







Staff Augmentation
Access top-tier talent on demand: Dedicated, Hourly, or Flexible.






























 Copy Link
Copy Link Share on X
Share on X Share on Facebook
Share on Facebook Share on LinkedIn
Share on LinkedIn
“The combination of retrieval and generation is what finally makes large language models ready for mission-critical business applications. You get the best of both worlds: powerful reasoning with verifiable facts.” — Jason Wei, Research Scientist at OpenAI
This vision of reliable, fact-grounded AI is exactly what enterprise leaders need, but achieving it requires more than just deploying an LLM.
You have likely experienced the frustration: your LLM hallucinates facts, provides outdated information, or simply cannot access your company’s proprietary data. You are not alone; studies show that 58% of enterprises struggle with AI accuracy and data integration challenges. While Large Language Models offer incredible potential, their limitations become glaring when you need reliable, business-specific answers.
Here Retrieval-Augmented Generation (RAG) systems bridge between LLM capabilities and your enterprise knowledge. However, poorly designed RAG architectures create new problems: slow response times, irrelevant retrievals, and security vulnerabilities that can compromise sensitive data.
Research indicates that organizations with optimized RAG implementations achieve 3-4x better accuracy rates and 60% cost reduction compared to basic setups. Today, in this guide, we will walk you through proven architectural best practices that solve these challenges.
Key Takeaways
- RAG systems bridge the gap between LLM capabilities and enterprise knowledge bases effectively.
- RAG combines information retrieval with text generation for context-aware, accurate AI responses.
- Hybrid retrieval combines dense vector search with keyword matching for improved precision.
- RAG systems reduce AI hallucinations and improve factual accuracy without retraining large models.
- Dynamic data updates keep RAG systems current without requiring full model retraining.
What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) is an AI framework that enhances large language models (LLMs). It combines information retrieval with text generation. Instead of relying solely on pre-trained data, a RAG system retrieves relevant, up-to-date documents from external sources and uses that information to generate context-aware responses.
Key Features of Retrieval-Augmented Generation (RAG)
- Connects LLMs with external knowledge bases for reliable outputs.
- Reduces hallucinations and improves factual accuracy.
- Expect domain-specific adaptability without retraining large models.
- RAG allows transparent and explainable outputs with source attribution for verification.

Key Components of RAG Systems Architecture
If you are designing one for your enterprise, you need to understand the architecture’s building blocks. Let’s walk through each key component and how they come together to form an intelligent RAG system.
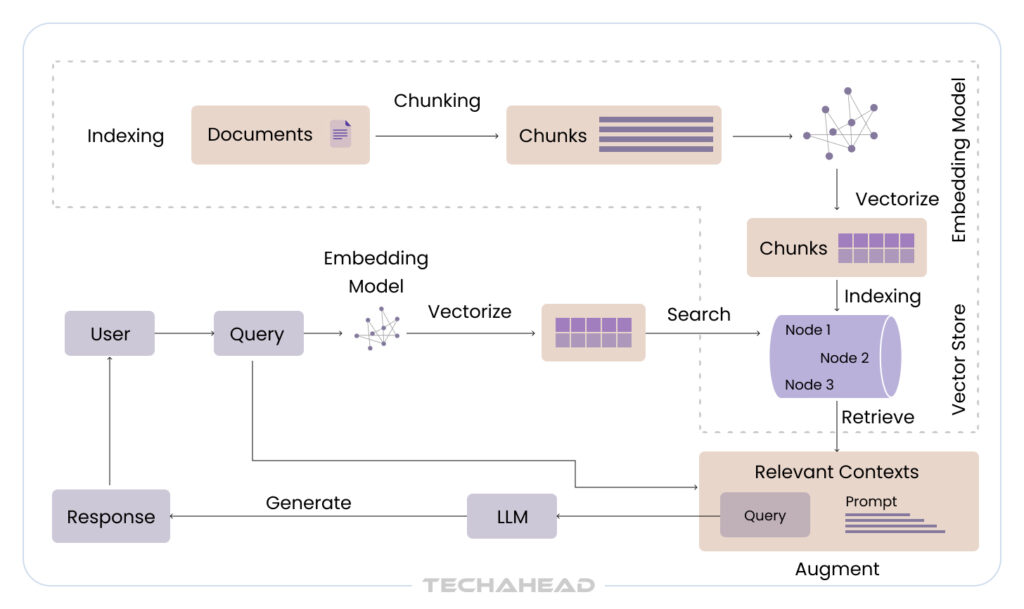
User Input and Authentication
Everything starts with the user. When someone interacts with your system, whether through a chatbot, dashboard, or API; the first step is input processing and secure access control. Authentication means the user is who they claim to be.
Why it matters for enterprises:
- Authentication frameworks like AWS Cognito and Azure AD manage user access and maintain compliance with standards like GDPR and HIPAA.
- Fine-grained access controls allow your system to personalize results while keeping sensitive data safe.
- Auditing each interaction gives accountability across enterprise workflows.
Once authenticated, the user’s query proceeds to the next step, query rewriting and encoding, where the real intelligence begins.
Query Rewriting and Encoding
Now that you trust the user, the system needs to understand what they want. RAG systems interpret queries differently than traditional search engines. Here, they use embedding models to capture meaning, not just keywords.
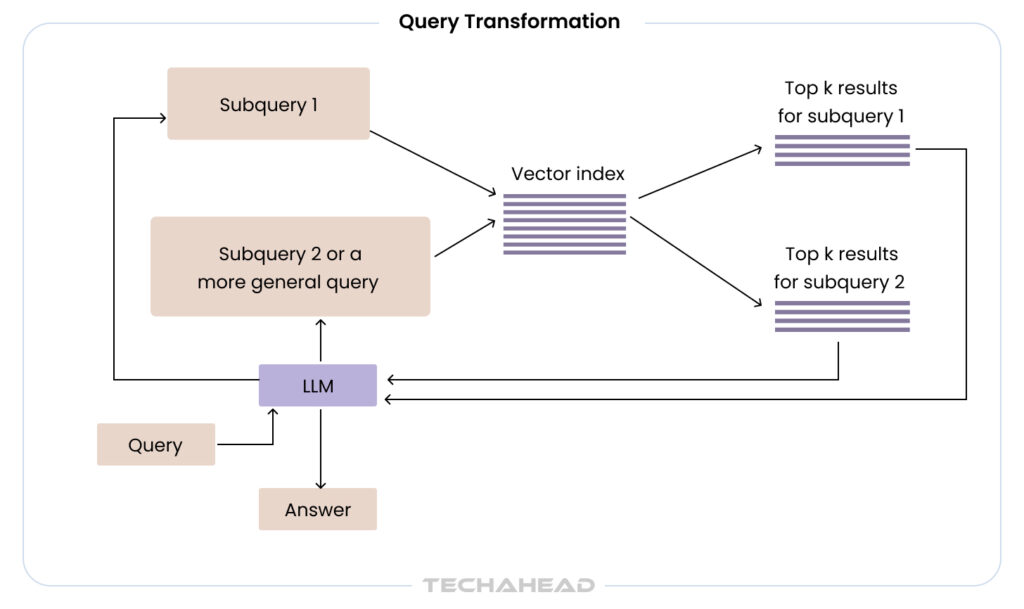
What happens here:
- Query preprocessing: The query is cleaned, tokenized, and reformulated into a standardized format.
- Vector encoding: Advanced embedding models (like OpenAI’s text-embedding models or BERT-based encoders) translate the query into a high-dimensional vector that represents its semantics.
- Intent analysis: Query rewriting enhances intent detection by rephrasing ambiguous questions.
RAG structures queries as vectors and makes sure retrieval algorithms find results based on meaning rather than literal word matches.
Information Retrieval Mechanisms
Yes, this is the engine room of your RAG system. Once you have the vector representation of the query, the retrieval component goes to work. It searches your enterprise knowledge base or document repository for relevant passages.
Key retrieval processes:
- Dense retrieval: The system compares the query vector to document embeddings stored in a vector database, such as Pinecone, FAISS, or Weaviate.
- Hybrid retrieval: Some advanced RAG implementations combine dense retrieval with keyword or semantic search for better precision.
- Source integration: You can connect APIs, databases, or internal document stores securely without retraining your model.
This retrieval process is crucial; remember, if your retriever cannot supply quality data, your LLM will produce irrelevant answers.
Ranking and Response Generation
After retrieval, the system often has multiple candidate documents. So, how does it decide which ones matter most? That is where ranking and response generation come in.
Step-by-step process:
- Ranking: The RAG pipeline uses similarity metrics like cosine similarity to score the retrieved passages and prioritize the most relevant ones.
- Context fusion: Top-ranked results are appended to the user’s query as contextual information before being sent to the LLM.
- LLM generation: The large language model synthesizes this augmented input to generate a contextually rich, fact-based answer.
Indeed, this is the heart of the RAG system combining learning from the model with freshly retrieved data to produce answers.
Output Validation and Guardrails
Even the best retrieval and generation mechanisms can occasionally produce biased, incomplete outputs. Output validation layers act as your system’s quality control and compliance check.
Best practices for safe output:
- Validation filters: Rule-based or AI-based filters ensure no personally identifiable information (PII) or sensitive data leaves your system.
- Factual consistency checks: The system verifies whether generated statements align with retrieved data before displaying the result.
- Moderation and transparency: Including source citations and confidence scores builds user trust.
For enterprise deployments, this stage is important for maintaining compliance and accuracy.
Enterprise Architecture Patterns for RAG
When deploying RAG across enterprise applications, you need to focus more on architecture especially for scalability and performance. Common patterns include:
Centralized Architecture
A single retrieval and generation pipeline serves multiple applications, ideal for organizations with uniform knowledge bases.
Federated Architecture
Multiple domain-specific retrievers route to a shared LLM layer, which allows department-level customization.
Cascading RAG Models
First, a lightweight retrieval model handles general queries; complex ones escalate to a more capable (but costlier) model.
Streaming RAG Pipelines
Used for real-time analytics or live data environments that continuously update vector databases to capture fresh information.
These patterns allow your enterprise to tailor RAG to your scale and compute budgets.
Bringing It All Together
A well-designed RAG architecture effectively bridges your enterprise’s static data with dynamic reasoning needs. When you design your own RAG system, think modularly. You are building a living architecture that continuously learns, retrieves & responds. With RAG and LLM, you can turn your vast enterprise data into actionable insights.
Common RAG System Architecture Workflow
When you design a Retrieval-Augmented Generation (RAG) system, it essentially works by combining two core parts: the Retriever and the Generator. Here is the brief about the workflow:
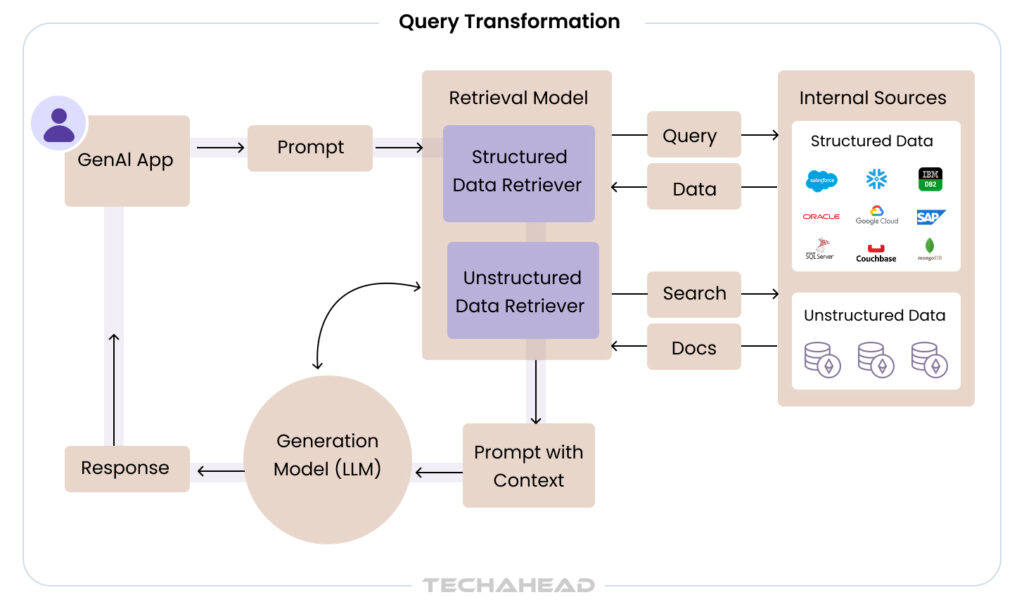
User Query Input
You start with a user’s natural language query or prompt. This input is what your users want answers or information about.
Query Encoding
Before the system finds relevant documents, it converts the query into a numerical vector using an embedding model. Think of this as transforming human language into a language your system’s search engine can understand.
- Retrieval from Vector Database: With the query vector in hand, your system searches a pre-indexed set of documents (often stored in a vector database). The retriever finds documents semantically closest to the query.
- Contextual Augmentation: These retrieved documents are passed to the generator, commonly a large language model (LLM), which combines the original query with this fresh context to generate a detailed response.
- Response Generation: The model synthesizes the user’s question with the external knowledge to produce a well-informed answer tailored to the query.
- User Output: Finally, the system presents the enriched response back to the user.
It delivers up-to-date, context-sensitive answers without relying solely on static model training data.
Advanced RAG Architecture Enhancements
You can consider the following advanced architectural improvements for better outcome from your RAG:
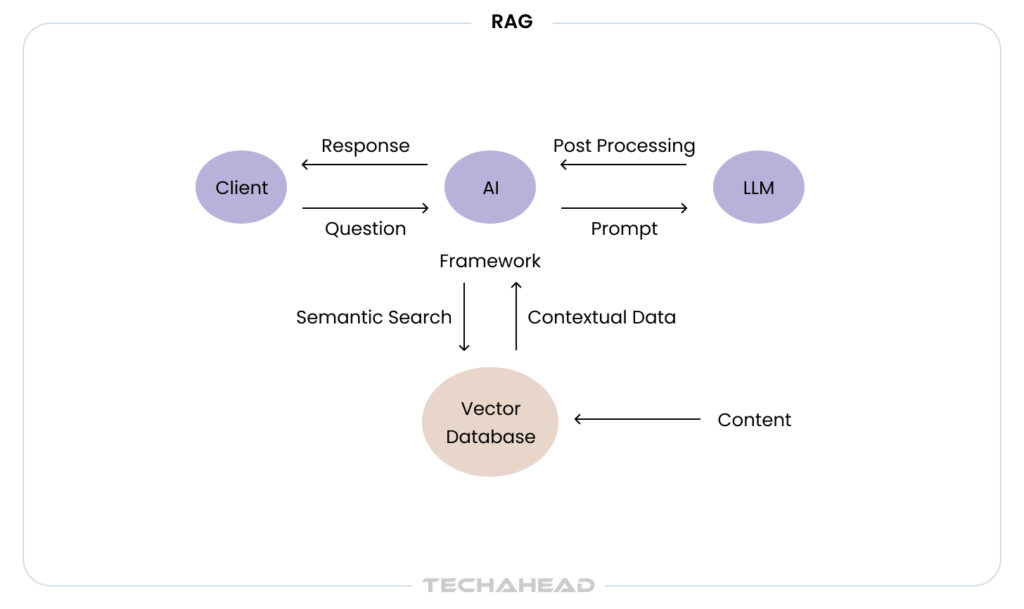
Hierarchical Document Chunking
Instead of retrieving and feeding entire documents, break them into manageable, context-aware chunks. It keeps the retrieval focused and reduces noise. It lets the generator work with the most relevant text pieces.
Dynamic Data Updates
Implement periodic or real-time indexing of documents so your system stays current without the need to retrain the underlying LLM. This is essential for enterprises with rapidly evolving data, like legal or financial documents.
Relevance Scoring and Filtering
Use custom ranking algorithms to push the most relevant documents higher in the retrieval list. You can add a filtering layer to prevent irrelevant or low-quality information from impacting the generation phase.
Multi-Modal Retrieval
Extending beyond just text, you can add image, audio, or structured data sources to enrich context further that makes your RAG system versatile across domain needs.
Explainability Features
Build mechanisms to attach source references and confidence scores to your responses, so users can easily verify and trust the output.
Modular and Scalable Architecture Approaches
When designing your RAG system, think about modularity and scalability to adapt easily as your enterprise grows:
Modular Design
Split your system into clear, interchangeable components: retriever, generator, indexer, API gateway, and authentication. With this separated design, you can upgrade parts independently, such as switching to a better retrieval algorithm or swapping LLM vendors.
Microservices Architecture
Deploy each major component as a microservice that allows horizontal scaling. For example, if your user base grows, you can scale out retrieval microservices without impacting generation.
Cloud-Native and Serverless
Use cloud services like vector databases, managed LLM APIs, and serverless functions to reduce infrastructure complexity and improve uptime.
Monitoring
Incorporate real-time monitoring for system health, query latency, and user interaction patterns. These insights let you optimize performance and catch issues before they impact users.
You can apply these workflows to design a flexible RAG system tailored to your enterprise.

Best Practices in Designing RAG Systems with LLMs
Designing Retrieval-Augmented Generation (RAG) systems for enterprise use involves several technical best practices that ensure your system is reliable. When building your RAG system, keep the following elements in mind:
Provide Context and Source Attribution for Outputs
One of the most important trust-building practices is providing a clear context around how outputs are generated. When your users receive responses, they should be able to see which documents or data sources were used.
Such transparency helps users verify the relevance of the information. It is essential in enterprise environments like compliance, legal, or customer support. Source attribution enhances credibility and links answers back to authoritative documents in real-time.
Integrate Enterprise Data Sources
Integrate data feeds from your enterprise’s core systems, such as CRM, ERP, and other operational software. These data sources contain up-to-date information suitable for getting relevant business related answers.
Feeding this data directly into the retrieval database reflects your company’s unique context. Your system responds with insights grounded in internal knowledge as well as external content.
Continuous Evaluation and Monitoring
A RAG system is never “done”; continuous evaluation is essential to spot issues like retrieval inaccuracies or bias. Establish monitoring dashboards tracking key metrics like retrieval quality, response latency, token usage, and error rates.
Regularly review system outputs for consistency, especially on edge cases. User feedback loops help identify improvement areas under different load conditions for reliability.
Dynamic Data Loading and Real-time Updates
Your data landscape changes rapidly, so your RAG system must support dynamic data updates. Implement mechanisms to ingest new data or refresh embeddings without full downtime.
Real-time updates minimize stale information responses and maximize relevance. It is essential for enterprises handling high volumes of evolving information like product details, customer records, or market trends.
Maintain Hierarchical Document Structure
Documents often contain natural hierarchies: sections, subsections, paragraphs, in short, they provide meaningful context. Maintaining this hierarchical structure in your RAG system improves retrieval precision and the logical flow of information in generated responses.
Instead of treating whole documents as one chunk, preserve their structure and metadata for granular searches. It means you can expect more contextually relevant answers.
Implement Effective Document Chunking Strategies
Chunking refers to how you break down large documents into smaller, manageable segments. So effective chunking balances size and context; that is why chunks must be small enough for efficient similarity searches but large enough to retain meaning.
Oversized chunks dilute relevance, while overly small fragments may lose context. You can experiment with chunk sizes that align with your document types for optimized retrieval speed.
Optimize Retrieval with Relevance Scoring
Finally, retrieval quality depends heavily on how you score and rank chunks. You can use a hybrid RAG approach combining semantic vector similarity with traditional keyword-based algorithms. Calibrate relevance scoring thresholds based on business goals for compliance-critical tasks. Fine-tune ranking algorithms regularly with real user queries for getting the best results that satisfy your users’ intent.
With these best practices, you design a RAG system that is transparent, adaptive and integrated into your enterprise’s data ecosystem. These techniques make sure your LLM not only generates fluent language but also up-to-date knowledge tailored for your business needs.
How Can You Plan for Infrastructure Scalability in RAG Systems?
Planning for scalability means designing a modular architecture where each component data ingestion, retrieval, embedding, and response generation can be scaled independently. Use cloud-native orchestration tools like Kubernetes and auto-scaling features to automatically add or reduce resources based on load.
Besides that, you can implement elastic storage systems that dynamically expand as data grows, and adopt caching strategies for frequently queried data. Moreover, regular performance benchmarking is essential to identify issues early on that allows you to ensure your system remains responsive as user demand increases.
How Do You Handle Increased Data Volume and User Load Efficiently?
You can consider the following strategies to handle increased data volume:
- Distribute data and workloads across multiple servers using sharding and replication.
- Use scalable cloud storage solutions (e.g., AWS S3, Google Cloud Storage) for large datasets.
- Implement load balancers to dynamically route incoming queries.
- Cache frequently accessed data or queries to reduce retrieval latency.
- Optimize query execution with parallel processing and indexing strategies.
How Do You Ensure Data Privacy and Secure System Design?
For this, you can follow these strategies:
- Use encryption protocols (TLS, AES) for data both at rest and in transit.
- Implement role-based access control (RBAC) to restrict sensitive information.
- Anonymize or pseudonymize data during ingestion, especially for regulated data.
- Regularly conduct vulnerability testing and vulnerability assessments.
- Incorporate secure enclaves and differential privacy techniques for highly sensitive data.
Benefits of Enterprise for Designing RAG Systems with Large Language Models
Enterprise-grade RAG systems with Large Language Models transform into powerful business tools that deliver measurable ROI and sustainable competitive advantage. Here are the business benefits:
Enhanced Data Security & Governance
- Enterprise-grade RAG provides security frameworks with role-based access controls; it means your sensitive business data remains protected while being leveraged by LLMs.
- Centralized governance policies help you maintain compliance with industry regulations (GDPR, HIPAA, SOC 2).
- Audit trails and data lineage tracking give you complete visibility into how your proprietary information flows through the RAG pipeline.
Scalability & Performance Optimization
- Enterprise RAG architectures handle millions of documents and concurrent users without degradation.
- Distributed vector databases and caching mechanisms mean sub-second query responses even as your knowledge base expands exponentially.
- Load balancing and auto-scaling capabilities maintain consistent performance during peak usage periods.
Cost Control & ROI Maximization
- Strategic resource allocation through enterprise RAG systems reduces unnecessary LLM API calls by 60-80%.
- Reusable knowledge bases eliminate redundant data processing across departments.
- Fine-grained monitoring tools provide actionable insights into usage patterns.
Seamless Integration & Customization
- Enterprise RAG frameworks integrate natively with your existing tech stack: CRMs, ERPs, data warehouses, business intelligence platforms.
- Customizable retrieval strategies allow you to tune precision and recall based on specific business use cases.
- API-first architecture allows your development teams to build tailored applications that leverage institutional knowledge.
Competitive Advantage through Knowledge Leverage
- Transform decades of accumulated business intelligence, documentation, expertise into actionable insights.
- Reduce onboarding time for new employees by 50% through AI-powered access to organizational knowledge.
- Accelerate decision-making processes with context-aware responses grounded in your company’s historical data and best practices.
Why is Compliance with Regulations and Policies Critical?
Adhering to regulations like GDPR, HIPAA, or industry-specific standards protects your enterprise from legal and financial penalties. It involves implementing consent mechanisms, maintaining auditable logs of data handling that makes sure data retention aligns with policy. Automating compliance checks using governance tools simplifies ongoing adherence, especially when managing large, sensitive datasets.
How can RAG Systems Integrate Seamlessly with Enterprise Tools?
Integration involves designing APIs and connectors for core enterprise systems like CRMs, ERPs, and analytics platforms. Use middleware, such as Kafka or REST APIs to synchronize data and workflows across platforms. It retrieves contextual enterprise data in real-time that enhance the relevant insights for your organization.
Conclusion
Designing RAG systems requires strategic architectural decisions that balance performance and scalability. You can implement the best practices outlined above to unlock genuine business value for your organization. Ready to transform your enterprise data into a competitive advantage?
Partner with TechAhead, your trusted RAG development company, to architect and deploy production-ready RAG systems tailored to your unique business needs. Let’s build the future of AI-powered intelligence together.

How does RAG differ from traditional fine-tuning of Large Language Models?
RAG retrieves relevant information from external knowledge bases in real-time, while fine-tuning modifies the model’s internal parameters with training data. RAG offers dynamic updates without retraining, lower costs, and better source attribution. Fine-tuning creates specialized models but needs extensive resources and cannot easily incorporate new information without complete retraining cycles.
How do I choose the right vector database for my RAG implementation?
You can consider scalability requirements, query latency needs, budget constraints, and integration capabilities. Evaluate options like Pinecone for managed solutions, Weaviate for hybrid search, or Milvus for open-source flexibility. Assess filtering capabilities, metadata support, and multi-tenancy features. Run benchmarks with your actual data volume and query patterns to ensure optimal performance for your use case.
How do hybrid search approaches improve RAG system accuracy?
Hybrid search combines semantic vector search with traditional keyword-based methods, capturing both contextual meaning and exact term matches. This dual approach reduces missed retrievals, improves precision for technical queries, and handles acronyms or specific terminology better. The result is more comprehensive document retrieval, leading to higher-quality context for LLM responses and improved overall system accuracy.
How long does it take to implement a production-ready RAG system?
Implementation timelines vary from 8-16 weeks depending on complexity, data volume, integration requirements. Basic prototypes can launch in 2-4 weeks, while enterprise-grade systems with security frameworks, compliance controls, and custom integrations require 12-16 weeks. Factors include data preparation complexity, existing infrastructure compatibility, team expertise, and required testing phases before production deployment.
What are common challenges to avoid when designing RAG architectures?
Avoid poor chunking strategies that split context inappropriately, inadequate metadata tagging, insufficient retrieval result ranking, and neglecting query optimization. Do not overlook response latency monitoring or security controls. Prevent context window overflow and plan for data refresh mechanisms to maintain accuracy over time.


