is also crucial.
To sum up, Amazon Redshift is a complete pack data warehousing solution on AWS that allows organizations to unlock the real potential of their data. The robust cluster architecture and innovative features seamlessly integrating with other AWS services make Amazon Redshift the leader in cloud-based data warehousing.
Businesses, irrespective of size or industry, can leverage Amazon Redshift to innovate faster, gaining insights that drive strategic decision-making. This is a result of optimal scalability, cost-effectiveness, and ease of use that makes Redshift a compelling choice for modern data management.
Can Amazon Redshift be used as a data warehouse?
Amazon Redshift’s MPP architecture, columnar storage, and seamless integration with other AWS services make it a reliable data warehouse as it provides unmatched performance, scalability, and cost-effectiveness. This makes it an ideal solution for modern businesses seeking efficient data management and analytics.
How does Amazon Redshift simplify the data-loading process?
Amazon Redshift offers multiple methods for data loading, including the “COPY” command, AWS Glue, and Data Pipeline integration. This simplifies the data loading process, ensuring flexibility and efficiency in managing and analyzing large datasets.
Can Amazon Redshift handle growing datasets and varying workloads?
Absolutely. Amazon Redshift’s scalable architecture allows businesses to expertly handle growing datasets, adjusting resources as they are needed. Its pay-as-you-go pricing model ensures optimal cost management, making it suitable for organizations with varying workloads.
How does Amazon Redshift contribute to secure data collaboration?
Secure data collaboration is promoted through Redshift’s integration with popular AWS services, ensuring encrypted data storage and access controls. This collaborative environment helps teams derive valuable insights while maintaining high standards of data security and compliance.
We use cookies to ensure our website functions properly, improve performance, and provide a personalized experience. You can choose which types of cookies to allow below.
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Help us understand site traffic and user interactions so we can improve performance and usability.
Enable enhanced functionality and personalization such as language or region preferences.
Used to deliver relevant ads, track campaign performance, and measure advertising effectiveness.