

















 Copy Link
Copy Link Share on X
Share on X Share on Facebook
Share on Facebook Share on LinkedIn
Share on LinkedIn
Always Active
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Build intelligent AI systems that automate decisions, accelerate innovation, and scale business growth.
Design, build, modernize, and scale digital products that drive business growth.
Build secure, scalable, and intelligent platforms that power modern enterprises.
Build intelligent, connected, and autonomous systems that operate in the real world.
Flexible engineering capacity with predictable delivery, ownership, and outcomes.
Uncover the transformative potential of digital and mobile solutions for your industry

 Last Updated: Jul 29, 2026
Jun 24, 2026
Last Updated: Jul 29, 2026
Jun 24, 2026  214
214  26 min. Read
26 min. Read



Key Takeaways
When a bank or digital lender decides to put AI inside a risk model, the default instinct is almost always the same: reach for the biggest, most capable model on the market. GPT-class reasoning, billions of parameters, etc. It feels like the safer choice. It is also, for the specific job of financial risk modeling, frequently the wrong one.
This is the build decision most fintech leaders get wrong, and it’s worth pulling apart on its own, because the consequences rarely show up in a pilot. They show up in production:
Most of the public conversation around small language models in banking and small language models in financial services so far has centered on customer-facing chatbots and document processing. The global small language model market itself is projected to grow from roughly $7.8 billion in 2023 to $20.7 billion by 2030, according to Grand View Research, and risk management already holds a dominant share of AI investment within BFSI specifically. Risk modeling is where the SLM vs LLM decision actually carries the highest stakes, because the model sitting behind a risk score isn’t just generating text, it’s making or shaping a decision that has to hold up at audit, at scale, and at the speed the transaction demands.
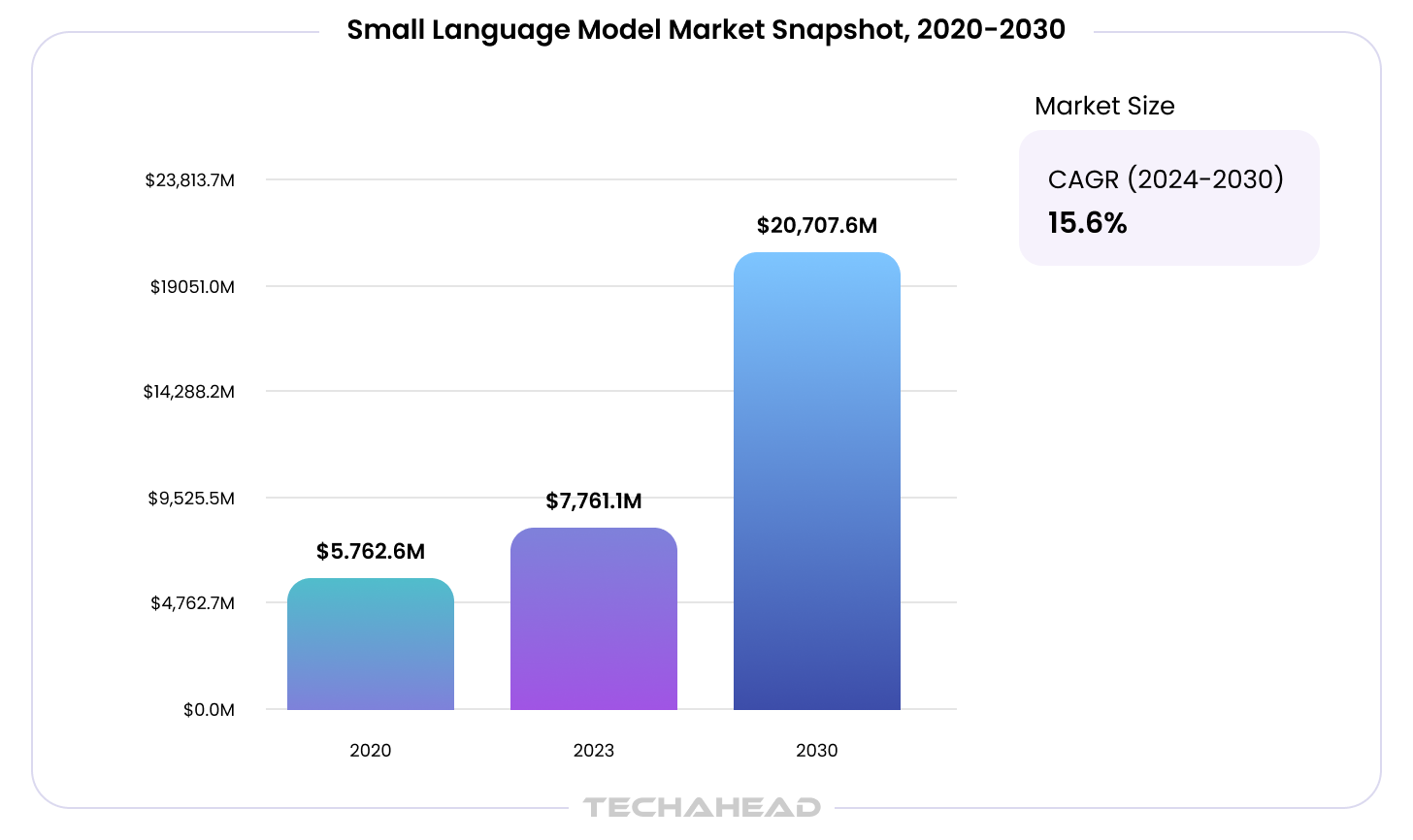
Regarding AI risk modeling in fintech, the live question is architectural: which model, at what size, doing which job. A 2025 position paper by NVIDIA researchers, published via Cornell University’s arXiv preprint server, lays out an argument that’s becoming hard to ignore: small, narrowly trained models aren’t a compromise, they’re frequently the better engineering choice for the repetitive, bounded, latency-sensitive tasks that make up most of what a production agent actually does, including most of what a risk function needs on any given day. Small language models are that argument applied specifically to financial risk modeling, forming a stronger risk management apparatus that aligns with rigorous risk modeling principles.
Related: Vertical AI Agents in FinTech

The case for small language models in risk modeling rests on three mechanics, and none of them have much to do with how “smart” the model is on a leaderboard: to define risk modeling in practical terms, it is the process of identifying, assessing, and mitigating hazards from AI systems, and effective frameworks combine scenario building with risk estimation, integrating probabilistic and deterministic requirements.
A credit authorization, a real-time fraud probability score, an intraday limit check, all of these need an answer inside a transaction window measured in milliseconds, not the multi-second round trip a large, cloud-hosted model typically takes to reason through a prompt. Security pressure is rising too, with 96% of leaders saying generative AI increases the likelihood of a security breach. Low-latency models also make it practical to run rapid what-if simulations on transaction interventions and test mitigation strategies across advanced AI scenarios without slowing live decisioning.
Mastercard’s own published results for its Decision Intelligence Pro fraud-scoring model are a useful benchmark for what “fast enough” actually means in production: a risk score generated in under 50 milliseconds, with fraud detection rates improving by an average of 20%, and as much as 300% in specific scenarios, according to Mastercard’s own figures. Mastercard hasn’t publicly branded that model an SLM, but the profile, purpose-built, narrow, fast, is exactly the shape the SLM argument describes. A general-purpose frontier model isn’t built to live inside that window, no matter how capable it is on a benchmark.
A model that looks perfectly affordable at pilot volume can quietly break the unit economics once it’s running millions of risk decisions a day across every transaction, every limit check, every covenant test, which is where ai risk quantification helps forecast potential AI-related events before volume makes them expensive. NVIDIA’s research puts purpose-built small models at roughly 10 to 30 times cheaper to serve than general-purpose large models for the kind of narrow, repetitive call most risk-scoring tasks actually are.
A separate academic benchmark on a comparably narrow classification task found a small model holding within 4.4% of GPT-4-level accuracy at roughly 3,899 times lower inference cost. That’s one data point on one task, not a guarantee the ratio holds everywhere, but it’s a useful illustration of how steep the cost curve gets once a task is narrow enough for a small model to handle well and how risk quantification tools can help forecast and price exposure at scale, not just cheaper inference.
Model risk management frameworks like the Federal Reserve’s SR 11-7 and an AI risk management framework such as the NIST AI Risk Management Framework, a risk management framework published in January 2023 and used to guide AI system design, require institutions to show that a model’s reasoning can be validated, documented, and defended, not just that the output looked accurate in backtesting. The EU AI Act goes further still, classifying AI used in creditworthiness assessment as a high-risk system that requires documented, factor-level reasoning a regulator or an affected borrower can actually follow. A large, general-purpose model’s path through a decision is harder to pin down precisely because it’s drawing on a much wider, less constrained space of associations.
A smaller model trained on a bounded set of risk factors produces a narrower, more traceable path from input to output, which happens to be exactly what a model validator is trying to reconstruct when they ask “why this score, why this borrower, why today.” That’s the practical meaning of explainable AI in a regulated risk function: not a marketing label, but a model whose reasoning a human can actually walk through after the fact.
SLM vs LLM for Financial Risk Modeling, at a Glance
Put together, those three mechanics, latency, cost, and explainability, collapse into a single practical question every fintech risk team eventually has to answer: not whether AI belongs in the model, but which size of model belongs in which part of the decision. That’s the SLM vs LLM question in its most concrete form, and it gets harder to dodge once a model moves from a pilot environment into a production risk stack handling real transaction volume, real regulatory scrutiny, and real consequences for a score landing wrong.
Must Read: 8 Types of LLMs Powering Modern AI Agents in 2026
The table below distills that trade-off into the dimensions that actually matter when an institution is choosing between a large, general-purpose model and a small, purpose-built one for a specific risk modeling task, not as an abstract comparison, but as a working checklist for the architecture decision itself.
| Dimension | Large Language Model | Small Language Model |
| Typical latency | Seconds per call | Milliseconds per call |
| Inference cost at volume | Compounds quickly past pilot scale | Stays manageable into the millions of calls per day |
| Explainability | Broad reasoning space, harder to trace | Narrow, bounded reasoning path, easier to audit |
| Update cycle | Costly and slow to retrain or fine-tune | Fast to fine-tune on new typologies or policy changes |
| Best-fit task | Open-ended reasoning, broad context, novel situations | Narrow, repetitive, bounded decisions at volume |
| Deployment footprint | Cloud-dependent, heavier infrastructure | Can run on-prem, on a branch server, or at the edge |
What “Small” Actually Means, and Why the Real Architecture Is Hybrid
In practice, “small language model” usually means something in the sub-10-billion-parameter range. These are domain-specific AI models in the most literal sense, built to do one job, inside one regulated context, and nothing else. TechAhead’s own work on inference deployment puts the practical ceiling for reliable on-device inference at roughly 3 to 7 billion parameters on current mobile and edge hardware, small enough to run on a single GPU, a branch server, or in some cases directly on a point-of-sale terminal.
Recommended: Aligning AI Capabilities with Business Outcomes
Most institutions get there one of two ways: distillation, where a smaller model is trained to approximate a larger “teacher” model’s behavior on one narrow task, or direct fine-tuning of an open-weight base model, Llama, Mistral, Phi, and Granite all show up repeatedly in financial-services deployments, on the institution’s own transaction history, policy documents, and past decisions.
This isn’t a hypothetical exercise. Cathay Financial Holdings presented research findings on fine-tuned, open-source small language models for customer intent classification at NVIDIA’s GTC Taipei in 2026, with preliminary results showing the approach could reduce dependence on complex prompt engineering and vector retrieval, simplifying system architecture and lowering future operational costs. It’s a customer-service application rather than a risk-modeling one, but it’s a real, named institution proving the underlying mechanics work in a regulated financial environment, not a vendor’s hypothetical.
Pairing a fine-tuned SLM with a retrieval layer over current regulatory text and internal policy, rather than baking that knowledge directly into the model’s weights, keeps reasoning grounded in what’s actually current. Credit policy and regulatory guidance change far faster than most institutions want to retrain a model.
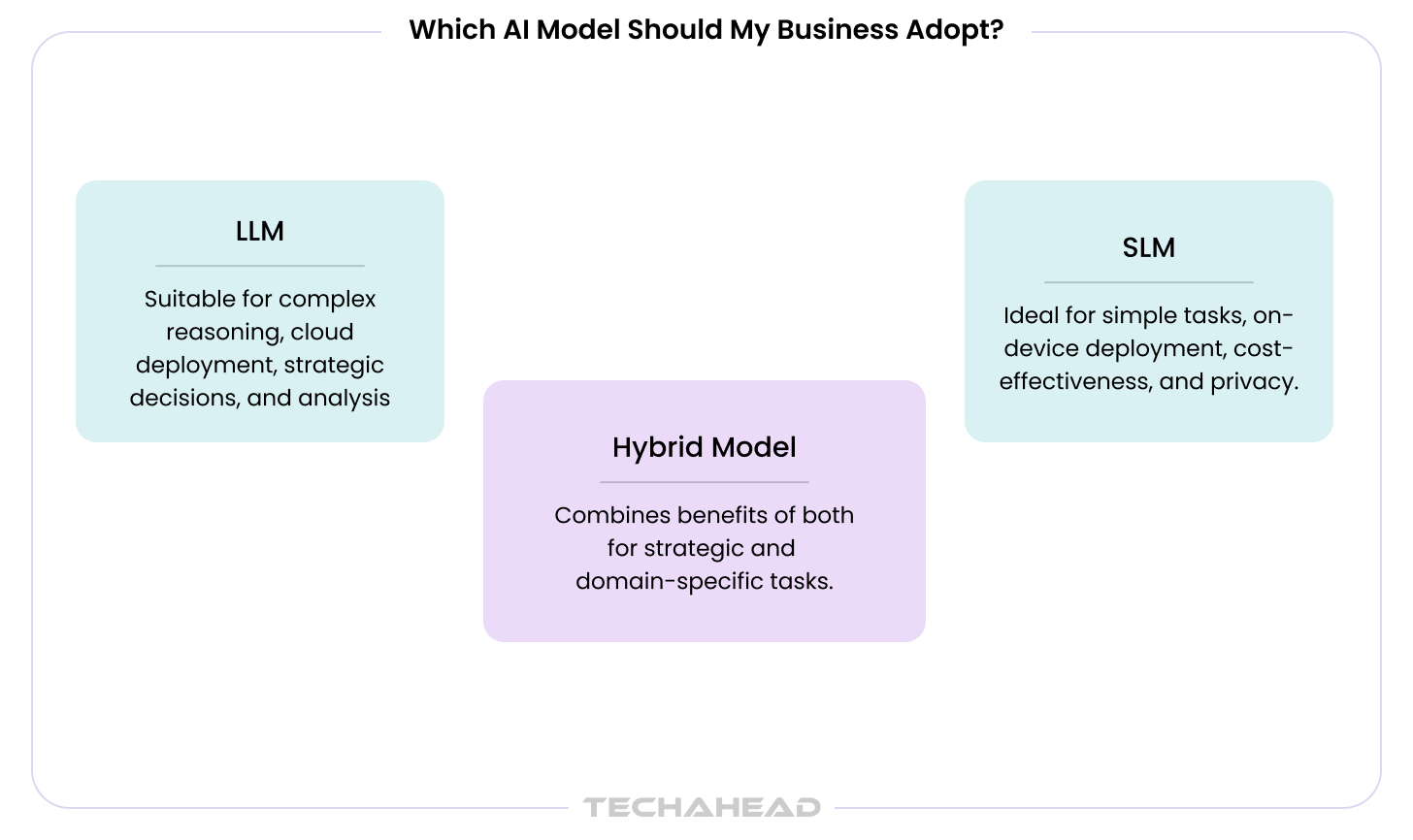
None of this means the large model disappears from the stack. NVIDIA’s own framing is a heterogeneous system: small models handling the repetitive, bounded decisions, with a larger model held in reserve for the genuinely open-ended cases, an unusual dispute narrative, a novel fraud pattern, a regulatory question nobody’s written a rule for yet. The real architecture decision isn’t SLM instead of LLM. It’s deciding, function by function, which one actually belongs there.

Some of what follows is already running in production today, named and documented. Some of it is a step ahead of what’s publicly confirmed but well within what current SLM architecture can already do. Each entry below says plainly which is which, so you’re not mistaking a strategic recommendation for a finished product. To conceptualize AI risk modeling at the architecture level, scenario building maps causal pathways from hazards to harms before institutions choose the right model for each function.
Most institutions still treat credit risk scoring and limit decisions as something that happens at underwriting and gets revisited on a quarterly or annual cycle. A small language model sitting inside the authorization path can re-score exposure at the moment a transaction is attempted instead, factoring in what’s changed since the limit was set rather than leaning on a number that’s already stale by the time it matters.
Confirmed in production: Mastercard’s Decision Intelligence Pro generates a transaction risk score in under 50 milliseconds by evaluating relationships across merchants, devices, and spending history in real time, improving fraud detection by an average of 20%, and up to 300% in specific cases, according to Mastercard’s own published figures. It’s the clearest public proof point available for what a production-grade real-time risk scoring layer actually has to deliver, even without Mastercard formally labeling the underlying model an SLM.
Architecture: A fine-tuned classification model outputting a bounded risk score and a structured reason code, fed by the live transaction payload (amount, merchant category, device fingerprint, recent velocity) plus a cached snapshot of current exposure, called synchronously inside the authorization service itself, not as a downstream batch process.
Not every transaction has a clean path to a cloud-hosted model. A branch in a market with unreliable connectivity, a POS terminal, or a kiosk operating under strict data-residency rules all need a risk decision made locally, on hardware that physically cannot run a large model and shouldn’t be sending sensitive transaction data off-site to get one. This is exactly the problem edge AI exists to solve. Local deployment also reduces operational risks that can disrupt organizational functions when connectivity or centralized AI tools fail.
Confirmed feasibility: Current mobile and edge hardware can reliably run quantized models in the 3 to 7 billion parameter range, which is precisely the size band most small language models built for risk scoring sit in. Industry coverage of edge AI in financial services increasingly treats this as core infrastructure rather than an experiment, moving fraud and risk decisions out of the data center and onto the device actually handling the transaction.
Architecture: A quantized model running on local hardware, exposed through a lightweight local API instead of a network call, taking transaction metadata and a recent local cache as input, with results synced upstream periodically for retraining, audit, dynamic monitoring, and real-time anomaly detection across the fleet rather than making the device dependent on connectivity to decide.
Commercial and SME loan books carry covenant tests buried in PDF agreements, financial statements, and loan officer notes, exactly the kind of narrow, repetitive, unstructured document-reading task a fine-tuned SLM handles well and a large general-purpose model handles at a much higher cost per document for no real accuracy gain.
Illustrative instance: Moody’s Lending Suite already applies pattern detection to covenant compliance and early-warning signals across loan portfolios today. No public deployment has confirmed the underlying model as an SLM specifically, but reading a DSCR covenant against a borrower’s trailing financials is exactly the bounded extraction task SLMs are built for, and doing it at small-model speed and cost is what turns a quarterly spreadsheet check into something closer to continuous monitoring.
Architecture: An extraction model fine-tuned on the institution’s own loan templates, taking parsed loan documents and trailing financials as input and producing structured covenant-test outputs (metric, threshold, current value, headroom) that feed directly into the existing loan monitoring dashboard, rather than a freeform summary someone still has to re-interpret.
Payment platforms and treasury desks need real-time risk scoring on counterparty exposure as positions move throughout the day, not a view that was accurate as of last night’s batch run and stale by 9 a.m. Live counterparty scoring supports predictive threat identification by spotting exposure anomalies before losses escalate.
Confirmed direction, illustrative on model size: JPMorgan’s own payments technology team has written publicly about shifting treasury decisioning from batch processing toward real-time, AI-assisted positioning, and the Basel Committee’s BCBS 248 framework for intraday liquidity monitoring already sets the supervisory bar for continuous oversight rather than end-of-day review. A small, fast model purpose-built for counterparty scoring is the natural way to meet that bar without adding the latency a larger model would introduce into every intraday position check, while strengthening risk analysis through faster hazard identification, scenario building, and probability estimation around exposure shifts.
Architecture: A scoring model embedded in the treasury orchestration layer, ingesting live position feeds and counterparty exposure data and recalculating on every material position change rather than a fixed interval, with outputs routed into the existing limit-monitoring dashboard.
Reading a call transcript or chat log to flag rising risk in a borrower’s tone, language, or stated intent is a narrow classification task, not a broad reasoning one, which makes it one of the cleaner SLM fits anywhere in the risk stack.
These models can also inherit bias from skewed or incomplete training data. Continuous bias monitoring should test for biased training data in datasets and outputs to prevent discrimination in decision-making processes.
Confirmed in research: A 2025 academic framework called EQ-Negotiator paired a 7-billion-parameter small language model with an emotional-state tracking layer for credit negotiation, and found it achieved better debt recovery and negotiation efficiency than baseline large language models more than ten times its size. That’s a published research result, not a named bank’s production system, but it’s a directly on-topic data point for exactly this use case, and it’s the kind of result that tends to show up in production roadmaps within a year or two of publication.
Architecture: An intent/sentiment classifier paired with a lightweight state-tracking layer, run at the end of each call or chat interaction, outputting a risk and urgency score with a recommended next action that feeds the existing collections queue, not a nightly batch job.
A buy-now-pay-later decision has to clear before a shopper’s patience runs out, which in practice means the underwriting model has a budget measured in milliseconds, not seconds, and almost no tolerance for a slow cloud round trip.
Illustrative, grounded in regulatory pressure: The OCC’s guidance on BNPL risk management explicitly flags the “highly automated nature” of BNPL lending and its instantaneous decisioning as a source of elevated operational risk, while the CFPB has separately intensified scrutiny of BNPL underwriting practices more broadly. Embedded underwriting also creates privacy risks when unauthorized access exposes sensitive applicant data. No public BNPL provider has confirmed using an SLM specifically for this, but the latency and auditability demands regulators are already pointing at read like a fairly direct description of where a small, fast, explainable model belongs over a large one, especially as firms strengthen risk assessment for the associated risks.
Architecture: A compact scoring model called synchronously at checkout, taking applicant and transaction signals as input and returning an approve, decline, or refer outcome with a reason code inside the checkout’s existing latency budget, with low-confidence cases routed to a fallback path instead of auto-declined; its audit and fallback logic should also surface vulnerabilities such as algorithmic bias or data privacy breaches.
Liquidity teams increasingly have the data to watch positions move in real time. What most of them still lack is the bandwidth to write up what changed and why, fast enough for the explanation to be useful before the position moves again.
Illustrative, grounded in regulatory framework: BCBS 248 and the ECB’s 2024 guidance on intraday liquidity risk both push institutions toward continuous, not end-of-day, liquidity oversight. A small model generating plain-language exception commentary as positions cross defined thresholds, explaining the movement rather than calculating the liquidity position itself, turns that supervisory expectation into something a treasury team can act on intraday instead of reconstructing the next morning.
Architecture: A generation-focused model sitting downstream of the existing liquidity monitoring system, triggered on a threshold breach, taking the breach and underlying position data as input and pushing a short structured explanation straight to the treasury team’s existing alert channel.
Model risk management teams are supposed to catch drift before it becomes an exam finding. In practice, most of that monitoring is still a periodic, manual review cycle running well behind whatever model it’s meant to be watching.
Illustrative, grounded in regulatory requirement: SR 11-7 already requires continuous performance and drift monitoring, not a periodic check, for models used in credit and risk decisions, a standard TechAhead’s own work on model documentation and provenance treats as a build requirement rather than an afterthought. A small, dedicated model trained to watch a production risk model’s output distribution and flag drift close to in real time is a more literal reading of “continuous monitoring” than most institutions currently run, and it’s narrow enough a task that a large general-purpose model would be costly overkill for the job.
Architecture: A monitoring model separate from the risk model it watches, ingesting that model’s input and output distribution on a rolling window, comparing it against a baseline, and flagging statistically meaningful drift directly into the existing model risk dashboard instead of waiting on the next scheduled validation cycle.
Regulatory capital reporting under the Basel framework doesn’t just need the right risk-weighted asset number. It needs a defensible, traceable explanation of how that number was derived, tied back to the specific methodology and inputs that produced it.
Illustrative, grounded in regulatory requirement: SR 11-7’s documentation standard and the Basel capital adequacy framework both demand exactly this kind of traceability. A small, domain-tuned model generating the explanatory documentation layer, narrating which inputs and methodology steps produced a given RWA figure, rather than performing the capital calculation itself, is a realistic, current-generation extension of the explainability case SLMs already make elsewhere in the risk stack, even though no public deployment has confirmed this specific application yet.
Architecture: A documentation-generation model taking the inputs, methodology version, and intermediate steps already produced by the existing capital calculation engine, and narrating them into an examiner-readable explanation tied back to source data, sitting downstream of the calculation rather than replacing it.
A global bank operating across multiple regulatory regimes faces a real architectural choice: one large model trying to hold every jurisdiction’s rules in context at once, or a set of smaller, regionally fine-tuned models that each only need to know the rules of the single market they’re actually scoring risk in.
Confirmed precedent in an adjacent function: Ryt Bank in Malaysia deployed a proprietary, regionally fine-tuned in-house language model as the primary interface for a fully regulator-approved digital bank, tuned specifically to Bank Negara Malaysia’s framework rather than a generic global model. It’s a conversational-banking deployment rather than a risk-scoring one, but it’s real proof that regulators are already approving regionally fine-tuned, institution-owned models inside live production banking, which is exactly the precedent a jurisdiction-specific risk-scoring model would be built on.
Architecture: A set of regionally fine-tuned model variants sharing a common base, each trained on that jurisdiction’s regulatory text and historical decisions, with a routing layer selecting the right variant based on the transaction’s jurisdiction before scoring happens, rather than one global model holding every region’s rules in context at once.
Must Read: AI Agents for KYC & Customer Onboarding
Inside an AI risk modeling build, the model selection question isn’t purely a technical one. Today, 72% of organizations now use some form of AI technology, which makes tighter governance in production builds harder to defer as AI technologies spread across existing workflows. It’s also where most of the model risk management burden in a build like this actually lives, and treating it as an engineering decision made in isolation from compliance is the most common way an SLM risk-modeling project ends up rebuilt six months after launch. That is especially true when teams fail to account for broader ai related risks and fold regulatory obligations into the core ai strategy from the start.
A few requirements don’t bend regardless of how small or fast the model is:
For most institutions, this is also where the build-versus-partner decision stops being abstract. Fine-tuning a small model on an institution’s own transaction history, policy documents, and historical decisions, while keeping documentation, versioning, and escalation logic compliant from the first design session rather than retrofitted later, is a narrower and more specialized skill set than most internal AI teams have built up yet, and it’s a different muscle than standing up a customer-facing chatbot.
Risk modeling with SLMs doesn’t function in isolation from the rest of a fintech AI agent stack. The same orchestration layer, audit logging, and compliance guardrails covered in TechAhead’s AML monitoring and multi-agent dispute resolution builds apply directly here, because a risk score rarely lives on its own. It feeds fraud detection, it feeds underwriting, and it feeds the case file the day a customer disputes the decision it produced.
What changes with risk modeling specifically is the size of the model doing the work, and getting that one decision right or wrong shows up in places that are easy to miss in a demo: the latency budget on a live transaction, the inference bill at full production volume, and what’s actually retrievable when a model risk examiner asks an institution to walk through a specific decision from six months back.
None of this is an argument for abandoning large models. It’s an argument for using them only where they actually earn their cost, and building everything else on something faster, cheaper, and considerably easier to explain.
If your AI risk modeling roadmap is still defaulting to “whichever model is most capable” as the architecture decision, that’s usually the first assumption worth re-examining, before the build starts rather than after the infrastructure bill arrives.

Here’s the part that doesn’t show up on the architecture slide: this isn’t a someday decision. The EU AI Act’s grace period runs out in August 2026, and after that, credit scoring and other high-risk AI systems face full enforcement, the kind that wants documented, factor-level reasoning behind every score, not a confident-sounding output from a model nobody can fully explain. If your risk model still can’t show its work, the clock is what’s actually forcing this conversation. Not curiosity.
Building this well is also a genuinely different job than most internal AI teams have done before. It’s not a chatbot with better manners. It’s a model that has to be fast, auditable, fine-tuned on your own risk data, and compliant from the first design meeting, not patched in after an examiner asks a question nobody planned for.
That happens to be exactly the kind of build TechAhead does:
None of that replaces an actual conversation about your specific risk stack. But if your next model is still stuck between “whichever one is biggest” and something built for this exact job, that’s worth working through now, while you’re still the one setting the terms. Talk to TechAhead about your risk modeling build.
The core difference is latency and explainability. Small language models are fine-tuned for one narrow task and run in milliseconds with a traceable reasoning path. Large models reason more broadly, but cost more and are harder to audit at scale.
Yes, and it’s a strong fit. Credit risk scoring is a narrow, bounded task, exactly what SLMs are built for. Institutions are already piloting fine-tuned small models for real-time scoring at authorization, not just underwriting, where speed and auditability matter.
It can be, if compliance gets built in early. SR 11-7 demands documented, validated reasoning, something small language models naturally support better than a black-box large model, provided versioning and audit trails are part of the design from day one.
Mostly speed and economics. Fraud scoring needs an answer in milliseconds, not seconds, and at millions of transactions a day, a real-time risk scoring model built small holds up better than a general-purpose model never designed for that volume.
Regulators want a traceable path from input to output, not a confident answer with no reasoning behind it. That’s the practical meaning of explainable AI in financial services, and it’s a big reason narrower, purpose-built models are gaining ground.
Beyond accuracy, you need model versioning, a documented audit trail, defined human-in-the-loop escalation points, and a way to reconstruct any decision months later. Model risk management isn’t optional, it’s the line between a pilot and something that survives an exam.
Yes, and it’s one of the better arguments for going small. Edge AI lets a compact, fine-tuned model run on a branch server, kiosk, or POS terminal, keeping risk decisions and data local rather than dependent on the cloud.
It needs catching before an examiner catches it first. Continuous drift monitoring, ideally by a dedicated model watching the production model’s output, is part of real model risk management, not a nice-to-have you bolt on after launch.
Credit scoring is classified high-risk under the EU AI Act, which means documented, factor-level reasoning becomes mandatory once full enforcement begins. Institutions still leaning on opaque models for AI risk modeling in fintech are running shorter on time than they think.
We build and fine-tune custom models against an institution’s own transaction history and policy documents, not generic benchmarks. That’s a different discipline than wiring up a chatbot, and it’s usually where internal AI teams want a build partner alongside them.
We use cookies to ensure our website functions properly, improve performance, and provide a personalized experience. You can choose which types of cookies to allow below.
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Help us understand site traffic and user interactions so we can improve performance and usability.
Enable enhanced functionality and personalization such as language or region preferences.
Used to deliver relevant ads, track campaign performance, and measure advertising effectiveness.