

















 Copy Link
Copy Link Share on X
Share on X Share on Facebook
Share on Facebook Share on LinkedIn
Share on LinkedIn
Always Active
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Build intelligent AI systems that automate decisions, accelerate innovation, and scale business growth.
Design, build, modernize, and scale digital products that drive business growth.
Build secure, scalable, and intelligent platforms that power modern enterprises.
Build intelligent, connected, and autonomous systems that operate in the real world.
Flexible engineering capacity with predictable delivery, ownership, and outcomes.
Uncover the transformative potential of digital and mobile solutions for your industry

 Last Updated: Jul 15, 2026
Apr 29, 2026
Last Updated: Jul 15, 2026
Apr 29, 2026  807
807  40 min. Read
40 min. Read



Key Takeaways
A few years back, LLMs and Gen AI were not quite known to the public, let alone being the catalyst for growth for enterprises, changing how everyday tasks are performed.
However, the next evolution of artificial intelligence came as AI agents or agentic AI, a system that is semi- or fully autonomous systems and thus able to perceive, reason, and act on its own. Different from currently known chatbots and copilots, Agentic AI solutions solve real problems independently or with minimal human supervision, be it shipping code, resolving customer issues, or planning smarter supply chains.
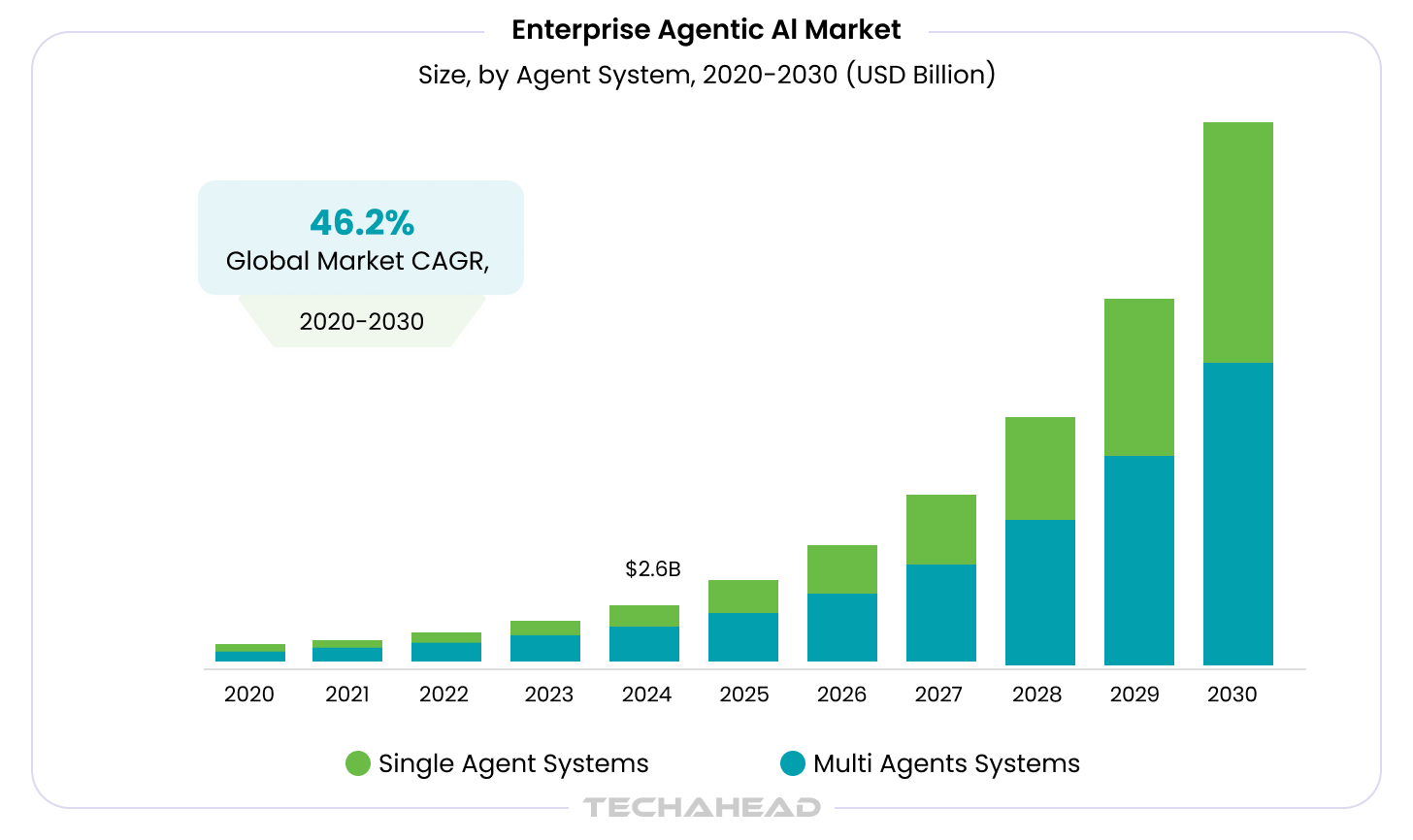
Consequently, it is expected that soon there will be billions of AI agents across consumer, enterprise, and industrial settings. The growth of enterprise agentic AI market size at a CAGR of 46.2%, which was estimated at $2.58 billion in 2024 and is expected to reach $24.50 billion by 2030, is a clear indicator of this massive growth. The market for Agentic AI development is driven by the increasing demand for automation and efficiency.
Here is the shift that is happening right now. The organizations that are pulling ahead on AI are no longer the ones with the most GPU capacity or the most parameters. They are the ones who figured out how to make AI act rather than just respond.
For the better part of a decade, enterprise AI meant inference. A model received an input and returned an output. A chatbot answered a question. A classifier sorted a ticket. A summarizer compressed a document. Useful, certainly. But fundamentally passive.
Agentic AI development changes the architecture entirely. Agents perceive their environment, reason about it, call tools, take actions, observe outcomes, and adjust. They do this in loops, across extended time horizons, often in coordination with other agents. According to Gartner, by 2028, at least 15% of day-to-day work decisions will be made autonomously by agentic AI systems, up from virtually zero in 2024.
The race in Agentic AI will not be won by the best model. It will be won by the teams that can run agents reliably in production. As performance converges and costs decline, execution, orchestration, and unit economics become the true competitive advantage.
TechAhead CEO, Vikas Kaushik
TechAhead is an AI-native software development company and Claude & OpenAI Services Partner. We help organizations design, build, and incorporate agentic AI systems. This guide is our operating view of the space: what agentic AI development actually involves, where the real technical complexity lives, and how enterprises can make defensible architectural decisions.
The term gets used loosely. Let us be precise.
An AI agent is a software system that uses a large language model as its reasoning core, can perceive inputs from its environment, can call external tools, and executes multi-step plans to achieve a goal with minimal human prompting at each step. The keyword is autonomous. The agent decides its next action based on observation of its current state, not because a human told it what to do next.
The evolution from chatbot to agent runs through three recognizable stages:
Four properties define a true agent:
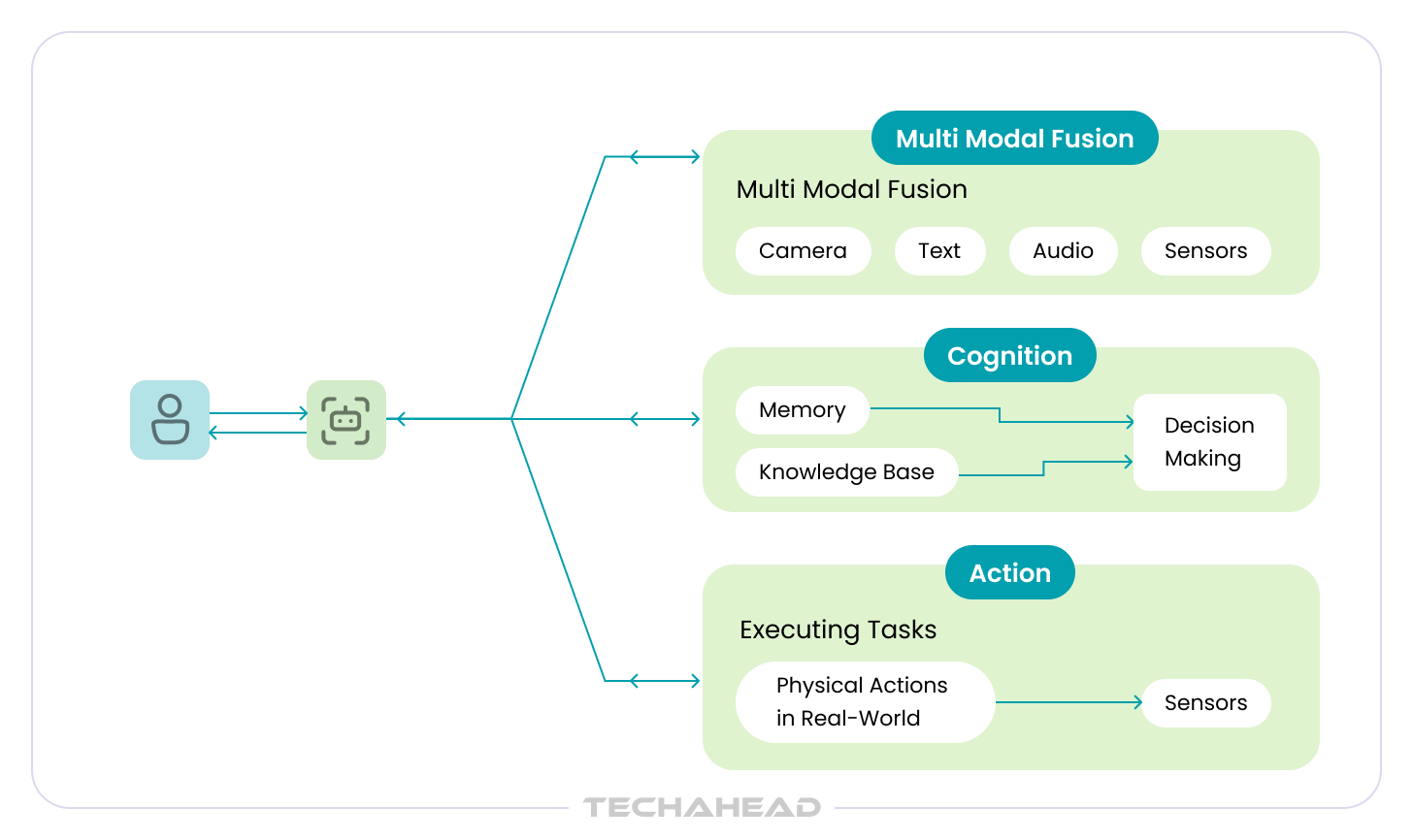
The agent loop that underlies most modern frameworks follows four phases: Perception (receive input and context), Reasoning (decide what to do), Action (call a tool or return output), Observation (receive the result and update state). This loop runs until the goal is achieved or a stopping condition is met.
Agentic AI development is fundamentally a systems engineering problem. The LLM is one component inside a broader architecture, not the product itself. Understanding that distinction is what separates teams that ship agents from teams that ship demos.
The language model provides reasoning, tool selection, and natural language understanding. In most production agentic systems today, that means GPT, Claude Sonnet, Gemini Pro, or comparable frontier models accessed via API. As both Claude & OpenAI Services Partner, TechAhead works extensively with Claude and OpenAI’s Assistants API, function calling, and the GPT model family for enterprise agent deployments.
Tools are the agent’s hands. Through structured function calls, an agent can query a database, read and write files, call a REST API, execute code, search the web, or invoke another agent. The quality of the tool interface, specifically the clarity of the function signatures and descriptions, has an outsized effect on agent reliability. Poor tool definitions produce agents that hallucinate actions or call tools with malformed inputs.
Agents operate across three memory layers, each serving a different purpose:
Memory architecture is one of the most underestimated design decisions in agentic AI development. See our full treatment: Agent Memory and State Management.
The three dominant planning strategies in use today are ReAct (Reasoning + Acting, where the model interleaves thought traces with tool calls), Chain-of-Thought decomposition (breaking a goal into explicit sub-tasks before executing), and Tree-of-Thought (exploring multiple reasoning branches and selecting the most promising path). Framework and model choice determine which strategies are available and how reliably they execute.
Every production agent needs a safety layer: input filters that catch adversarial prompts before they reach the model, output validators that check for policy violations or hallucinated data before actions execute, and human-in-the-loop gates at decision points where errors are irreversible. Security architecture for agents is covered in depth in: AI Agent Security: Prompt Injection and Guardrails.
Agentic AI, Generative AI, and Traditional AI terms get used interchangeably. However, they describe fundamentally different things.
Organizations that conflate them make the wrong architectural decisions, buy the wrong tools, and measure the wrong outcomes. The failure mode is predictable: they deploy generative AI where they need agentic AI, wonder why it requires constant human supervision, and conclude that “AI doesn’t work for our use case.” It does. They just deployed the wrong kind.
Traditional AI includes machine learning classifiers, regression models, recommendation engines, and computer vision systems trained to predict. It takes an input, applies a learned function, and returns an output. It does not reason, plan, or act. It does not ask follow-up questions or call an API. It maps inputs to outputs, efficiently and at scale.
Traditional AI excels when the problem is well-defined, the inputs are structured, the output is a prediction or a score, and the decision boundary does not change faster than the model can be retrained.
Agentic AI extends beyond the capabilities of traditional AI by incorporating decision-making frameworks that allow it to adapt its behavior based on real-time data and feedback, enabling it to operate effectively in dynamic environments.
Generative AI includes large language models, image generators, and multimodal systems trained to produce. Given a prompt, it generates text, images, code, or structured data that is contextually coherent with the input. It is exceptionally good at synthesis: summarizing documents, drafting communications, explaining complex topics, translating between formats, and generating plausible completions.
The critical characteristic of generative AI in its base form is that it is stateless and reactive. It works through prompt engineering. It produces a response. The loop ends. It does not retain memory between sessions unless an external system provides it. It does not decide what to do next on its own. It does not call tools. It responds.
Generative AI excels when the task is a single-turn or short-context content production problem: drafting, summarizing, translating, explaining, classifying natural language, or generating structured outputs from unstructured inputs.
Agentic AI uses a large language model as its reasoning core but wraps it in an architecture designed for action, not just response. The agent perceives its environment, reasons about the best next step, calls external tools, observes the outcome, updates its state, and continues. This loop runs until the task is complete or a stopping condition is reached.
The defining properties that separate an agent from a generative model are autonomy, tool use, planning, and memory. Remove any one of these and you have something useful, but you do not have an agent.
Agentic AI development enables an AI system to receive a goal, work through it across dozens of tool calls and decision points, and deliver a completed output that does not require human intervention at each step.
| Traditional AI | Generative AI | Agentic AI | |
| Core capability | Predict from structured data | Generate content from prompts | Execute multi-step tasks autonomously |
| Input type | Structured features | Natural language, images, code | Goals, instructions, environment state |
| Output type | Score, label, forecast | Text, image, code, structured data | Completed actions, decisions, artifacts |
| Memory | None (stateless inference) | In-context only | In-context + external + episodic |
| Tool use | No | No (base models) | Yes — APIs, databases, code execution |
| Planning | No | Limited (single-turn reasoning) | Yes — multi-step, adaptive |
| Autonomy | None | None | High, with configurable human gates |
| Best for | Classification, prediction, scoring | Content, synthesis, NL understanding | End-to-end workflow automation |
| Failure mode | Poor performance on out-of-distribution inputs | Hallucination, context limits | Misaligned tool calls, scope overreach |
Note: Agentic AI builds on generative AI techniques by using large language models (LLMs) to function in dynamic environments, while generative AI focuses on creating content based on learned patterns.
Single agents work well for bounded, sequential tasks. Enterprise problems are rarely bounded or sequential. They involve parallel workstreams, specialized domains, long-horizon planning, and real-time coordination across systems that were never designed to talk to each other. That is where multi-agent orchestration becomes the right architecture.
According to MarketsandMarkets, the AI agents market is projected to grow from $7.84 billion in 2025 to $52.62 billion by 2030 at a CAGR of 46.3%. The dominant driver is enterprise adoption of multi-agent systems for automating complex processes.
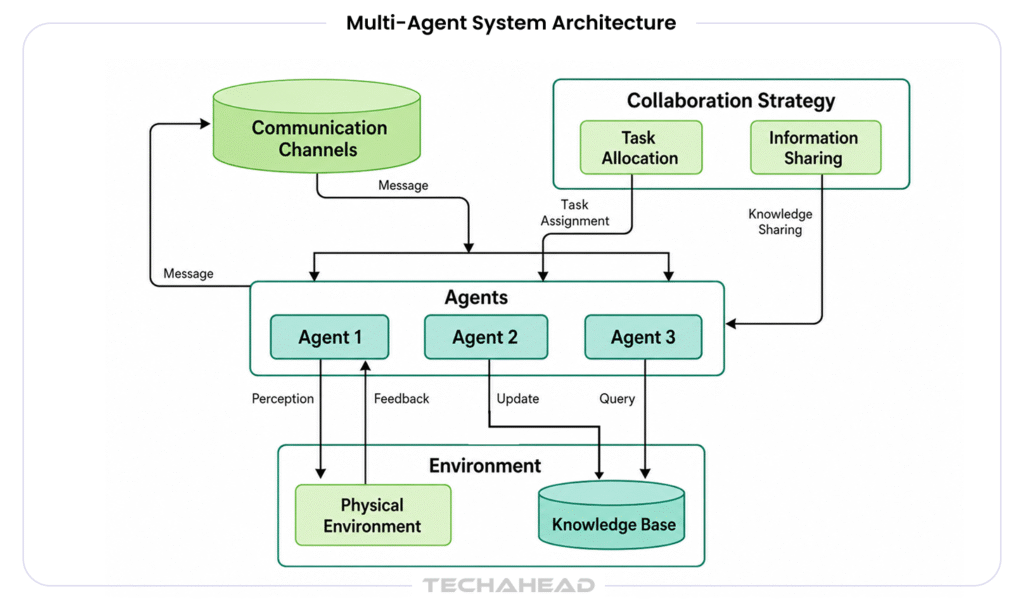
The most widely deployed multi-agent architecture uses an orchestrator agent that receives the high-level goal, decomposes it into sub-tasks, delegates those tasks to specialized worker agents, collects results, synthesizes them, and either completes the task or escalates. The orchestrator does not need domain expertise in each area. It needs planning capability and reliable inter-agent communication.

Google’s Agent2Agent (A2A) protocol, published in 2025, defines a standard for agents to discover each other, exchange capability descriptions, and coordinate tasks across different frameworks and vendors. This is a meaningful development for enterprise agentic AI development because it reduces the lock-in risk of building on any single framework.
See our full analysis: Agent2Agent (A2A) Architecture.
Consider an enterprise sales intelligence workflow. An orchestrator agent receives a sales brief. It delegates to a research agent (web search plus CRM queries), a competitive intelligence agent (news monitoring plus database queries), a financial analysis agent (SEC filings plus earnings data), and a communication agent (draft outreach). Each specialist runs in parallel. The orchestrator receives their outputs, synthesizes a prioritized brief, and presents a summary with linked sources to the sales team for review before any outreach action is taken.
That workflow might replace 4 to 6 hours of analyst time per sales cycle. At scale, it is a structural cost advantage.
For architectural patterns, failure modes, and enterprise deployment considerations: Multi-Agent Orchestration for Enterprise AI Workflows.
Framework selection is one of the most consequential early decisions in any agentic AI development project. The right framework depends on your cloud environment, your orchestration complexity, your team’s existing stack, and whether you are building for prototype velocity or production reliability.
| Framework | Orchestration | Memory | Best For | Cloud Affinity |
| LangGraph | Graph-based, stateful | In-context + external | Complex, cyclical workflows | Cloud-agnostic |
| Google ADK | Hierarchical agents | Session + external | Google Cloud enterprise | GCP |
| AutoGen | Conversational multi-agent | In-context | Research & prototyping | Azure / OpenAI |
| AWS Strands | Tool-first, serverless | DynamoDB / Redis | AWS-native serverless agents | AWS |
| CrewAI | Role-based crews | Shared crew memory | Task delegation workflows | Cloud-agnostic |
LangGraph is the most mature choice to handle complex workflows. Its graph-based execution model gives engineering teams fine-grained control over agent flow and makes debugging tractable.
Google ADK is the natural choice for GCP-native enterprises. Its hierarchical agent structure maps cleanly to organizational workflows, and its integration with Vertex AI and Google Workspace reduces integration overhead significantly.
AutoGen from Microsoft Research excels at conversational multi-agent patterns and is the leading choice for research and rapid prototyping, particularly in Azure environments.
AWS Strands is purpose-built for serverless agent workloads on AWS. Its tool-first model and native integration with DynamoDB, Lambda, and Bedrock make it the right choice for AWS-native infrastructure teams.
For a head-to-head production-readiness comparison of the two leading enterprise platforms: Google ADK vs AWS Strands: Which Agent Platform Wins. For a broader framework evaluation including LangGraph and AutoGen: Agent Frameworks Compared.
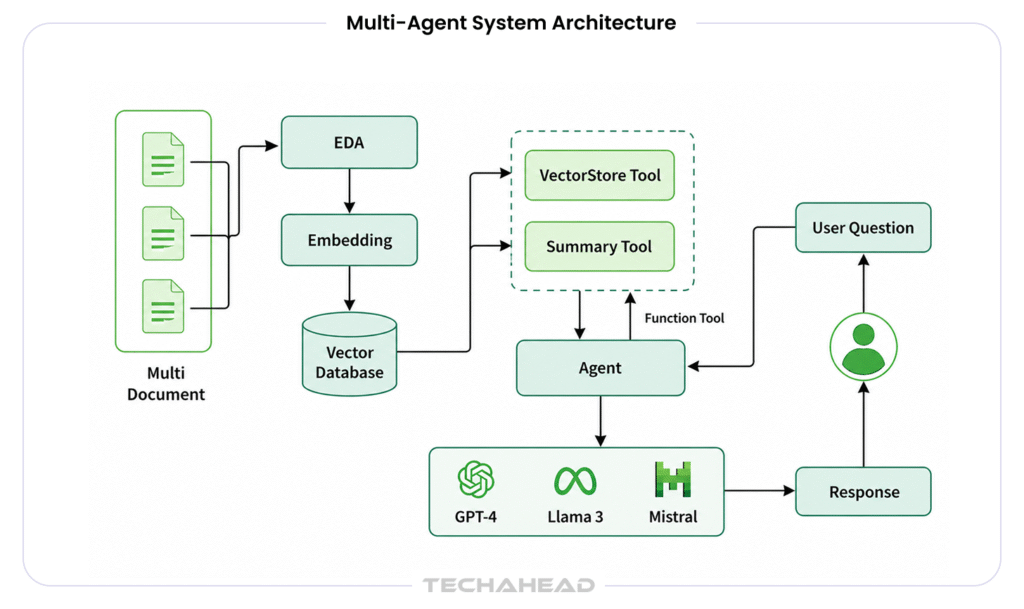
Standard retrieval-augmented generation retrieves a fixed set of document chunks at the start of a session and includes them in the context window. This works for simple question-and-answer over a document corpus. It breaks down for multi-step reasoning tasks where the information needed at step 4 cannot be predicted at step 1.
Agentic RAG treats retrieval as a tool the agent can call dynamically, on demand, at any point in its reasoning loop. The agent decides when to retrieve, what query to issue, which index to search, and how to integrate the retrieved content into its current reasoning state. This is a fundamentally different architecture, and it unlocks a qualitatively different level of performance on complex, knowledge-intensive tasks.
Full architecture patterns and implementation guidance: Agentic RAG: Retrieval-Augmented Generation for Agents.
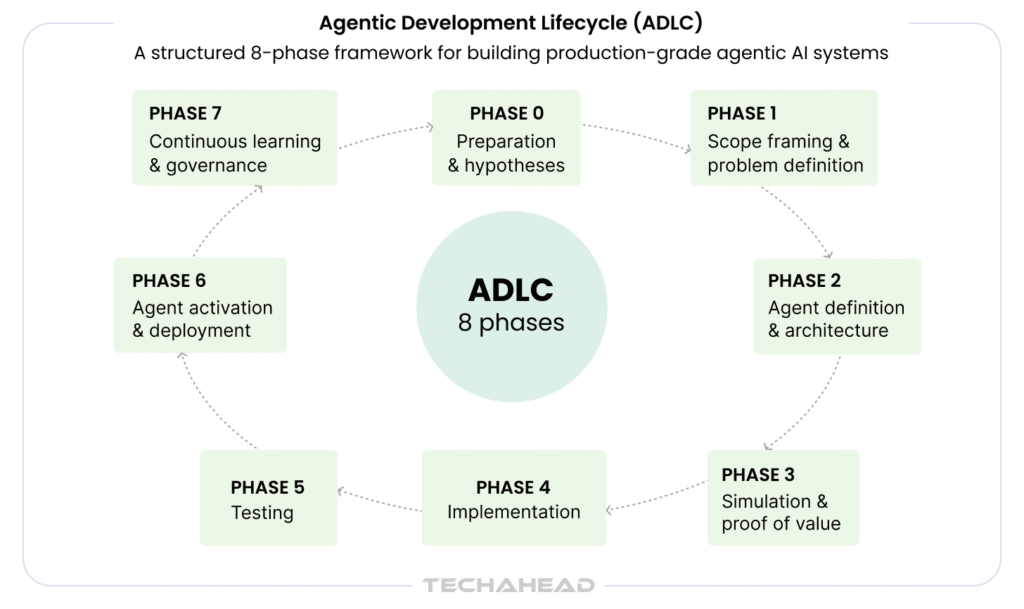
Agentic AI systems are not built like traditional software or even standard ML pipelines. They require a lifecycle that accounts for autonomy, multi-step reasoning, tool interaction, and continuous adaptation. The Agentic Development Lifecycle (ADLC) formalizes this process, ensuring that agents are functional, reliable, safe, and production-ready from the outset.
At its core, ADLC shifts the focus from model performance to system behavior over time. An agent that scores well on a benchmark but fails 30% of production tasks is not a successful deployment — it is a liability. The lifecycle framework exists to close that gap.
Most agentic AI projects fail before a single line of code is written. They fail because the problem is poorly defined, the constraints are unknown, or the decision to use AI was made before a workflow analysis was done. Phase 0 exists to prevent that.
The question at the end of Phase 0 is not ‘can we build this agent?’ It is ‘should we, and what will we measure to know if it worked?’
Once the hypothesis is validated, the workflow is mapped with precision. This is where abstract intent becomes a concrete engineering specification.
Poorly scoped agents either overreach into decisions that require human judgment, or underperform because their task boundary is too narrow to be useful. Scope framing is the discipline that prevents both failure modes.
With scope defined, the system architecture is designed around agents, not AI models. The LLM is one component inside a broader system. Architecture decisions made in this phase determine the reliability ceiling of everything that follows.
The LLM is the reasoning core. The real product is the architecture around it.
Before committing to a full build, the highest-risk elements of the architecture are validated against real data in a controlled environment. This phase exists because agent failures rarely appear in clean demos — they appear in edge cases, adversarial inputs, and unexpected tool call sequences that only emerge under production-like conditions.
A proof of value that only works on clean, curated inputs is not a proof of value. Phase 3 is where assumptions meet reality and where honest teams change their architecture before it is too late to do so cheaply.
With proof of value established, the full agent system is built to production standards. This is not a prototype iteration — it is an engineering build with the stability, observability, and security requirements of a production system.
Continuous evaluation during build surfaces regressions before they reach production. Teams that defer evaluation to the end of the build phase discover their agent performs differently on production data than on the data they built against.
Agentic systems require a testing methodology that standard software QA does not address. An agent’s behavior is not fully deterministic. Its failure modes are not exhaustively enumerable. Testing must be designed to surface the failure patterns that matter, not to prove correctness on the paths that were anticipated.
Formally validate system behavior, safety, compliance, and production readiness. An agent that passes unit tests but fails end-to-end tasks is not production-ready — it has passed the wrong tests.
Production deployment of an agentic system introduces a qualitatively different risk profile from standard software deployment. Agents act. Actions can be irreversible. Deployment must be designed around that reality.
Because agents act rather than just respond, security is a system-level architectural requirement. An agent that is capable but not safeguarded is not a product — it is a liability.
Agentic systems do not stay static after deployment. The world they operate in changes. Their task distribution shifts. New failure modes emerge. Phase 7 is not a post-launch formality — it is an operational discipline that determines whether the system remains reliable over time or degrades silently.

Unlike traditional AI, Agentic evaluation measures system behavior across extended, multi-step workflows where errors compound, and intermediate failures may not surface until several steps later. The metrics below apply across Phase 3 (Simulation), Phase 5 (Testing), and Phase 7 (Continuous Monitoring).
| Metric | What it measures | Why it matters for agents |
| Task Completion Rate (TCR) | Percentage of end-to-end tasks completed correctly without intervention | The headline production metric. A TCR below 85% signals architectural problems, not prompt problems. |
| Tool Call Accuracy | Correct function names, valid inputs, and appropriate timing across all tool invocations | The most common production failure mode. Malformed tool calls cascade into downstream errors that are expensive to debug. |
| Hallucination Rate | Frequency of assertions unsupported by context or retrieved data | In agentic contexts, a hallucinated fact can trigger a real-world action — the risk profile is orders of magnitude higher than in passive AI. |
| Step Efficiency | Ratio of actual steps taken to the minimum required | An agent completing a task in 40 steps when 12 suffice is both expensive and brittle under novel inputs. |
| Latency per Task | End-to-end wall-clock time from task initiation to completion | Enterprise workflows have SLA requirements. A powerful but slow agent is not deployable in time-sensitive contexts. |
| Cost per Task | Total API and compute spend for a single successful task completion | Production economics determine whether an agentic system is viable at scale. Cost per task must be measured before deployment, not after. |
A survey conducted by MIT Sloan Management Review and Boston Consulting Group found that 35% of respondents had already adopted AI agents by 2023, with another 44% expressing plans to deploy the technology in short order.
This is no longer an emerging technology. It is an operational decision with a widening competitive gap between organizations that have deployed and those still evaluating.
The shift happening across industries is a structural one. AI agents are not just improving workflows. They are redefining how businesses operate, transforming core technology platforms like CRM, ERP, and HR from relatively static systems to dynamic ecosystems that can analyze data and make decisions without human intervention. AI-powered workflows can accelerate business processes by 30% to 50% in areas ranging from finance and procurement to customer operations.
What follows is how that plays out, function by function.
Finance is consistently the first enterprise function where agentic AI development delivers measurable ROI. The reason is structural: finance workflows are rule-dense, the data is largely structured, and the cost of errors — in audit exposure, regulatory risk, and cash flow impact — is precisely measurable.
Expense management and compliance. Agentic AI systems can dramatically reduce transaction costs by automating complex workflows, which includes tasks like writing contracts, negotiating terms, and determining prices at a much lower marginal cost. Ramp, the corporate finance platform, launched its AI finance agent in 2025. The agent reads company policy documents and audits expenses autonomously, flagging violations automatically, generates reimbursement approvals and sends notifications without manual review, and coordinates with procurement systems to preemptively verify vendor compliance.
KYC, credit, and fraud detection. Use cases for agentic AI in financial organizations include adjusting credit scores, automating Know Your Customer (KYC) checks, calculating loans, and continuous monitoring of financial health indicators. The systems can fetch data beyond traditional sources, including CRM systems, payment gateways, banking data, credit bureaus, and sanction databases.
Autonomous ERP operations. Major enterprise software providers are now embedding native AI agents directly into cloud ERP platforms. These agents power touchless operations and real-time predictive insights, shifting the finance department’s role from reactive oversight to proactive foresight.
As of early 2025, agentic AI is already running at scale in call centers, where an agent might simultaneously analyze customer sentiment, review order history, access company policies, and respond to customer needs based on those elements.
Gartner projects that agentic AI will resolve 80% of user issues without human assistance by 2029, reducing support costs by 30%. The platforms driving this shift are now embedded in mainstream enterprise software stacks.
Salesforce Agentforce is the most widely deployed CRM-native agent platform in enterprise use today. Its Atlas Reasoning Engine powers autonomous decision-making inside existing CRM workflows, handling customer inquiries, resolving common service issues, qualifying leads, and managing case escalations with full context passed to human agents when needed.
Microsoft Copilot Studio takes a broader approach, embedding agents across the Microsoft 365 ecosystem. Copilot Studio’s computer use capability allows agents to treat websites and desktop applications as tools, interacting with any system that has a graphical user interface.
Supply chain management is one of the most natural fits for multi-agent agentic AI development because the workflows are inherently parallel, involve multiple external systems, and require continuous adaptation to real-world signals.
Supply chain workers can input the desired outcome. For example, finding and delivering the needed quantity of supplies at the lowest cost or with the quickest delivery, and expect the system to not only identify how to do so, but automatically initiate actions to make it a reality.
Clinical documentation agents listen to or read clinical notes, extract structured data, populate EHR fields, and flag missing required information before a patient encounter closes. The administrative burden this addresses is well-documented: physicians report spending roughly two hours on documentation for every hour of patient care. Agentic AI development targeted at this workflow has a direct, measurable impact on clinician burnout and care capacity.
Prior authorization agents automate the information retrieval and form completion steps of insurance authorization workflows, which currently consume significant nursing and administrative staff time and introduce care delays.
TechAhead engineered a healthcare ecosystem with Hoag, digitizing premium healthcare delivery through intelligent, patient-first technology and agentic AI automation. 15,000+ registered patients are actively accessing premium healthcare services through this platform.
The goal was to upturn the traditional healthcare delivery that was fragmented, appointment-heavy, and geographically restrictive. And this platform, built through modern cloud architecture, merged virtual consultations, intelligent automation, and personalized care to make world-class healthcare accessible to everyone. This leads to a 40% reduction in call center operational costs through intelligent virtual consultations, maintaining a 92% patient satisfaction score.
Security operations centers face a structural capacity problem. Alert volumes have outpaced human analyst bandwidth, creating the conditions for exactly the kind of missed signals that lead to breaches.
AI agents in a security operations center can proactively scan for new and emerging threats, investigate anomalies, and automatically take corrective action without human intervention.
The State of Oklahoma deployed an agentic AI system across its network infrastructure to address an overwhelming volume of daily security alerts across multiple state agencies. The system automatically triaged incoming alerts, correlated them across monitoring systems, and either auto-remediated known issue classes or escalated with a complete diagnostic package, reducing alert fatigue and mean time to response measurably.
Microsoft’s Product Change Management Agent Template automates workflows and connects critical systems, helping manufacturing teams cut approval times from weeks to days, reduce errors, and bring innovations to market faster. Coca-Cola Beverages Africa is among the organizations using this agent template to optimize manufacturing operations.
Beyond change management, agentic AI is being deployed for quality control monitoring, predictive maintenance scheduling, and supplier coordination — workflows where the combination of real-time sensor data, historical patterns, and cross-system action capability creates compounding value that point solutions cannot match.
This is TechAhead’s primary domain. Agentic AI development tools are changing how software gets built. Coding agents can take a feature specification, generate implementation code, write tests, run them, debug failures, iterate, and produce a pull request for human review. Tools like OpenAI Codex, GitHub Copilot Workspace, and purpose-built agent platforms are moving from developer assistance to developer augmentation.
According to McKinsey Global Institute, generative AI and agent tools could add $2.6 to $4.4 trillion annually across business functions, with software engineering among the highest-impact sectors for productivity gains.
A full breakdown of deployment patterns by industry vertical: Agentic AI Use Cases by Industry.
Most enterprise AI teams discover evaluation is their hardest problem the hard way: after they have built something. Standard LLM evaluation metrics do not transfer to agents. Perplexity and BLEU scores tell you nothing about whether an agent successfully completed a multi-step task. Accuracy on a QA benchmark tells you nothing about tool call reliability over a 20-step workflow.
Agents operate over extended sequences of decisions. An error at step 3 of a 15-step task may not surface until step 12. The agent may produce a syntactically correct output that is semantically wrong for the business context. A metric that evaluates only the final output misses the quality of the reasoning path that produced it.
AgentBench and GAIA are the leading academic evaluation suites for agent AI capabilities. For production enterprise agents, TechAhead builds custom evaluation harnesses that reflect the specific task distributions and failure modes of the target deployment. This is not optional. An evaluation suite built on the wrong task distribution will give you high benchmark scores and poor production performance.
Full evaluation methodology, framework comparisons, and a starter checklist: Evaluating Agent Performance: Metrics and Frameworks.
The path to success in leveraging agentic AI involves moving from experimentation to deliberate scaling and utilizing platforms that provide pre-built integration and security.
Agents introduce a threat surface that does not exist in passive AI systems. A chatbot that gives a bad answer is a quality problem. An agent that executes a malicious instruction is a security incident. The difference matters enormously for how you architect security controls.
Because agents act, they can cause harm that is difficult to reverse. A data exfiltration via API call, a database record deletion, an unauthorized financial transaction, or a prompt injection that hijacks an agent’s tool calls to exfiltrate credentials are all within the threat model of a poorly secured agent.
Prompt injection is one of the top risks for LLM-based systems, becoming significantly more dangerous in agentic contexts where the model’s outputs trigger real-world actions.
Direct prompt injection occurs when a user inputs a malicious instruction that overrides the system prompt, causing the agent to act outside its authorized scope.
Indirect prompt injection is more insidious. It occurs when a malicious instruction is embedded in external content the agent retrieves and processes: a webpage the agent browses, a document it reads, a database record it queries. The agent processes the content and, if not properly sandboxed, executes the embedded instruction. This is a live attack vector in any agent with web browsing or document reading capabilities.
A production-grade guardrail architecture for agentic AI development includes four layers:
Full threat modeling, attack vector analysis, and enterprise guardrail patterns: AI Agent Security: Prompt Injection and Guardrails.
TechAhead has been building production AI systems since before the current agentic AI development wave. Our methodology reflects that experience. We have seen what breaks in production that never broke in demos, and we have designed our build process around preventing those failures.
As an experienced Agentic AI development company and Claude & OpenAI services partner, TechAhead has offer various AI engineering and solutions across industries. For enterprise clients, this means access to early model releases, model-specific optimization guidance, and escalation paths that are not available through standard API access.
One such example of the project we delivered is agentic AI-driven employee referral engine that proactively assists employees and HR teams with personalized, automated hiring workflows. With the integration of various AI/ML ecosystems like Hugging Face, spaCy, FAISS, SHAP, and Kubeflow, we developed many features like referral scoring models, predictive matchmaking, and bot-based alerts.
Creating a fully automations AI-driven platform with automated bonus management, smart referral recommendations, and effortless referral process, we have created measurable impact in 2024, including:
For transforming enterprise hiring through innovation and automation, our client, ERIN, was recognized by Lighthouse Research & Advisory and honored at UNLEASH America 2025.
For orchestration, we work primarily with LangGraph for complex stateful workflows and Google ADK for GCP-native enterprise deployments. For the reasoning layer, GPT and the OpenAI Assistants API are our primary stack, with Gemini and Claude for clients with specific model preferences. For memory and retrieval, we use pgvector for cost-sensitive deployments, Pinecone for high-scale production, and custom RAG pipelines for domain-specific knowledge bases.
TechAhead + Claude & OpenAI: As a Claude & OpenAI Services Partner, we deploy GPT, the Assistants API, and function calling in production enterprise environments. We have structured access to model-specific guidance, early release programs, and OpenAI engineering support for complex deployments.
Well-designed agentic AI systems, applied to clearly scoped workflows, typically deliver measurable gains. In production deployments, we commonly see 60–80% reduction in manual effort for targeted tasks, 40–60% reduction in error rates compared to human-only processes, and ROI timelines of 12–18 months for mid-size implementations. Actual outcomes depend on workflow complexity, data quality, and level of system integration.

Traditional automation follows fixed rules and decision trees. An AI agent perceives its environment, reasons about the best next action, uses tools, and adapts when circumstances change. It can handle edge cases that would break a scripted workflow.
Yes, with the right architecture. Regulated deployments require human-in-the-loop gates at high-stakes decision points, audit-grade logging, role-based access controls, and prompt injection defenses. TechAhead builds compliance requirements into the system architecture from day one.
A focused proof-of-concept with one or two agents typically takes 6 to 10 weeks. A production-grade multi-agent system with evaluation harnesses, security hardening, and integration into enterprise systems usually takes 3 to 6 months.
It means TechAhead has verified technical expertise in deploying OpenAI and Claude models and APIs at scale. Clients benefit from direct access to OpenAI and Claude engineering resources, early access to model updates, and a partner that has demonstrated production-grade delivery.
Yes. Agents communicate with external systems via tool calls and APIs. Whether your stack runs on Salesforce, SAP, AWS, Azure, or custom internal systems, tool wrappers can expose those systems to the agent layer with appropriate access controls.
Agentic AI development cost depends on various factors like architecture, integration depth, compliance tier, and so on. On average, an agentic MVP cost may start from $50,000, whereas multi-agent orchestration costs around $150,000+ because of complex inter-agent reasoning requirements. Besides, autonomous enterprise platforms generally exceed $400,000.
For agentic AI development, organizations have to shift their strategy from system design and workflow orchestration. A typical approach includes defining the workflow, designing the agent architecture, integrating reasoning models, enabling tool usage, implementing evaluation, deploying guardrails, and monitoring & optimizing performance.
The 4 stages in which Agentic AI systems rely to operate in a continuous loop includes perception (receiving inputs from its environment), reasoning (analyzing context, plans the next steps; deciding which actions to take), action (executing tasks using tools such as APIs, databases, or code execution), and observation (evaluating outcomes, updates its state or memory, and adjusts future actions).
The choice for the best Agentic AI tools depends on your architecture, cloud ecosystem, and use case. Commonly used frameworks include LangGraph, AutoGen, CrewAI, Google ADK (Agent Development Kit), AWS Strands, and OpenAI Assistants API / function calling.
We use cookies to ensure our website functions properly, improve performance, and provide a personalized experience. You can choose which types of cookies to allow below.
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Help us understand site traffic and user interactions so we can improve performance and usability.
Enable enhanced functionality and personalization such as language or region preferences.
Used to deliver relevant ads, track campaign performance, and measure advertising effectiveness.