

















 Copy Link
Copy Link Share on X
Share on X Share on Facebook
Share on Facebook Share on LinkedIn
Share on LinkedIn


Always Active
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Build intelligent AI systems that automate decisions, accelerate innovation, and scale business growth.
Design, build, modernize, and scale digital products that drive business growth.
Build secure, scalable, and intelligent platforms that power modern enterprises.
Build intelligent, connected, and autonomous systems that operate in the real world.
Flexible engineering capacity with predictable delivery, ownership, and outcomes.
Uncover the transformative potential of digital and mobile solutions for your industry

 Last Updated: Jul 17, 2026
May 25, 2026
Last Updated: Jul 17, 2026
May 25, 2026  334
334  13 min. Read
13 min. Read



Key Takeaways
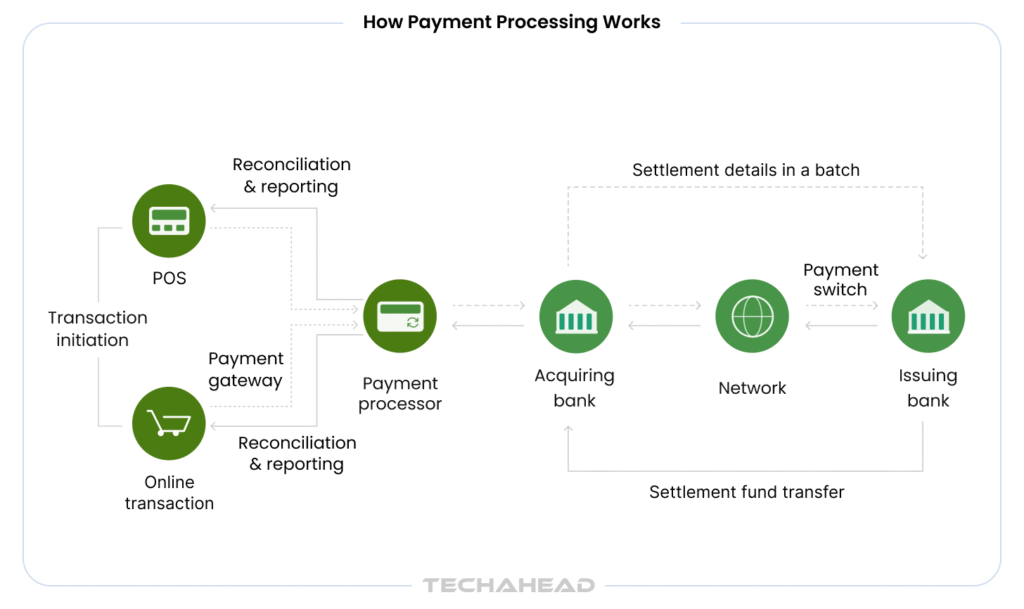
Every second, somewhere in the world, a payment fails. A timeout. A dropped connection. A duplicate request. For a small business, that is an inconvenience. For an enterprise processing thousands of transactions an hour, it is a revenue bleed and a trust problem that is very hard to undo.
Stripe processes over 500 million API requests per day and handles payments for companies like Amazon, Google, and Salesforce. And yet, double charges are nearly nonexistent. Transactions do not vanish mid-flight. The system keeps running even when individual servers go down. It happens due to advanced architecture. Here is exactly how they do it.
The numbers are harder to ignore than most fintech app development teams realize. For an enterprise processing 50,000 monthly transactions, even a 2% failure rate means 1,000 customers walking away every single month, quietly and without a complaint ticket. And failed payments are not just a revenue problem. They trigger a chain reaction:
Enterprise businesses have zero tolerance for this. When your payment infrastructure processes payroll, subscription renewals, or high-value B2B invoices; here reliability is not a feature; it is the baseline.
In our case, when we built WellPaid, a fintech platform managing recurring payments, bill splits, and automated transfers for thousands of users. A missed auto-payment or duplicate charge does not just create a support ticket; it breaks trust. We engineered WellPaid to handle automated money transfers, subscription tracking, and multi-party bill splits without a single transaction failure.

Here is a scenario that happens more than you think. A customer clicks “Pay.” The request hits Stripe’s servers, the charge processes, but the network drops before the confirmation reaches your app. So your app retries the request. Does the customer get charged twice?
With Stripe, no. The reason is idempotency keys.
Every payment request your system sends to Stripe includes a unique idempotency key; a string you generate that identifies that specific transaction attempt. If the same key is sent again (because of a retry), Stripe recognizes it and returns the original result instead of processing a second charge.
This is not a simple deduplication check. Stripe stores the full request fingerprint (endpoint, parameters, and result), so even edge cases like partial failures are handled correctly.
At 500 million+ daily API requests, even a 0.001% duplicate rate would mean 5,000 ghost charges per day. Idempotency collapses that number to near zero. For enterprise systems with aggressive retry logic (which is most of them); this is the difference between a reliable payment stack and a compliance nightmare.
Not every failure is a duplicate request. Sometimes a card is declined. Sometimes a bank’s API goes down for 30 seconds. Sometimes a webhook does not deliver.
Stripe has a layered approach to each of these.
Stripe uses exponential backoff for retries, meaning each retry waits progressively longer before trying again. It prevents a flood of simultaneous retries from overwhelming a bank’s API during an outage.
For subscription payments specifically, Stripe’s Smart Retries feature uses machine learning to predict the optimal time to retry a failed charge. According to Stripe’s data, their automated revenue recovery tools reclaim an average of 57% of failed recurring payments by dynamically timing retry attempts.
Network timeouts are treated as “unknown”; not as ‘failures’. This is a critical distinction. If Stripe does not get a response from a bank within the timeout window, it does not mark the transaction as failed. Instead, it holds the state as pending and resolves it once connectivity is restored.
This prevents the worst-case scenario: marking a payment as failed when it actually succeeded, and then refunding a customer who was correctly charged.
When a payment fails due to a card decline, Stripe parses the exact decline code from the issuing bank (indeed, there are over 30 distinct decline codes) and routes the response accordingly. Some declines are permanent (stolen card). Others are temporary (insufficient funds at this moment). Stripe’s retry logic treats them differently, which reduces unnecessary retries and improves card network standing.
However, a failed payment is not just a UX problem; it directly impacts cash flow on both sides of the transaction. When TechAhead built the FlexiLoans fintech application, handling payment disbursements and repayment collections reliably under real network conditions was a core engineering requirement. Timeouts, partial failures, and retry logic were not edge cases; they were expected scenarios the system had to handle without manual intervention.
A single data center going down is not a hypothetical. In 2021, a major cloud provider outage took down swaths of the internet for several hours. Stripe stayed up.
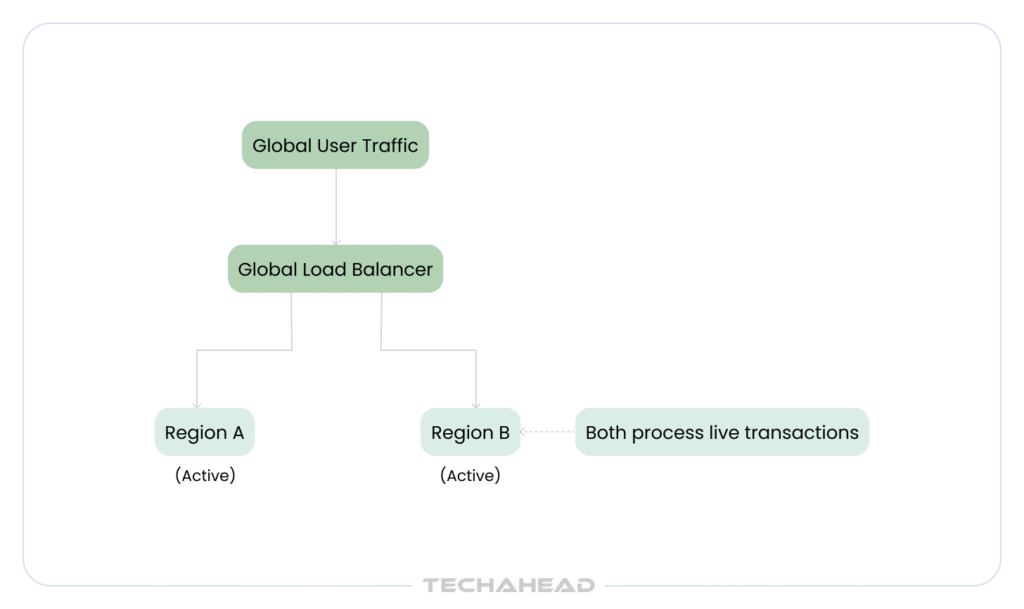
Stripe runs on a multi-region active-active architecture. It means:
Stripe uses a combination of synchronous and asynchronous replication:
It means that even in a worst-case regional failure, zero payment data is lost. The synchronous writes guarantee it.
For CTOs evaluating payment infrastructure: this is what separates enterprise systems from standard cloud setups. Active-active multi-region is not just high availability; it is the architecture that makes 99.99% uptime mathematically achievable.
TechAhead tackled this exact challenge while building a cross-border digital payments app that processes transactions across multiple countries using FXtags and QR-based payment flows. Handling cross-border transactions means dealing with currency conversion, regional compliance, and network latency simultaneously; all without slowing down or dropping a payment. The same multi-region thinking that powers global reliability went directly into this architecture.
Stripe does not just process payments; it tells your system what happened. That communication happens through webhooks: HTTP POST requests Stripe sends to your server when an event occurs (payment succeeded, subscription renewed, refund issued).
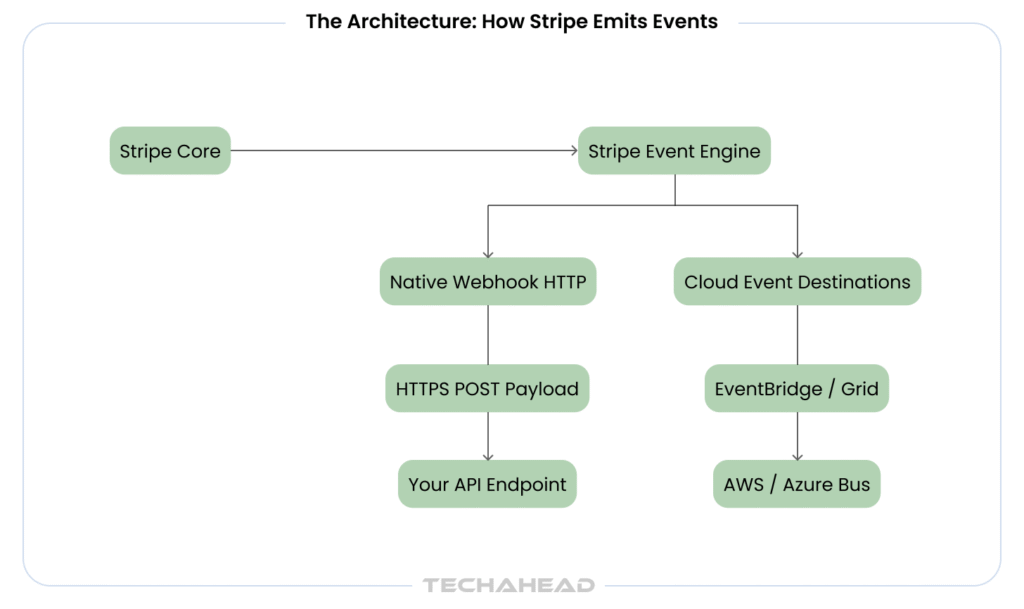
However, what if your server is down when Stripe sends the webhook?
Stripe retries failed webhook deliveries on an escalating schedule over 72 hours:
It gives your infrastructure time to recover without losing the event. Every webhook also includes an event ID; even if your server receives the same event twice (from a retry), you can check the ID and avoid processing it twice.
The alternative to webhooks is polling; your system repeatedly asks Stripe “did anything happen?” That approach breaks at scale. It creates unnecessary load, introduces latency, and does not work well across distributed microservices.
With event-driven architecture, Stripe pushes updates the moment they happen. Your systems react in real time. This is the pattern that lets enterprises build payment flows that span dozens of services without them all needing to talk to each other simultaneously.

What happens to a transaction record if the server crashes between “payment confirmed” and “database write completed”?
This is where most payment systems have hidden failure modes. Stripe addresses it through strict ACID compliance at the database layer.
Maintaining strict ACID guarantees inside a small relational database is standard practice. Sustaining it across a globally sharded distributed network processing millions of concurrent financial writes per second is an entirely different engineering challenge. To prevent data loss, ghost entries, or ledger corruption mid-transaction, Stripe layers specific distributed systems strategies:
Write-Ahead Logging (WAL)
Before any modification is structurally committed to a primary database ledger, the raw state change is appended to an immutable log on non-volatile storage. If a system experiences a sudden power drop mid-write, the database engine reconstructs the exact state deterministically upon recovery.
Optimistic Concurrency Control (OCC)
Instead of using heavy, blocking distributed locks that degrade database performance under heavy traffic spikes, modern financial platforms use OCC and localized shards. Transactions are processed concurrently, and the system verifies that the underlying data version has not changed right before committing the write, failing safely if a conflict is detected.
Distributed State Machines for Complex Actions
For transactions that stretch outside a single database write, such as an automated sequence involving a card authorization, a third-party fraud check, and final capture; platforms shift from database-level ACID to application-level state tracking.
If an unrecoverable banking timeout occurs late in the sequence, automated reverse-compensating workflows execute to cleanly roll back prior steps, preserving financial auditability.
TechAhead experienced this firsthand while building a sales CRM app for American Express, where every customer interaction, transaction record, and account update needed to be accurate, real-time, and fully auditable. At that scale, a single inconsistent record is not a bug; it is a compliance risk. The same ACID principles Stripe relies on were foundational to how we built that system. Read the full case study
Most companies test whether their system works. Stripe tests whether it survives when things break on purpose.
Heading: Active-Active Failure Testing
This practice is called chaos engineering; intentionally injecting failures into a live system to find weaknesses before real outages do.
Inspired by Netflix’s pioneering “Chaos Monkey” approach, Stripe’s chaos engineering practice means their failure recovery paths are tested continuously.
When you are evaluating a payment processor for enterprise use, the right question is not “what’s your uptime SLA?” It is “how do you know your fallback systems actually work?” Any vendor can promise 99.99% uptime. Stripe can demonstrate it, because they are constantly trying to break themselves.
99.99% uptime means 52 minutes of downtime per year. Not per month. Per year.
That is not a marketing number; it is an engineering constraint that shapes every architectural decision above.
During the 2020-2022 period when e-commerce traffic spiked unpredictably; sometimes 3x-5x normal volume during flash sales and global events; Stripe maintained its uptime commitments. That is not luck. It is what happens when reliability is designed in from the beginning, not bolted on after the fact.
Stripe’s architecture is not just impressive engineering. It is a blueprint for what advanced payment infrastructure looks like, and a benchmark for what you should expect from any payment system your business depends on.
If you are building a custom payment integration, scaling an existing one, or evaluating whether your current stack can handle your growth, the principles here matter. Idempotency, distributed ACID compliance, multi-region redundancy, event-driven delivery are the architectural foundation.
At TechAhead, we help enterprise teams engineer and integrate digital architectures that meet these exact structural standards. Whether you are executing a highly complex Stripe integration or building a custom transactional engine from scratch, we bring the rigorous engineering discipline, security frameworks, and technical oversight needed to keep your transactions flawless and your revenue completely intact. Are you ready to build infrastructure that never drops a transaction? Connect with TechAhead’s enterprise engineering team today to audit your current architecture and map out a customized blueprint for your enterprise.

Use a dual-pipeline architecture; an event-driven layer for real-time transactions and a scheduled job processor for batch payments, sharing the same ledger but operating on separate queues and execution environments.
A monolithic payment system runs all functions in one codebase; microservices split them into independent services. Microservices offer better fault isolation and scalability, but add distributed system complexity that monoliths avoid.
Design for horizontal auto-scaling, implement rate limiting, use queue-based load leveling, and pre-warm infrastructure before known peak events. Stateless services scale fastest; avoid session-dependent components in the critical payment path.
Eventual consistency means all nodes will sync. It is acceptable for non-critical data like dashboards or reports, never for transaction records, balances, or authorization states where accuracy is legally required.
Tokenization replaces card data with a random reference token; the original data never travels through your system. Encryption transforms data mathematically and can be reversed with a key; tokenization cannot be reversed without the vault.
3DS2 adds an authentication step between payment initiation and bank authorization. It passes device and behavioral data to the card issuer, who approves or challenges the transaction before the charge is submitted for processing.
We use cookies to ensure our website functions properly, improve performance, and provide a personalized experience. You can choose which types of cookies to allow below.
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Help us understand site traffic and user interactions so we can improve performance and usability.
Enable enhanced functionality and personalization such as language or region preferences.
Used to deliver relevant ads, track campaign performance, and measure advertising effectiveness.