







Staff Augmentation
Access top-tier talent on demand: Dedicated, Hourly, or Flexible.






























 Copy Link
Copy Link Share on X
Share on X Share on Facebook
Share on Facebook Share on LinkedIn
Share on LinkedIn
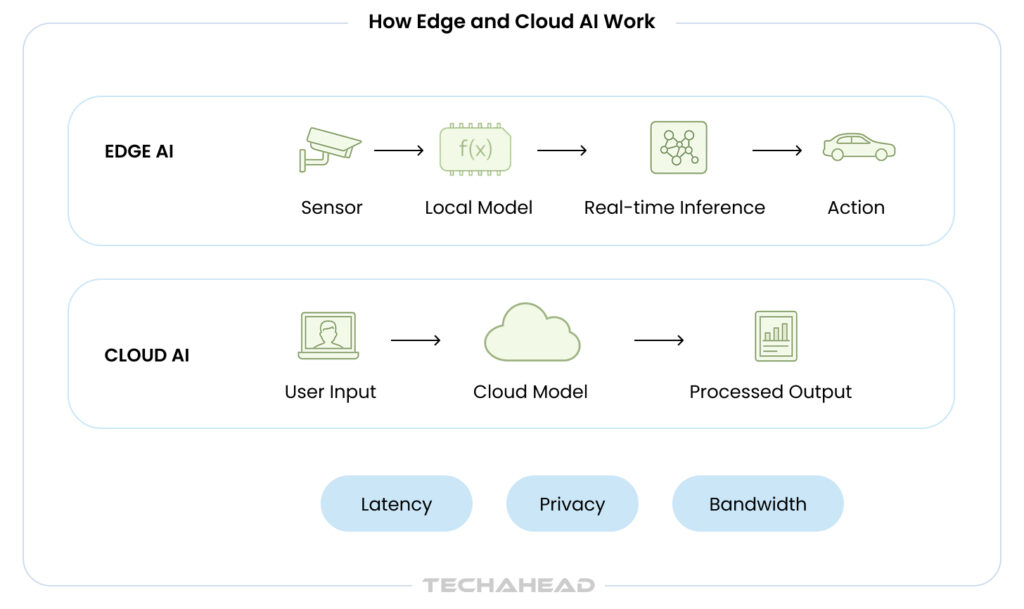
Cloud AI solutions struggle with latency-sensitive applications, while edge-only deployments lack the computational muscle for complex model training. Cloud architectures face bandwidth bottlenecks when processing terabytes of sensor data, and edge devices cannot handle the storage demands of maintaining multiple model versions. Neither approach alone delivers what modern enterprises need! That is why hybrid edge-cloud AI architecture plays an important role by ‘intelligently’ distributing workloads between edge and cloud. You get real-time inference where it matters most. It is not about choosing sides; it is about orchestrating the best of both worlds. And the numbers tell the story: the global hybrid cloud market generated USD 115,669.5 million in 2023 and is projected to reach USD 293,721.7 million by 2030. This market trend shows the hybrid architectures have moved from experimental to essential for enterprise competitiveness. So, in this blog, we are going to explore the core components, implementation strategies, and real-world use cases that are transforming industries.
Key Takeaways
- Hybrid edge-cloud AI merges low-latency edge inference with scalable cloud training for optimal performance.
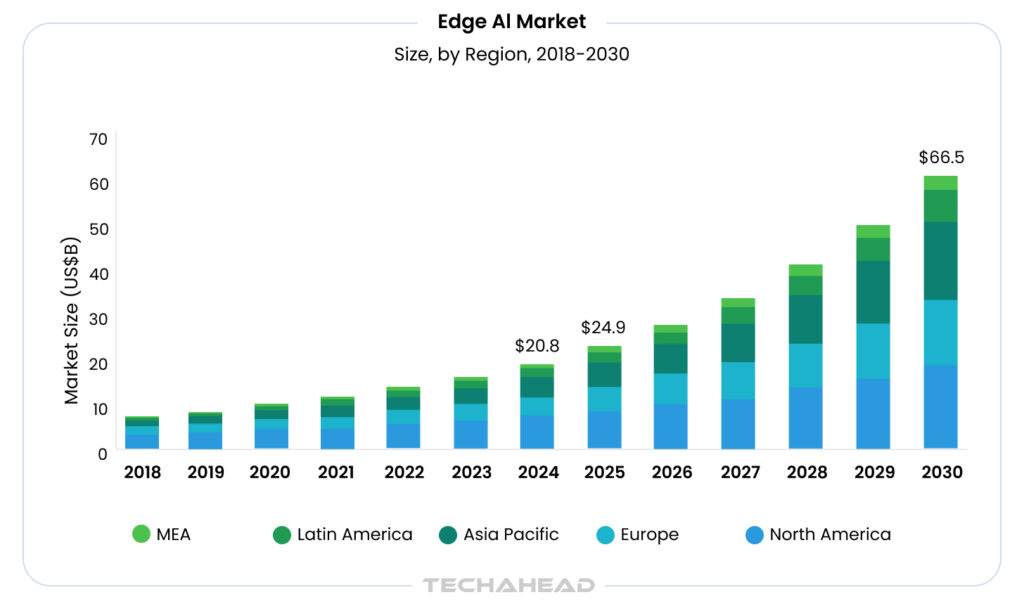
- Global edge AI market: $24.9B in 2025, projected $66.47B by 2030 at 21.7% CAGR.
- Pruning and distillation achieve 70-90% size reduction for edge deployment.
- Edge filtering cuts data egress fees and optimizes bandwidth usage significantly.
- Low-latency inference at edge ideal for IoT sensors, factory robots, autonomous systems.
What is Hybrid Edge-Cloud AI Architecture?
Hybrid Edge-Cloud AI Architecture combines edge computing’s low-latency processing on local devices with cloud’s scalable resources for model training. The global edge AI market size was estimated at USD 24.9 billion in 2025 and is projected to reach USD 66.47 billion by 2030, growing at a CAGR of 21.7% from 2025 to 2030. This hybrid model allows real-time AI inference at the edge, such as in IoT sensors or factory robots and utilizes cloud resources for data aggregation, federated learning, optimizing bandwidth for enterprises.
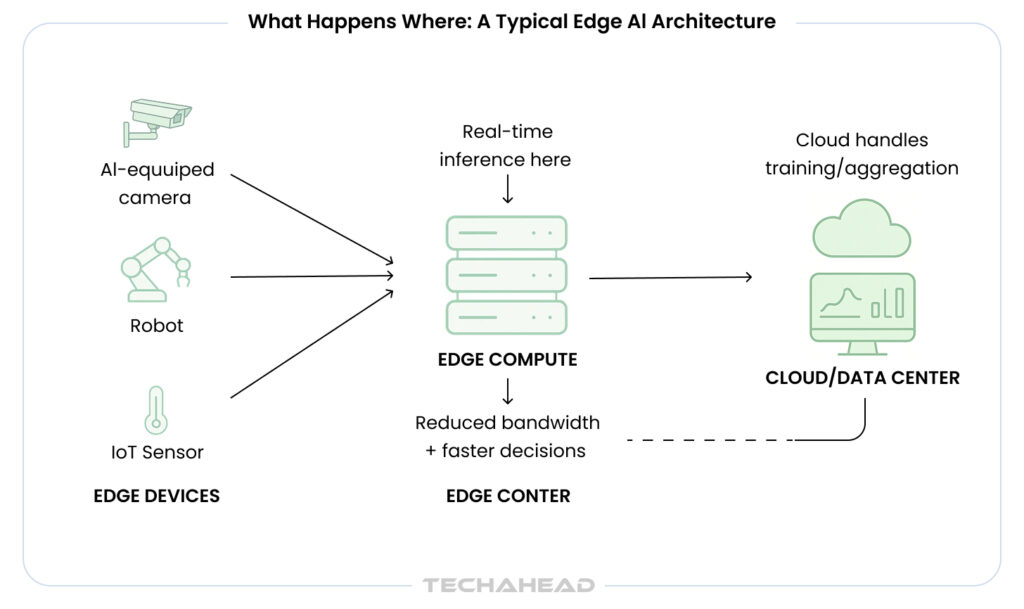
Here are the key features of this architecture:
- Low-Latency Inference: Edge nodes process data in milliseconds, ideal for autonomous systems.
- Scalable Cloud Training: Clouds handle complex model updates and bursty computations.
- Federated Learning: Privacy-preserving updates from edges to cloud without raw data transfer.
- Orchestration Tools: Kubernetes and KubeEdge manage hybrid deployments.
- Cost Optimization: Reduces data egress fees by filtering at the edge.
- Fault Tolerance: Operates during outages via distributed processing.
- Regulatory Compliance: Keeps sensitive data local following compliance.
Why are Enterprises Adopting Hybrid Edge-Cloud Models?
Enterprises adopt hybrid edge-cloud AI models to balance real-time processing needs with scalable computation. These models strategically position workloads where they perform best, creating infrastructure that adapts to diverse operational requirements. This architectural flexibility translates directly into measurable business outcomes across latency, cost, scalability dimensions.

Latency Reduction
Hybrid models process AI inferences at the edge that achieve sub-millisecond responses essential for applications like autonomous vehicles and industrial automation. Cloud round-trips often become unnecessary for time-sensitive tasks that prevent downtime costing millions annually.
Cost Optimization
With edge data filtration enterprises slash bandwidth and egress fees up to 70% in some cases. As a result, clouds handle only refined datasets for training. This pay-for-use scalability avoids overprovisioning edge hardware and reduces infrastructure spend.
Enhanced Security & Compliance
Sensitive data remains on-premises at the edge that minimizes breach risks during transmission. However, encrypted, privacy-preserving updates from edges to clouds for regulatory adherence without compromising insights.
Scalability and Resilience
Clouds provide elastic resources for model retraining and peak loads, while edge nodes maintain operations during outages. Distributed architecture supports global enterprises scaling AI across thousands of sites without single points of failure.
Operational Agility
Seamless orchestration via tools like Kubernetes and KubeEdge allows dynamic workload routing. Enterprises iterate faster, adapting models with edge feedback for hyper-personalized services in retail or healthcare.
These compelling advantages explain the rapid adoption, but realizing them needs understanding how hybrid systems actually work. Success depends on implementing the right architectural components for this edge-cloud synergy.
What are the Core Components of a Hybrid Edge-Cloud AI System?
A hybrid edge-cloud AI architecture requires careful orchestration of distributed components that work seamlessly across the computing continuum. Understanding these core elements is essential for enterprises looking to optimize inference latency, bandwidth consumption, operational costs.
Edge Inference Layer
The edge inference layer serves as the first line of intelligence, executing lightweight AI models on resource-constrained devices.
Hardware Accelerators and Edge Devices
This tier comprises edge gateways, IoT devices, and specialized AI accelerators like NVIDIA Jetson modules, Google Coral TPUs, or Intel Neural Compute Sticks. These devices balance power efficiency with computational throughput, often featuring dedicated neural processing units (NPUs) optimized for matrix operations. Selection criteria include thermal design power (TDP) constraints, memory bandwidth, and support for quantized inference formats.
Model Optimization Techniques
Edge deployment demands aggressive model compression to fit within memory constraints while preserving acceptable accuracy levels. Quantization reduces model precision from FP32 to INT8 or even INT4, which reduces model size by 4-8x. Pruning eliminates redundant neural connections, while knowledge distillation transfers learning from large teacher models to compact student models. These techniques often achieve 70-90% size reduction with minimal accuracy degradation.
Local Processing Capabilities
The primary objective is to process time-sensitive data locally that reduces round-trip latency to sub-100 millisecond thresholds for real-time applications. Edge nodes handle immediate inference decisions for anomaly detection, object recognition, or predictive maintenance triggers. They maintain sliding window buffers for temporal analysis and implement lightweight preprocessing pipelines before data transmission.
Edge Data Management
Local storage systems cache frequently accessed models, maintain inference history for debugging, and buffer telemetry data during network disruptions. Edge devices implement data filtering logic to transmit only anomalous events or aggregated statistics to the cloud which reduces bandwidth consumption by 80-95% compared to raw data streaming.

Cloud Processing Hub
The cloud layer provides the computational power for complex model training, fine-tuning, heavy inference workloads that exceed edge capabilities.
Scalable Compute Infrastructure
This component leverages GPU clusters (NVIDIA A100/H100), specialized AI chips like Google TPUs or AWS Inferentia, and distributed training frameworks such as Ray or Horovod. Auto-scaling groups adjust capacity based on training queue depth or inference request rates, with spot instances reducing costs for fault-tolerant batch workloads. Containerized workloads orchestrated through Kubernetes allow efficient resource multiplexing across multiple model serving endpoints.
Centralized Model Repository
The cloud serves as the authoritative source for full-precision models, storing multiple versions with associated metadata, training datasets, performance benchmarks. Model registries like MLflow or proprietary solutions track lineage for reproducibility and regulatory compliance. This repository supports variant management for A/B testing and phased rollouts across edge deployments.
Training and Fine-tuning Pipelines
Automated training orchestration handles scheduled retraining triggered by data drift detection, accuracy degradation alerts, or periodic refresh cycles. Distributed training splits large models across multiple GPUs using data parallelism or model parallelism strategies. Fine-tuning pipelines continuously adapt base models using federated learning aggregations.
Analytics and Monitoring Infrastructure
Centralized dashboards aggregate inference metrics, model performance indicators, and system health telemetry from distributed edge fleets. Time-series databases store historical trends for capacity planning and anomaly detection algorithms identify underperforming edge cohorts or model regression issues.
Model Management and Orchestration Framework
Effective hybrid architectures require advanced MLOps tooling to manage the model lifecycle across distributed environments.
Version Control and Registry
This subsystem maintains a catalog of model artifacts with semantic versioning, dependency tracking, rollback capabilities. Each version includes model weights, inference runtime configurations, preprocessing requirements, target hardware specifications. Git-based workflows integrate model changes with CI/CD pipelines for automated validation.
Deployment Orchestration
Automated deployment pipelines push model updates to edge cohorts using progressive rollout strategies. Canary deployments validate new versions on small device populations before full fleet updates. Blue-green deployment patterns allow zero-downtime transitions and feature flags allow selective activation of model capabilities across customer segments.
Performance Monitoring and Drift Detection
Continuous monitoring tracks inference latency distributions, accuracy metrics on validation datasets, and input data statistical properties. Drift detection algorithms compare current data distributions against training baseline using techniques like Kolmogorov-Smirnov tests or adversarial validation that triggers retraining workflows when divergence exceeds configured thresholds.
Federated Learning Coordination
For privacy-sensitive applications, the orchestration framework manages federated learning rounds where edge devices train on local data and transmit only gradient updates. The coordinator aggregates updates using secure aggregation protocols, updates the global model, and redistributes improved weights.
Intelligent Workload Partitioning Layer
The partitioning layer dynamically determines where computations should execute.
Decision Engine Architecture
This component implements policy-based routing algorithms that evaluate multiple factors: current bandwidth availability, edge device battery levels, inference urgency SLAs, cloud compute costs, data privacy requirements. Rule engines process decision trees or neural network classifiers trained on historical performance data to predict optimal execution locations.
Dynamic Model Splitting
Advanced implementations partition neural network computation across edge-cloud boundaries. Early layers execute locally for feature extraction and computationally expensive layers run in the cloud. Split points are determined dynamically based on network latency measurements and device resource availability, with frameworks like Neurosurgeon automating this optimization.
Adaptive Caching Strategies
Intelligent caching mechanisms pre-position frequently requested models or intermediate results on edge devices based on usage patterns. Predictive prefetching anticipates model requirements using time-series forecasting that reduces cold-start latencies for inference requests.
Cost Optimization Logic
The partitioning layer continuously evaluates the cost-performance tradeoff between edge inference (device power, hardware depreciation) and cloud processing (compute instance charges, data egress fees). Multi-objective optimization algorithms balance latency constraints against cost targets, potentially deferring non-urgent batch inferences to off-peak cloud pricing windows.
What Proven Patterns Support Scalable Hybrid Edge-Cloud AI Infrastructure?
Enterprise-grade hybrid edge-cloud AI deployments need architectural patterns that address scalability, reliability, operational complexity at scale.
Hub-and-Spoke Topology
The hub-and-spoke pattern centralizes orchestration through regional cloud hubs managing edge device clusters within geographical proximity. Each hub maintains synchronized model registries, handles aggregated telemetry, implements regional compliance policies for independent regional operations.
Hierarchical Edge Processing
Multi-tier architectures introduce intermediate fog nodes between leaf devices and cloud infrastructure. Factory sensors connect to edge gateways for initial filtering, then communicate with on-premises fog servers handling preprocessing and local model serving.
Mesh Network Architecture
Edge devices from peer-to-peer networks allow direct device-to-device model sharing and collaborative inference without cloud dependency. Devices discover neighbors, share computational resources, synchronize model updates and maintain decentralized consensus for distributed learning.
Event-Driven Streaming Pattern
Message brokers like Kafka or MQTT facilitate asynchronous communication between edge and cloud. Events trigger serverless functions for inference and provide reliable message delivery with exactly-once processing semantics.
Federated Learning Architecture
Edge devices train models locally on private data, transmitting only encrypted gradient updates to central aggregation servers. Cloud coordinates training rounds, performs secure aggregation, updates global models, redistributes improved weights without centralizing sensitive raw data.
Hybrid Batch-Stream Processing
Systems combine real-time streaming inference at the edge with batch processing in the cloud. Edge handles latency-sensitive decisions while cloud processes historical data for model retraining and long-term trend analysis using frameworks like Apache Spark.
Microservices-Based Deployment
Containerized AI services deployed across edge-cloud continuum enable independent scaling and updates. Each microservice handles specific functions—preprocessing, inference, post-processing—communicating via RESTful APIs or gRPC, orchestrated through Kubernetes for automated deployment and health management.
Active-Active Redundancy Pattern
Multiple cloud regions and edge clusters maintain synchronized states, all actively serving inference requests. Load balancers distribute traffic based on latency and availability. Any component failure triggers automatic failover so you can expect 99% uptime SLAs for applications.
Real-World Use Cases of Hybrid Edge-Cloud AI
Manufacturing
Siemens deploys hybrid edge-cloud AI across manufacturing facilities for real-time equipment monitoring and predictive maintenance. Here edge devices analyze vibration patterns, temperature fluctuations locally to detect anomalies. When edge models identify potential failures, detailed telemetry streams to cloud infrastructure for root cause analysis using complex deep learning models. This approach reduces equipment downtime by 30-40%.
Retail
Amazon Go stores edge cameras, sensors process computer vision models locally for real-time shopper tracking and product recognition. Edge inference identifies items customers pick up with sub-second latency essential for seamless checkout experiences. Cloud infrastructure handles inventory management and continuous model retraining using aggregated shopping patterns from multiple store locations. This architecture processes thousands of simultaneous shopping interactions and maintains customer privacy through local processing of sensitive video data.
Healthcare
Philips implements hybrid AI in healthcare imaging equipment where edge devices perform initial diagnostic screening using lightweight models (embedded in MRI and CT scanners). Critical findings trigger immediate clinician alerts for detailed analysis using compute-intensive algorithms. Cloud systems also aggregate anonymized imaging data across hospitals for federated learning, improving diagnostic accuracy without compromising patient privacy.
Automotive
Tesla vehicles run neural networks locally for real-time navigation, object detection, and collision avoidance decisions that demand single-digit millisecond response times. Each vehicle functions as an edge node processing sensor fusion from cameras, radar, and ultrasonic sensors. At scale, effective AI infrastructure management ensures seamless coordination between edge devices and cloud systems, where driving scenarios are aggregated across the fleet, models are retrained with edge cases, and over-the-air updates are securely deployed.
Getting Started: A Phased Implementation Approach
Successful hybrid edge-cloud AI implementation requires a systematic, risk-mitigated approach. We follow a phased process that balances speed-to-value with architectural rigor that means each stage builds upon validated foundations before expanding scope.
Phase 1: Assessment and Planning (Weeks 1-4)
- Conduct infrastructure audits that identify existing edge devices, network topology, cloud resources.
- Define use cases with clear ROI metrics, latency requirements, compliance constraints.
- Select pilot deployment area with measurable business impact.
Phase 2: Proof of Concept (Weeks 5-12)
- Deploy edge gateways and cloud infrastructure in controlled environments.
- Implement baseline models with monitoring dashboards tracking inference latency.
- Validate data pipelines, security protocols under simulated conditions.
Phase 3: Pilot Deployment (Weeks 13-20)
- Roll out architecture to selected business units or facilities.
- Establish MLOps workflows for model versioning, deployment automation.
- Gather performance metrics, user feedback, and optimize based on real-world observations.
Phase 4: Scale and Optimize (Weeks 21+)
- Expand deployment across additional locations using proven patterns.
- Implement advanced features like federated learning and dynamic workload partitioning.
- Establish a center of excellence for ongoing model governance and system enhancement.
Conclusion
Hybrid edge-cloud AI architecture represents a fundamental shift in how enterprises deploy intelligent systems. You can strategically distribute workloads between edge and cloud to achieve the responsiveness of local processing with the scalability of cloud infrastructure. Moreover, the market trajectory confirms what forward-thinking enterprises already know: hybrid architectures are no longer optional but essential for competitive advantage. So are you ready to architect your hybrid edge-cloud AI infrastructure? TechAhead’s expert team specializes in designing and implementing enterprise-scale AI solutions tailored to your specific requirements. Let’s transform your AI vision into reality.

What is the ROI timeline for hybrid edge-cloud AI implementations?
Most enterprises see initial ROI within 6-12 months through reduced bandwidth costs and improved latency. Full ROI materializes in 18-24 months as operational efficiencies and scaled deployments compound benefits.
How do we determine the optimal workload distribution between edge and cloud?
You can evaluate based on latency requirements, data sensitivity, bandwidth constraints. Time-critical inferences run at edge while model training, complex analytics, and aggregated processing use cloud resources for optimal performance.
Can we integrate hybrid AI architecture with our existing legacy systems?
Yes, through API gateways, message brokers, and middleware layers that translate protocols. Modern hybrid architectures support RESTful APIs, MQTT, and custom connectors for seamless integration with existing databases.
What are the disaster recovery and business continuity considerations?
You can implement multi-region cloud redundancy, edge autonomy during disconnection, automated failover mechanisms, and regular backup protocols. Edge devices should cache models locally and maintain operational capability independently.


