

















 Copy Link
Copy Link Share on X
Share on X Share on Facebook
Share on Facebook Share on LinkedIn
Share on LinkedIn
Always Active
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Build intelligent AI systems that automate decisions, accelerate innovation, and scale business growth.
Design, build, modernize, and scale digital products that drive business growth.
Build secure, scalable, and intelligent platforms that power modern enterprises.
Build intelligent, connected, and autonomous systems that operate in the real world.
Flexible engineering capacity with predictable delivery, ownership, and outcomes.
Uncover the transformative potential of digital and mobile solutions for your industry

 Last Updated: Jul 15, 2026
Jun 26, 2026
Last Updated: Jul 15, 2026
Jun 26, 2026  162
162  21 min. Read
21 min. Read



Key Takeaways
Every enterprise AI roadmap has at least one pilot that has quietly stopped progressing. It hasn’t been cancelled, and it hasn’t been formally shelved. It simply sits in that stage where the demo still gets presented in steering committee meetings, but no one can say with confidence when it will actually go live. If that sounds familiar, the program isn’t broken. It’s actually the norm.
MIT’s NANDA initiative quantified this in 2025. After studying more than 300 enterprise AI deployments, researchers found that 95% failed to produce a measurable financial return, despite an estimated $30 to $40 billion already invested in generative AI by the companies studied. According to the report, the cause was rarely the model itself. It was almost always the gap between a working pilot and a system that customers, regulators, and internal stakeholders could actually trust.
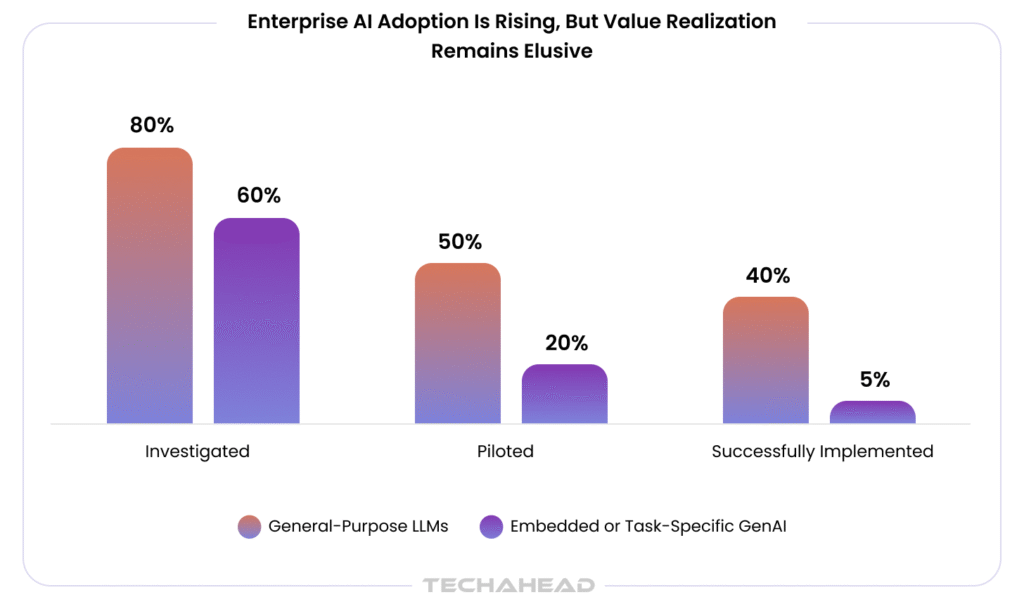
This is usually the point at which leadership concludes they need to hire AI engineers, often specifically forward deployed engineers (FDEs), given how frequently that title surfaces right now. It’s the right instinct, but the wrong starting point if the actual requirement isn’t clearly defined first. What follows lays out that hiring decision for whoever is responsible for making the call: the roles required, the delivery model that works, the governance questions leadership will raise, and what genuinely drives the cost.
Must Read: Enterprise AI Roadmap in 90 Days

“Forward Deployed Engineer” has become one of those phrases that shows up in every AI hiring conversation this year, and for good reason. Palantir built the role over a decade ago to embed engineers directly inside government and enterprise accounts. In 2026, OpenAI and Anthropic both followed, and within weeks of each other. OpenAI stood up a multibillion-dollar deployment business built almost entirely around this model, and Anthropic announced a parallel joint venture to embed engineers inside financial-services customers. That’s not a hiring trend. That’s two of the most valuable AI companies on earth deciding the deployment problem is worth a separate billion-dollar business line, and a strong signal about where they expect the next round of enterprise AI value to actually get captured.
What actually separates this role from a standard AI hire is fairly specific:
The competitive angle is worth naming directly. When two AI labs build separate billion-dollar businesses around getting their own models into production faster, that’s a signal about where the next round of competitive advantage actually sits. It won’t be which company licensed the better model. It’ll be which company had the engineering depth to get that model doing real work inside their organization months before the competition did.
Related: AI Development Guide 2026
This is where most hiring decisions go wrong before they’ve even started, and it usually isn’t a competence problem. It’s a category error.
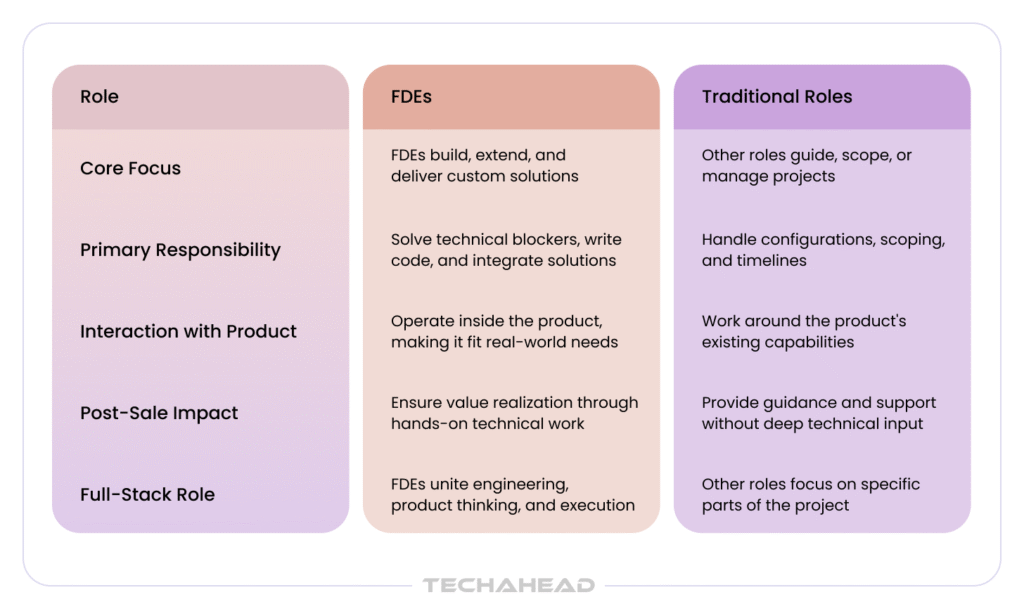
A traditional AI consultant tends to hand you a strategy, a roadmap, and a recommendation, then leave the building. A generalist developer can write good code but has often never sat through a production security review or owned the fallout when an integration breaks at midnight. A forward deployed engineer (FDE), or the equivalent AI deployment engineers you’d hire through an implementation partner, sits in the uncomfortable middle: a client-facing software engineer in an FDE role, technical enough to build, embedded enough to own the result, and senior enough to navigate your organization’s politics with strong communication skills, usually with 5-8 years of experience and modern AI and machine learning capability as part of the baseline profile.
That same MIT research turned up something easy to miss under the headline number: AI tools implemented with outside specialist help succeeded roughly twice as often as tools built entirely in-house.
If your team is being honest with you, the pilot probably isn’t stuck because the model got something wrong. It’s stuck because nobody owns getting it through the parts of your organization that were never built with an AI agent in mind: identity and access controls, decade-old core systems, audit requirements, the wider customer environment, the constraints of existing systems, and the internal team that has to maintain whatever gets shipped.
Engineers in this space have started calling this the integration wall, and the best way to move an AI pilot into production is almost never “wait for a better model.” It’s putting someone in the seat who’s spent their career on exactly this kind of wall, not in a research lab, and who can build solutions by adapting technical solutions to business needs inside the client environment to solve real business problems.
A few signs this is your actual problem, not a model problem:
This often includes custom integrations, such as bespoke scripts or APIs, to fit client workflows and systems.
None of this shows up clearly in a status update that says “on track.” It shows up when you ask the specific question: who, by name, owns getting this through security review, and what’s blocking them right now. If that question doesn’t have a fast, specific answer, you’ve found your actual bottleneck.
Model choice matters more here than most executives expect. OpenAI and Claude behave differently under load, handle tool use differently, and fail in different ways, and the differences go deeper than most procurement conversations get into, as covered in 8 Types of LLMs Powering Modern AI Agents. Betting your entire production rollout on whichever one your team experimented with first, rather than the one that actually fits the use case, is one of the quieter ways enterprises waste a quarter.
| So here’s the actual answer: Instead of leaving it scattered across the rest of this piece: enterprises don’t need a flashier model, a bigger AI budget, or even more AI talent in the abstract. What they need is a small, accountable team that can own a deployment end to end inside their real environment, treating the unglamorous integration and governance work as part of the build itself, not an afterthought bolted on right before launch. Everything from here, the roles, the delivery model, the governance checklist, and what actually drives the cost, is what building that team looks like in practice. |
Once leadership accepts that this is a staffing and delivery problem, not a model problem, there are really three paths, and each one has a cost that rarely makes it onto the first slide.
It’s a fair question, especially right after reading about the billion-dollar deployment businesses OpenAI and Anthropic just stood up. The honest answer is that those engineers aren’t really available to hire in the way the term implies, for a few specific reasons:
None of this is a knock on OpenAI or Anthropic, it’s a different resource solving a different problem: their embedded engineers exist to deepen that lab’s own enterprise relationships, not to give you a neutral, cross-ecosystem implementation team.
Partnering with a firm that already does this work is where most leadership teams land once they’ve actually priced out the other two. An AI implementation partner, or more specifically an enterprise AI implementation partner with real production history across both OpenAI and Claude, brings engineers who’ve already solved your integration wall problem somewhere else, with the bench depth to bring in specialists as the engagement’s needs shift, without you carrying full-time headcount risk for a function you may only need at this intensity for a year. That kind of professional services experience also tends to deepen customer understanding and communication through engaging directly with business stakeholders and customer teams, which is hard to replicate with junior hires.
This is also, plainly, the model TechAhead is built around. Our GenAI engineers don’t show up to learn your environment on your clock, they’ve already shipped production work across both ecosystems and walk in fluent.
A common pattern we see: start with an embedded team to get the first deployment live, then bring specific roles in-house once the patterns are proven, the partner becomes the fastest way to learn which roles are actually worth building permanently, instead of guessing upfront.

“Forward Deployed Engineer” gets used as a catch-all, but a real OpenAI or Claude implementation effort almost always needs more than one specialty, even if it’s covered by a small team rather than five separate hires. Here’s the breakdown we actually use when scoping a new engagement:
Owns the deployment end to end, from discovery through go-live. Comfortable in a security review in the morning and an API integration in the afternoon, and the single point of accountability if the timeline slips. In practice, this is often a FDE or similar senior profile with 5-8 years of software engineering experience, empowered to make decisions that balance technical outcomes and business priorities.
Builds the multi-step, tool-using workflows that go beyond a single prompt-response loop, the core of any serious agentic AI deployment. If “Model Context Protocol” came up in your last AI strategy meeting and nobody fully explained it, this plain-English breakdown is worth sending around before the next one. It’s exactly what our agentic AI developers are trained around.
Builds the test suites that catch hallucinations, regressions, and bias before a customer ever sees them. This role barely existed two years ago and is now close to non-negotiable.
Connects the model layer to your actual identity systems, data pipelines, and monitoring, the unglamorous plumbing that determines whether anything survives contact with production. This role requires deep integration skills and a focus on building custom solutions that fit your unique environment.
Keeps data handling and model behavior inside whatever lines your compliance team actually cares about, and is usually the person your legal team will want in the room from week one, not week twelve.
Most enterprises don’t need five separate full-time hires to cover this. They need a small, cross-functional team, which is usually closer to AI engineering team augmentation than a from-scratch hiring spree, and closer in practice to post-sales delivery than what a sales engineer typically owns.
A good embedded AI engineering team doesn’t take a spec and vanish for a quarter. The shape of a delivery that actually reaches production tends to look fairly consistent across engagements:

This also creates a continuous loop: FDEs collect customer pain points and failure data, act as a conduit for customer feedback and product innovation, and feed it back to product or core engineering teams for continuous learning and continuous improvement.
This is the practical core of an enterprise AI delivery model that survives contact with a real organization: production access from early on, evaluation built in rather than bolted on, and a team that’s still around after launch, not gone the moment the demo worked. The goal throughout is production-ready AI, not another polished pilot.
There’s no honest single number for how long this takes. It depends heavily on integration complexity and how much governance overhead the industry demands, and any partner who gives you a confident “12 weeks” before discovery has even started is guessing. What you can actually hold a partner to is the shape of the timeline, not a number pulled out of thin air:
If you’re in a regulated industry, governance isn’t a final checkbox, it has to be part of the build from day one. FDEs are most effective when they’re treated as deployment owners, not misidentified as support staff. AI governance is also, increasingly, what separates the deployments that survive a board review from the ones that quietly get shelved.
A few things worth locking down before your implementation partner starts building, not after:
These aren’t abstract questions. They’re close to verbatim what board risk committees have started asking, and “we’ll figure that out once it’s live” is no longer an acceptable answer in most audit conversations. Weak governance also creates ownership gaps, poor clear communication, and constant context-switching that can drive burnout risk for FDEs in high-pressure environments.
Also Read: AI Model Cards & Data Provenance
A partner’s own compliance posture matters here too. TechAhead operates under ISO 42001 for AI management, SOC 2 Type II, and ISO 27001, which tends to make this exact conversation with your legal and security teams considerably shorter, and reduces the production deployment risk that boards are increasingly asking about directly.
This is the section most vendor pages skip entirely. We won’t quote a figure that wouldn’t mean much outside your specific context, but here’s what actually moves the number when you’re evaluating enterprise AI implementation partner pricing models and many organizations now view this spend as part of digital transformation in the AI era because the goal is faster time-to-value and measurable business outcomes:
| Tier | Typical Engagement Type | Best Fit | What Drives the Range | Investment |
| Small | Fixed-scope project | One well-defined use case with a clear production endpoint | Integration complexity and the specific deliverable scoped upfront | $50,000 – $100,000 |
| Medium | Dedicated embedded team | A broader rollout, or multiple related use cases needing ongoing iteration | Team size, seniority mix, and engagement length | $100,000 – $200,000 |
| Large | Managed embedded program | Multi-quarter or ongoing AI initiatives spanning several use cases, often tied to governance or AI CoE build-out | Governance overhead, model usage at scale, and sustained team composition over time | $200,000 – $500,000 |

Once you’re shortlisting an OpenAI implementation partner or Claude implementation partner for the work, the logo on the homepage matters less than a handful of specific things:
If you want to see how this comes together as an ongoing practice rather than a one-off project, our AI Center of Excellence page covers how enterprises tend to structure that for the long run.
Most of the companies that get this right aren’t the ones that picked the flashiest model. They’re the ones that hired AI developers who’d already solved this exact problem somewhere else, and let that experience do the work a strategy deck never could. The best partners make sure technology aligns with business goals by solving ambiguous business problems under operational pressure, and more FDEs are being hired as software companies increasingly need post-deployment execution, not just software delivery. That’s the entire premise behind how we’ve built our own delivery teams at TechAhead. If you want to see what that looks like for your roadmap, Contact TechAhead and we’re ready to have that conversation.
They own the deployment itself, not just the code. A forward deployed engineer works inside your client environment to customize solutions for your workflows and existing systems, handles the security review, and stays accountable until the build is genuinely production-ready AI, not just a working demo.
A consultant hands you a strategy and moves on. A forward deployed engineer, or the AI deployment engineers you’d get through an implementation partner, actually builds and ships inside your environment, is typically involved in post sales implementation rather than only strategy or pre-sales work, and stays accountable when something breaks.
If your pilot’s been “almost ready” for a quarter, or security hasn’t signed off, that’s usually the signal it’s time to hire AI engineers who specialize in pilot to production work, not more research talent.
Real production history, not a portfolio of pilots. Look for an OpenAI implementation partner or Claude implementation partner with model-specific depth across both ecosystems, a mature evaluation practice, and engineers who work inside your environment, not from a distance.
At minimum, data residency review, a red-teaming process for failure modes, and a clear audit trail. AI governance isn’t a checkbox before launch, it has to be part of the build itself, not bolted on later.
It depends on which infrastructure you’re routing through and where, and that can shift between OpenAI’s and Claude’s setups. A real enterprise AI implementation partner maps this out during discovery, before any build work begins, not after.
Look for ISO 42001 for AI management, SOC 2 Type II, and ISO 27001 at minimum. TechAhead holds all three, which is usually what shortens the legal and security conversation before a deployment even starts.
Discovery and scoping first, then model selection, an embedded build inside your real environment, evaluation and hardening, and a defined production handoff, often with rapid prototyping during discovery. It’s the practical shape of an enterprise AI delivery model built to actually reach production.
They augment it, not replace it. A proper embedded AI engineering team works inside your existing setup, transfers knowledge as they go, and supports problem solving in AI-driven environments where off-the-shelf options fall short, while your internal team retains it once the engagement winds down.
There’s no honest single number, it depends on integration complexity. What you can expect: a scoped plan by the end of discovery, and faster movement than an internal team hitting production deployment risk for the first time mid-project.
We use cookies to ensure our website functions properly, improve performance, and provide a personalized experience. You can choose which types of cookies to allow below.
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Help us understand site traffic and user interactions so we can improve performance and usability.
Enable enhanced functionality and personalization such as language or region preferences.
Used to deliver relevant ads, track campaign performance, and measure advertising effectiveness.