

















 Copy Link
Copy Link Share on X
Share on X Share on Facebook
Share on Facebook Share on LinkedIn
Share on LinkedIn


Always Active
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Build intelligent AI systems that automate decisions, accelerate innovation, and scale business growth.
Design, build, modernize, and scale digital products that drive business growth.
Build secure, scalable, and intelligent platforms that power modern enterprises.
Build intelligent, connected, and autonomous systems that operate in the real world.
Flexible engineering capacity with predictable delivery, ownership, and outcomes.
Uncover the transformative potential of digital and mobile solutions for your industry

 Last Updated: Apr 1, 2026
Apr 1, 2026
Last Updated: Apr 1, 2026
Apr 1, 2026  1013
1013  12 min. Read
12 min. Read



Key Takeaways
The investor meeting was supposed to be a layup.
Your AI agent, the one that’s been flawless in internal testing for weeks, sits on the screen. You’re demoing it to a $50M fund, showing how it can handle a complex multi-turn customer support conversation. The agent greets the investor, asks their name, digs into their hypothetical product question.
Then, three exchanges in, something breaks.
The agent forgets the investor’s name. Asks it again. Then loops on the same clarifying question twice. The room goes quiet. You’re already reaching for the laptop to kill the demo, but not before the lead partner mutters something about “not production-ready.”
This scenario is universal enough that it’s become a running joke in builder communities. The nightmare isn’t imagined.
It’s inevitable.
When agents operate beyond 20-30 turns, coherence degrades. The agent still has the information technically present in its context window, but its ability to retrieve and act on that information becomes measurably worse.
The problem has a name: context rot.
And it’s about to become the primary blocker preventing your 2026 AI agents from making it to production.
Context rot is the gradual degradation in AI agent performance as the context window fills over time.
Each message, tool call, file read, and response adds more tokens. Eventually, the model is processing so much information that the signal-to-noise ratio drops, and its output quality drops with it.
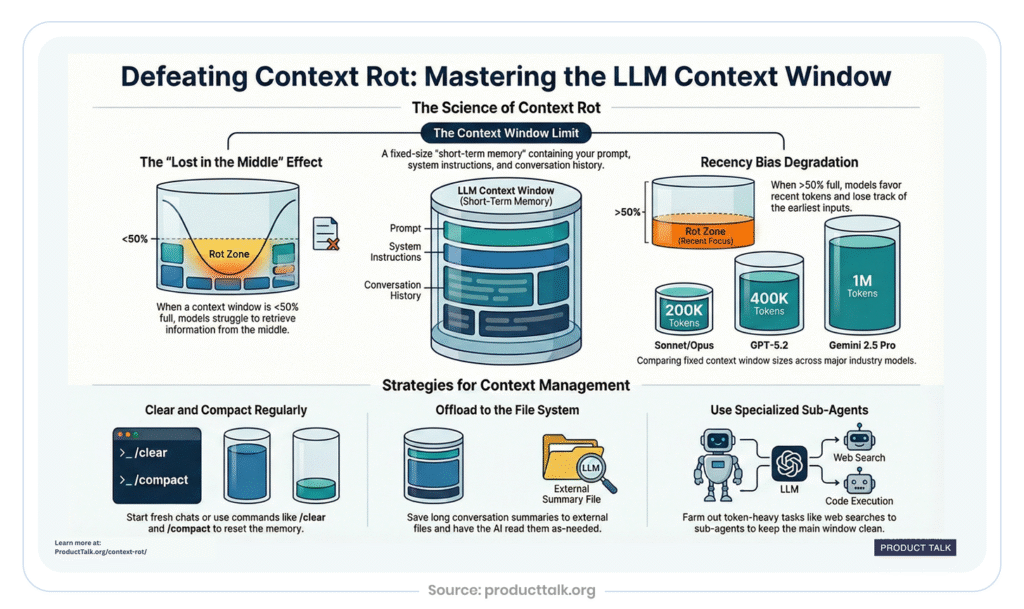
The technical mechanism: In transformer-based models, attention operates across the entire context. As context grows, the attention weights for any individual token become proportionally smaller. More importantly, research has documented a phenomenon called “Lost in the Middle”: language models consistently underperform at retrieving information from the middle of long contexts. Models give stronger attention to tokens near the beginning and end, while information buried in the middle gets systematically underweighted.
For an AI agent, this means:
The practical consequence: an agent doesn’t fail loudly. It fails subtly, confidently, and repeatedly. It operates based on incomplete or degraded understanding of prior context.
Context rot appears predictably in production deployments. Understanding the patterns helps you recognize and address it before it reaches users.
According to research on long-context behavior in language models, larger context windows delay context rot but don’t prevent it. A 1M-token context window doesn’t mean the model reads every token with equal care. Retrieval accuracy drops measurably as context length increases, even when the relevant information is technically present.
Source: TechAhead AI Team
Why? Noise accumulates faster than signal. Most of what fills a long conversation or coding session is noise: intermediate debugging output, outdated file versions, failed tool calls, tangential research threads. This competes with critical instructions and current state for the model’s limited attention capacity.
Agents that rely on tools (API calls, code execution, file reads) face a particular vulnerability. Each tool call, and its often-verbose output, gets appended to context. A single feature implementation might involve 40-50 tool calls. A single test run output can be thousands of tokens.
After a few hours of sustained work, the tool call history dominates the context. The model is forced to attend to stale outputs and intermediate states that have long since become irrelevant.
When agents work with codebases or complex systems, they read files and inline content into context. As the session progresses, files change, but older versions persist in context. After 50+ exchanges, the version of a file sitting in the agent’s context may no longer match what’s actually on disk.
The agent is reasoning about a world that no longer exists. The decisions it makes are based on stale information, leading to wrong assumptions and cascading errors.
UC Berkeley Multi-Agent Study (2026)
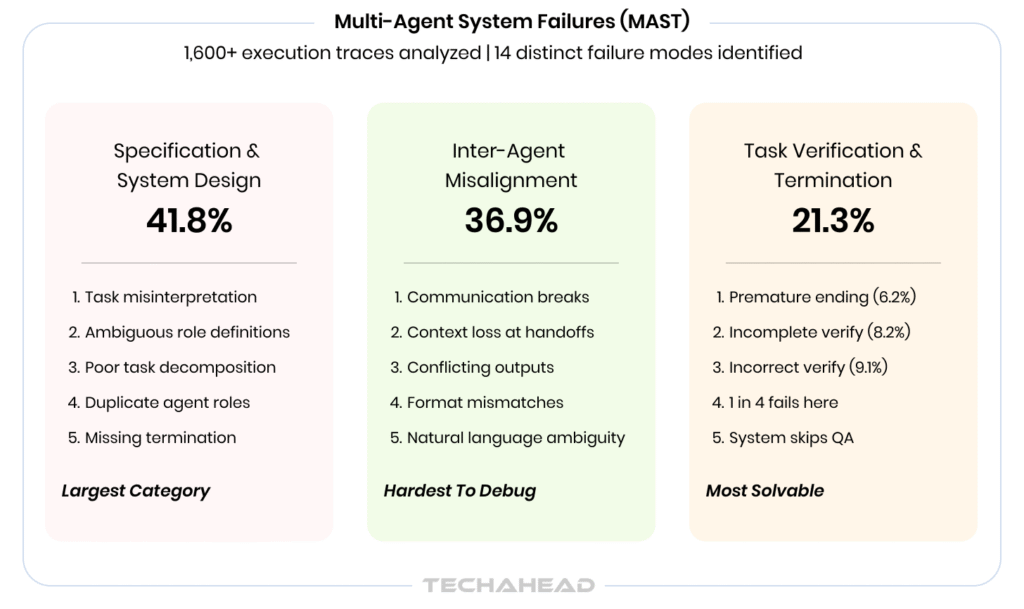
The most rigorous study on multi-agent system failures is the MAST (Multi-Agent System Failure Taxonomy) research, which analyzed over 1,600 annotated execution traces across 7 popular frameworks.
Key finding: Multi-agent LLM systems fail between 41% and 86.7% of the time on standard benchmarks.
But here’s what’s critical: Roughly 79% of all failures come from specification and coordination problems, not infrastructure or model-level issues. Developers tend to focus on picking the right model or optimizing tokens. The data says the real problems are upstream: context management, state tracking, and communication between agents.

`Multi-Agent System Failure Taxonomy (MAST Research)
Context Loss During Agent Handoffs
One of the 14 identified failure modes in the MAST taxonomy is “context loss during handoffs”, where context collapses as agents pass messages and context windows fill up, causing agents to lose track of earlier decisions and start contradicting themselves or each other.
This isn’t theoretical. It’s happening in production deployments right now.
The problem: Enterprise teams often treat context windows like infinite resources. They dump entire documentation libraries into every request, load hundreds of past conversation turns, include every possible tool definition “just in case,” and pre-fetch data that might never be needed.
What happens: Models lose focus. Studies show that as context length increases, accuracy decreases, a phenomenon called “context rot.” Even models with 200K token windows experience degradation when critical information is buried in noise.
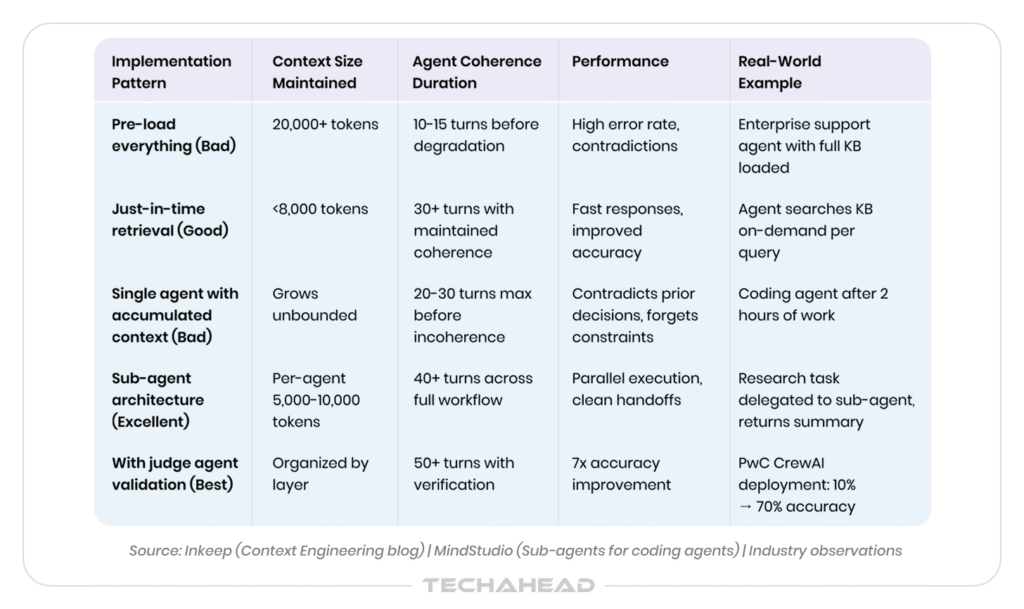
The reality: When customer support agents have access to the entire knowledge base, full CRM history, past tickets, and company policies, often 20,000+ tokens before the customer even asks a question, performance degrades measurably.
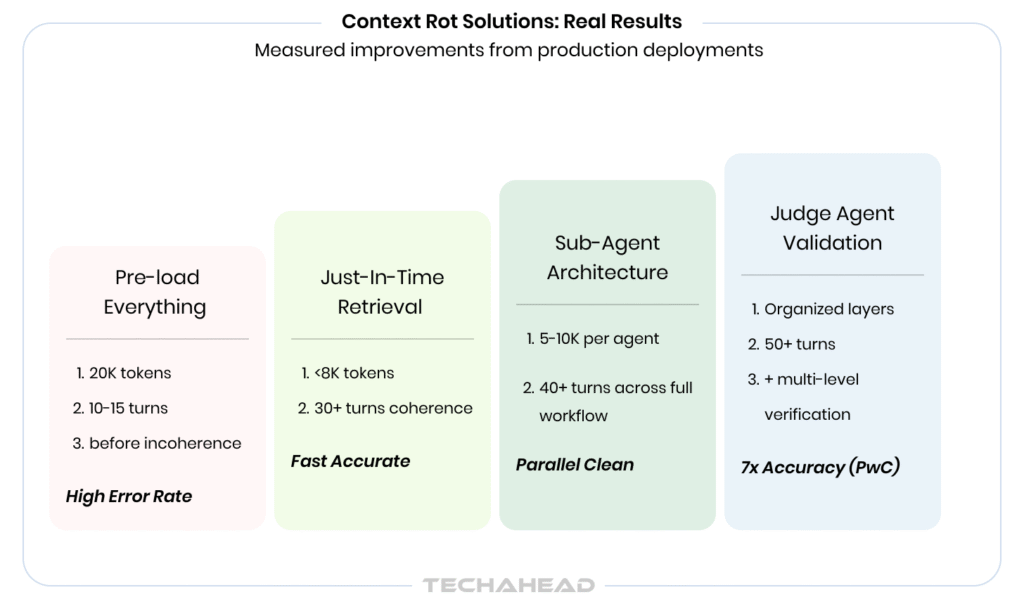
What actually works: Just-in-time retrieval. Give agents tools to fetch specific data on-demand rather than pre-loading everything. Like humans who use file systems and search rather than memorizing everything, agents perform better when they navigate information dynamically.
Result from implementation: Teams using just-in-time retrieval keep context under 8K tokens, responses are faster, and accuracy improves.

The problem: If you’ve spent a few hours with an AI coding agent, asking it to implement features, fix bugs, read documentation, and refactor code, you’ve probably noticed something odd. The agent starts sharp. By hour two, it’s contradicting earlier decisions, ignoring constraints you set at the start, and making mistakes it wouldn’t have made in the first twenty minutes.
Why it happens: The mechanics come down to how attention works in transformers. Every token in the context window competes for the model’s attention. In a short context, relevant tokens dominate. In a long one, hundreds of messages, thousands of lines of code, dozens of failed debug attempts, relevant tokens get buried.
The result is a model that over-weights recent tokens, contradicts earlier decisions, loses track of instructions it was given at the start, and increasingly hallucinates details it can no longer reliably retrieve.
Why bigger context windows don’t solve it: Larger windows delay context rot, they don’t prevent it. Empirical testing consistently shows that retrieval accuracy drops as context length increases, even when the relevant information is technically present in the window. A 1M-token context window doesn’t mean the model reads every token with equal care.
Source: Inkeep (Context Engineering blog) | MindStudio (Sub-agents for coding agents) | Industry observations
What actually works: Sub-agents for task isolation. Instead of one agent accumulating infinite context, delegate discrete tasks to specialized sub-agents. When a sub-agent completes its task, only the distilled result comes back. The sub-agent’s working memory, all the exploration, intermediate steps, failed attempts, is discarded.
This is the key asymmetry: the research messiness never touches the main context. A sub-agent doesn’t dump its full context back to the orchestrator. It produces a structured summary. The orchestrator receives clean signal instead of raw exploration.
The research: The MAST taxonomy breaks down failure modes into three categories:
The failure in context: When agents pass messages and context windows fill up, earlier context is lost. Agents contradict themselves or each other without awareness. Context collapse happens as agents pass messages and context windows fill up. Agents lose track of earlier decisions and start contradicting themselves or each other.
Source: TechAhead AI Team
Measured result: PwC improved CrewAI code generation accuracy from 10% → 70% by implementing judge agent validation with structured verification loops.
What the data reveals: Roughly 79% of all failures come from specification and coordination problems, not infrastructure or model-level issues. Developers tend to focus on picking the right model or optimizing tokens. The data says the real problems are upstream, in bad specs and broken coordination.
Instead of pre-loading all possible information, give agents tools to fetch specific data on-demand.
Bad tool design returns everything at once: “get_all_tickets() → Returns 1000 tickets with full conversation history.”
Good tool design uses progressive disclosure: “search_tickets(query, limit=5) → Returns ticket IDs and summaries” and “get_ticket_details(ticket_id) → Fetches full detail only when needed.” The second approach lets agents progressively disclose information, loading details only when relevant.
Result: Context stays manageable, signal-to-noise ratio improves, response latency decreases.

Delegate discrete tasks to specialized sub-agents with isolated contexts.
The orchestrator manages goals and key decisions, while sub-agents handle specific tasks in their own isolated contexts. When a sub-agent completes its task, only the distilled result comes back to the orchestrator. The sub-agent’s working memory, all the exploration, the intermediate steps, the failed attempts, is discarded.
Specific pattern: Before the orchestrator writes any code, it delegates research tasks. Sub-agent 1 surveys the existing codebase for specific functions and returns a summary. Sub-agent 2 researches third-party APIs and returns structured guidance. In a single-agent system, these tasks would be sequential and each would deposit residue in the shared context. With sub-agents, they run in parallel, independently, and return clean outputs.
Result: Main context stays focused, noise is eliminated, parallel execution accelerates work.
Treat agent specifications like API contracts. Define roles with JSON schemas. Make every constraint explicit. Specify exact input/output formats, success criteria, and stop conditions.
Example of production-grade spec:

Specification clarity alone eliminates the single largest category of system failures.
Anthropic’s Model Context Protocol (MCP) enforces schema-validated messages using JSON-RPC 2.0, giving every message an explicit type, validated payload, and clear intent. Block, Replit, and Sourcegraph have deployed MCP for production multi-agent workflows.
Result: No format mismatches, clear intent, easier debugging, better coordination.
Systems need multi-level verification: unit checks at the agent level, integration checks across outputs, and final validation against original task requirements. The most effective pattern is the independent judge agent. This separate agent evaluates the final output using an isolated prompt, separate context, and predefined scoring criteria. It should not share context with producing agents, or it risks joining the same collective reasoning loop.
Measured result: PwC reported a 7x accuracy improvement (from 10% to 70%) after implementing structured validation loops with judge agents in their CrewAI-based code generation pipeline.
Context rot is real. It appears predictably in production. It’s solvable, but solutions require architectural changes, not just prompting.
Teams that acknowledge this early, that design for state management and context discipline from day one, deploy agents that work reliably. Teams that treat it as a tuning problem end up with degraded production systems they can’t explain.
The agents that succeed in 2026 won’t be the ones with the most impressive models. They’ll be the ones with the most disciplined context management and clear specifications.
I’ve shipped systems for 16 years. Context rot will make or break your agents in 2026.
We made every mistake in this blog: Dumped knowledge bases into context, built agents with 20+ tools, hoped better models would fix things. When we stopped optimizing for capability and started optimizing for clean contexts, everything changed.
Agents that failed by turn 20 stayed coherent past turn 50.
The hard truth: context rot isn’t a model problem. It’s a discipline problem. 79% of failures come from specifications and coordination, not capability gaps.
The opportunity is clear: most teams ignore this.
The teams that build clean systems win.

Context rot is gradual performance degradation as conversation context grows, where early instructions fade from the model’s attention.
Context rot becomes measurable around 20-30 turns; degradation accelerates significantly beyond 40 turns in most implementations.
No. Larger models delay context rot but don’t prevent it; attention degradation is fundamental to transformer architecture.
Yes. Sub-agents, hierarchical retrieval, judge agents, and strict specifications fix context rot in already-deployed systems reliably.
Start with just-in-time retrieval and judge agents; layer sub-agents and strict specs as systems scale.
We use cookies to ensure our website functions properly, improve performance, and provide a personalized experience. You can choose which types of cookies to allow below.
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Help us understand site traffic and user interactions so we can improve performance and usability.
Enable enhanced functionality and personalization such as language or region preferences.
Used to deliver relevant ads, track campaign performance, and measure advertising effectiveness.