
Staff Augmentation
Access top-tier talent on demand: Dedicated, Hourly, or Flexible.

























 Copy Link
Copy Link Share on X
Share on X Share on Facebook
Share on Facebook Share on LinkedIn
Share on LinkedIn
Every enterprise leader asks the same question: what does AI actually cost, and is it genuinely worth it? While enterprise AI usage surged over 3,000% this past year, 83% of organizations remain stuck in early-stage experimentation loops that never reach production.
Despite the hype, lack of budget and integration complexity remain top barriers for half of all AI leaders, and that is before factoring in security vulnerabilities and legacy infrastructure.
The hard truth? Most enterprises are not failing at AI because the technology does not work. They are failing because they built on the wrong foundation. The difference between enterprises bleeding money on AI experiments and those generating measurable returns comes down to one thing: architecture.
If you are an enterprise leader evaluating where to invest, what to build, and how to do it without burning through budget or compromising your data, this blog gives you the technical clarity and strategic framework to make that call confidently.
Key Takeaways
- RAG grounds AI responses in your live business data always.
- Choosing the wrong LLM directly impacts cost, compliance, and accuracy.
- Multiple specialized agents outperform single AI models on complex workflows.
- Role-based access controls are non-negotiable in enterprise AI deployments.
- Start with RAG, validate accuracy, then scale to multi-agent complexity.
What is Retrieval-Augmented Generation (RAG)?
Think of RAG development services as giving your AI a live library card. Instead of relying solely on what it learned during training, RAG lets your AI retrieve fresh, relevant information from your own business data; documents, databases, knowledge bases before generating a response.
Grand View Research reports the global RAG market at USD 1.2 billion in 2024, projected to hit USD 11.0 billion by 2030 with a 49.1% CAGR from 2025 onward.
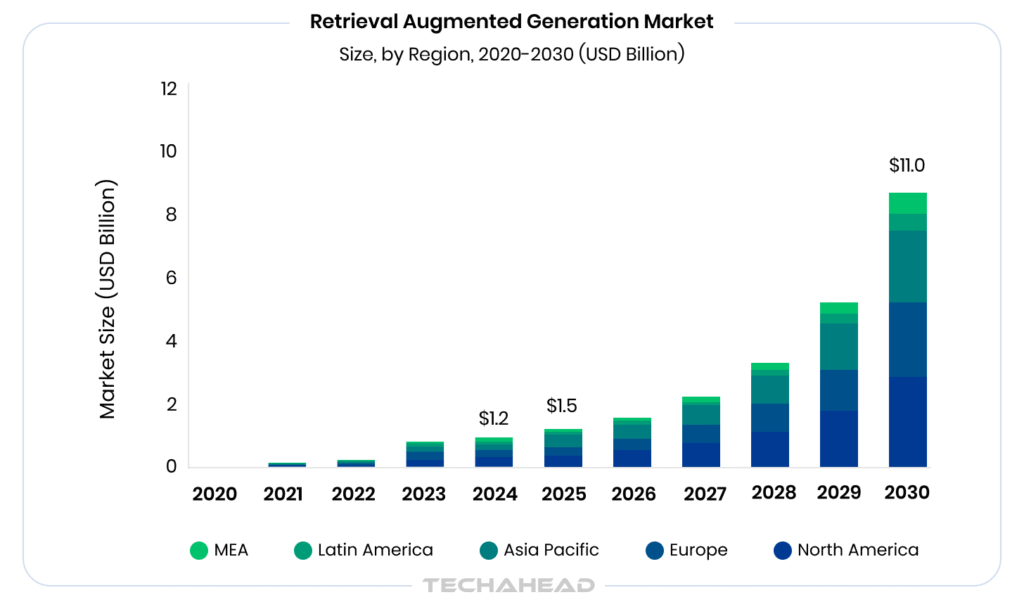
The result? With RAG development services, you get accurate, context-aware answers grounded in your reality, not outdated training data.
RAG vs. Fine-Tuning: Which Approach Actually Fits Your Business?
When enterprise leaders first explore AI, this question almost always comes up; should we fine-tune a model or use RAG? Both approaches make your AI smarter, but in very different ways. Fine-tuning teaches the model new behavior by retraining it on your data. RAG, on the other hand, gives the AI access to your data at the moment it needs it. For most enterprises, the answer comes down to three things: how often your data changes, your budget, and how fast you need to move.
Here is a comparison table for better understanding:
| Factor | RAG | Fine-Tuning |
| Best For | Dynamic, frequently updated data | Static, behavior-specific tasks |
| Data Freshness | Always up-to-date | Frozen at training time |
| Cost | Lower — no retraining needed | Higher — compute-intensive |
| Implementation Speed | Fast (days to weeks) | Slow (weeks to months) |
| Customization Level | Moderate | High |
| Hallucination Risk | Lower (grounded in source docs) | Higher without guardrails |
| Maintenance | Update your data, not the model | Requires periodic retraining |
| Ideal Use Case | Enterprise knowledge bases, support bots, internal search | Tone/style adaptation, domain-specific reasoning |
| Technical Complexity | Moderate | High |
| Scales With Business Data? | Yes | Not easily |
Bottom Line for Enterprise Owners?
If your business data changes frequently; pricing, policies, product info, compliance docs, RAG is almost always the smarter starting point. Fine-tuning shines when you need the AI to behave differently, not just know more.
From Naive RAG to Agentic RAG: The Architecture Evolution You Need to Know
Early RAG systems, often called Naive RAG, followed a simple three-step process: receive a query, retrieve the most relevant document chunks, and generate a response. For basic Q&A over static documents, it worked well. However, enterprise environments are not so simple:
Where Naive RAG breaks down:
- It retrieves once and never course-corrects
- Struggles with multi-step or ambiguous queries
- It has no awareness of why it’s retrieving, just what
Then Came Advanced RAG
Advanced RAG patched the gaps; introducing smarter chunking strategies, re-ranking retrieved results, and query rewriting before retrieval. It was more accurate, more reliable, and far better suited for enterprise knowledge bases.

Agentic RAG: Where It Gets Powerful
Agentic RAG is the real leap forward. Here, the AI does not just retrieve; it reasons. It plans multi-step retrieval, decides which data source to query, validates its own answers, and loops back when something does not add up. However, what does this mean for your business?
- AI that handles complex, cross-departmental queries
- Responses grounded in multiple verified sources simultaneously
- Dramatically fewer hallucinations at scale
How LLMs Function as the Reasoning Engine Behind Enterprise AI Systems?
Most enterprise owners think of LLMs as fancy chatbots; you ask a question, you get an answer. In modern AI systems, LLMs are not just responding; they are reasoning.
The global large language models market size was estimated at USD 5,617.4 million in 2024 and is projected to reach USD 35,434.4 million by 2030, growing at a CAGR of 36.9% from 2025 to 2030.
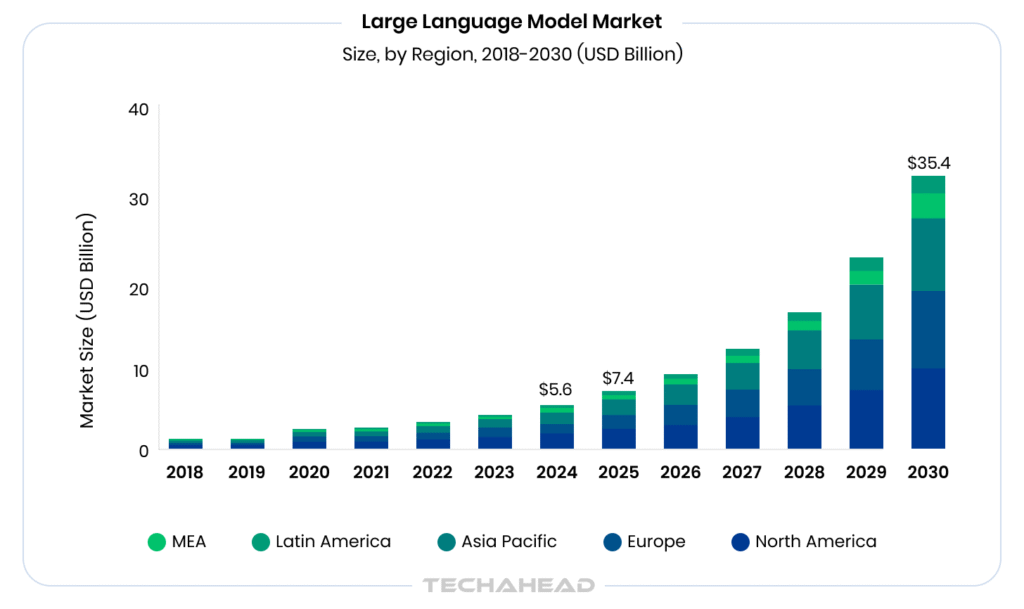
Because, they sit at the core of your AI architecture, acting as the brain that interprets context, breaks down complex tasks, and decides what to do next.
Here is what an LLM is actually doing behind the scenes:
- Reading/ understanding unstructured inputs: emails, contracts, reports, support tickets
- Breaking multi-step business problems into executable sub-tasks
- Deciding which tools, databases, or agents to call upon
- Synthesizing retrieved information into coherent, actionable outputs
- Maintaining context across long, complex workflows without losing the thread
This is what makes LLMs fundamentally different from traditional automation or rule-based systems. A rules engine follows instructions. An LLM understands intent, and that distinction is exactly why enterprises are rebuilding workflows around them in 2026.
LLM Selection for the Enterprise: Balancing Cost, Performance, & Compliance
Not all LLMs are built for enterprise pressure. Choosing an LLM is not a technical decision; it is a business decision. The model powering your AI directly impacts your costs, your compliance posture, and whether your teams actually trust the outputs. Get it wrong; you are either overspending on capability you do not need or under-delivering on accuracy that your operations depend on.
The Three Pillars of Enterprise LLM Selection
1. Performance
- Does it handle your industry’s terminology and complexity?
- Can it reason across long documents, contracts, reports, policies?
- How does it perform on multi-step, cross-departmental queries?
2. Cost
- What’s the cost per token at your expected usage volume?
- Does it require expensive fine-tuning or expensive infrastructure to run?
- Is there a self-hosted option to control long-term spend?
3. Compliance & Data Privacy
- Does the model provider offer data residency guarantees?
- Is your data used to retrain their model?
- Does it meet GDPR, HIPAA, or SOC 2 requirements relevant to your industry?
Closed vs. Open-Source: What Enterprises are Actually Choosing?
Closed models like GPT-4o, Claude offer superior out-of-the-box performance with enterprise support. Open-source models like LLaMA, Mistral offer control, customization, and lower long-term cost.
Here is the smartest enterprise approach: start with a closed model to move fast, and migrate selectively to open-source where compliance or cost demands it.
What are Multi-Agent Systems?
Imagine a team of specialists, each with a defined role, working together to solve a complex problem. That is exactly what a Multi-Agent System is. Instead of one AI handling everything, multiple AI agents collaborate, each owning a specific task: research, analysis, decision-making, execution. They communicate, hand off work, and course-correct in real time, completing end-to-end business workflows that a single AI simply could not manage alone.

How RAG, LLMs & Multi-Agent Systems Work Together in Production?
In production enterprise systems, RAG, LLMs, Multi-Agent Systems do not operate in silos; they form a tightly coupled reasoning or execution pipeline. Understanding how data flows across these layers is crucial for an implementation approach.
Layer 1: The LLM as the Orchestration Core
The LLM sits at the top of the decision hierarchy; functioning as the orchestrator, not just a text generator. When a complex query enters the system, the LLM performs:
- Intent decomposition: Breaking the high-level goal into discrete, executable sub-tasks
- Tool selection: Dynamically deciding which agents, APIs, or retrieval pipelines to invoke
- Context window management: Maintaining state across multi-turn, multi-agent interactions
- Output synthesis: Aggregating results from multiple agents into a structured response
Frameworks like LangGraph and AutoGen expose this orchestration layer explicitly, which allows developers to define agent topologies, message-passing protocols, and fallback logic.
Layer 2: RAG as the Grounded Knowledge Pipeline
Rather than relying on parametric memory baked into model weights, RAG introduces a dynamic retrieval layer between the query and the generation step. In a production setup, it involves:
Vector Store Architecture
Enterprise documents are chunked, embedded using models like BGE-M3, Cohort Embed-v4, Voyage-3, Zembed-1 stored in vector databases such as Pinecone, Weaviate, or pgvector. At query time, semantic similarity search retrieves the top-k most relevant chunks.
Retrieval Pipeline Components
- Query rewriting: rephrasing the user query for higher retrieval precision
- Hybrid search: combining dense vector search with BM25 sparse retrieval for recall optimization
- Re-ranking: passing retrieved chunks through a cross-encoder model like Cohere Rerank to prioritize relevance before passing context to the LLM
- Context stuffing vs. context compression: managing token limits by summarizing or filtering retrieved chunks intelligently
Layer 3: Multi-Agent Execution Mesh
Once the LLM has decomposed the task and RAG has supplied relevant context, specialized agents handle parallel execution. In a production multi-agent architecture:
- Agents are instantiated with defined roles, tools, memory scopes
- They communicate via structured message passing, not free-form text, using schemas that reduce ambiguity
- Each agent independently invoke RAG pipelines, call external APIs, write to databases, or trigger downstream agents
- A supervisor agent monitors task completion, handles failures, and enforces output validation before results are passed upstream
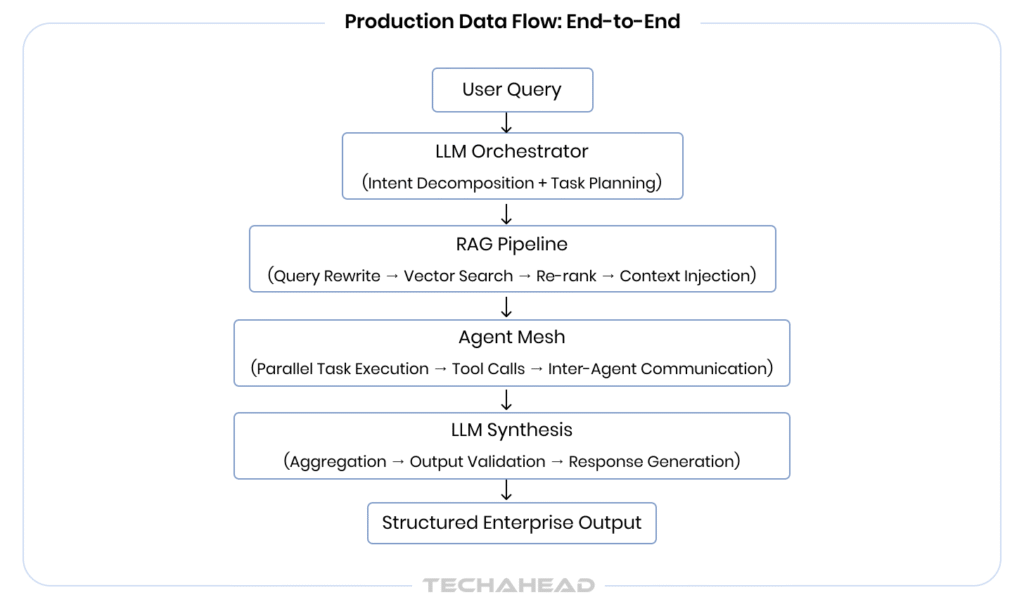
The above architecture offers stateful, fault-tolerant AI workflows; the three non-negotiables for any enterprise deploying AI in production.
How to Build Your Enterprise AI Roadmap Step-by-Step?
The biggest mistake enterprises make is leading with the tool; picking an LLM or an agent framework before understanding the actual business problem. A strong AI roadmap works in the opposite direction.
Step 1: Audit Your High-Value Workflows
Identify processes that are repetitive, knowledge-heavy, currently bottlenecked by human bandwidth such as contract review, customer support, compliance reporting, internal search.
Step 2: Rank by ROI Potential
However, not every use case deserves equal priority. Score each workflow against two axes: business impact and technical feasibility. Now build your sequencing around that matrix.
Step 3: Start with RAG
Ground your AI in your own business data first. Deploy a RAG pipeline over your internal knowledge base. Validate accuracy and build organizational trust before introducing multi-agent complexity.
Step 4: Define Your Governance Framework
Establish data access policies, output validation protocols, and human-in-the-loop checkpoints before going to production, not after.
Step 5: Instrument, Measure & Iterate
Track hallucination rates, task completion accuracy, latency, and cost-per-query. Let production data drive your next architectural decision.
Conclusion
RAG, LLMs, and Multi-Agent Systems are the foundation of how competitive enterprises will operate in the years ahead. The architectural decisions you make today will determine whether your business leads or follows in your industry. The good news? You do not have to figure it out alone.
TechAhead specializes in agentic AI development, RAG implementations, custom LLM solutions, and intelligent automation, purpose-built for your enterprise. From connecting new AI systems with existing ERP, legacy platforms to building custom enterprise platform development, TechAhead operates as an accountable partner, not just a vendor.
Ready to move from strategy to production? Schedule a free consultation with TechAhead’s AI architects; get a tailored roadmap built around your workflows.

How do we ensure our proprietary business data stays secure when using LLMs?
Deploy LLMs within private cloud or on-premise environments, enforce strict data access controls, ensure no data is used for model retraining. TechAhead’s Global Center of Excellence designs enterprise AI systems with security and compliance built into the architecture from day one.
Can RAG & Multi-Agent Systems integrate with our existing ERP, CRM, and legacy infrastructure?
Yes; RAG and Multi-Agent Systems are inherently API-driven, making them compatible with legacy platforms. Your existing infrastructure does not need replacing; it becomes the data foundation your AI reasons over.
What happens when an AI agent makes a wrong decision in a crucial business workflow?
Well-architected agent systems never operate without guardrails; they include confidence thresholds, human-in-the-loop escalation triggers, and complete decision audit trails. When uncertainty is detected, the system pauses and flags for human review rather than proceeding with a potentially costly output.
Do we need a large in-house AI team to build and manage these systems?
Not necessarily; the right implementation partner eliminates that dependency entirely. TechAhead’s Global Center of Excellence acts as your embedded AI team, managing everything from architecture design, deployment to ongoing optimization.