

















 Copy Link
Copy Link Share on X
Share on X Share on Facebook
Share on Facebook Share on LinkedIn
Share on LinkedIn


Always Active
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Build intelligent AI systems that automate decisions, accelerate innovation, and scale business growth.
Design, build, modernize, and scale digital products that drive business growth.
Build secure, scalable, and intelligent platforms that power modern enterprises.
Build intelligent, connected, and autonomous systems that operate in the real world.
Flexible engineering capacity with predictable delivery, ownership, and outcomes.
Uncover the transformative potential of digital and mobile solutions for your industry

 Last Updated: Jun 9, 2026
Apr 22, 2026
Last Updated: Jun 9, 2026
Apr 22, 2026  1021
1021  21 min. Read
21 min. Read



Key Takeaways
Enterprises are investing in custom LLM applications to automate complex workflows, enable natural language interfaces across systems, power intelligent search and retrieval, generate and transform content, and support decision-making at scale. The cost to build a custom LLM application typically ranges from $75,000 to $750,000+, depending on the approach like API-based integration, fine-tuning an existing model, or building a fully custom model. For most enterprise use cases, production-grade applications fall in the $150,000 to $750,000 range, with costs largely driven by data preparation, engineering effort, and compliance requirements.
Engineering leaders who have lived through a large-scale LLM project know one thing: the number your CFO expects at kickoff bears little resemblance to the invoice you present at go-live. Data pipelines balloon. Annotation takes longer than predicted. MLOps scaffolding that looked optional in the design doc becomes mandatory in production. And compliance, like HIPAA, SOC 2, ISO 42001, adds six figures before a single user logs in.
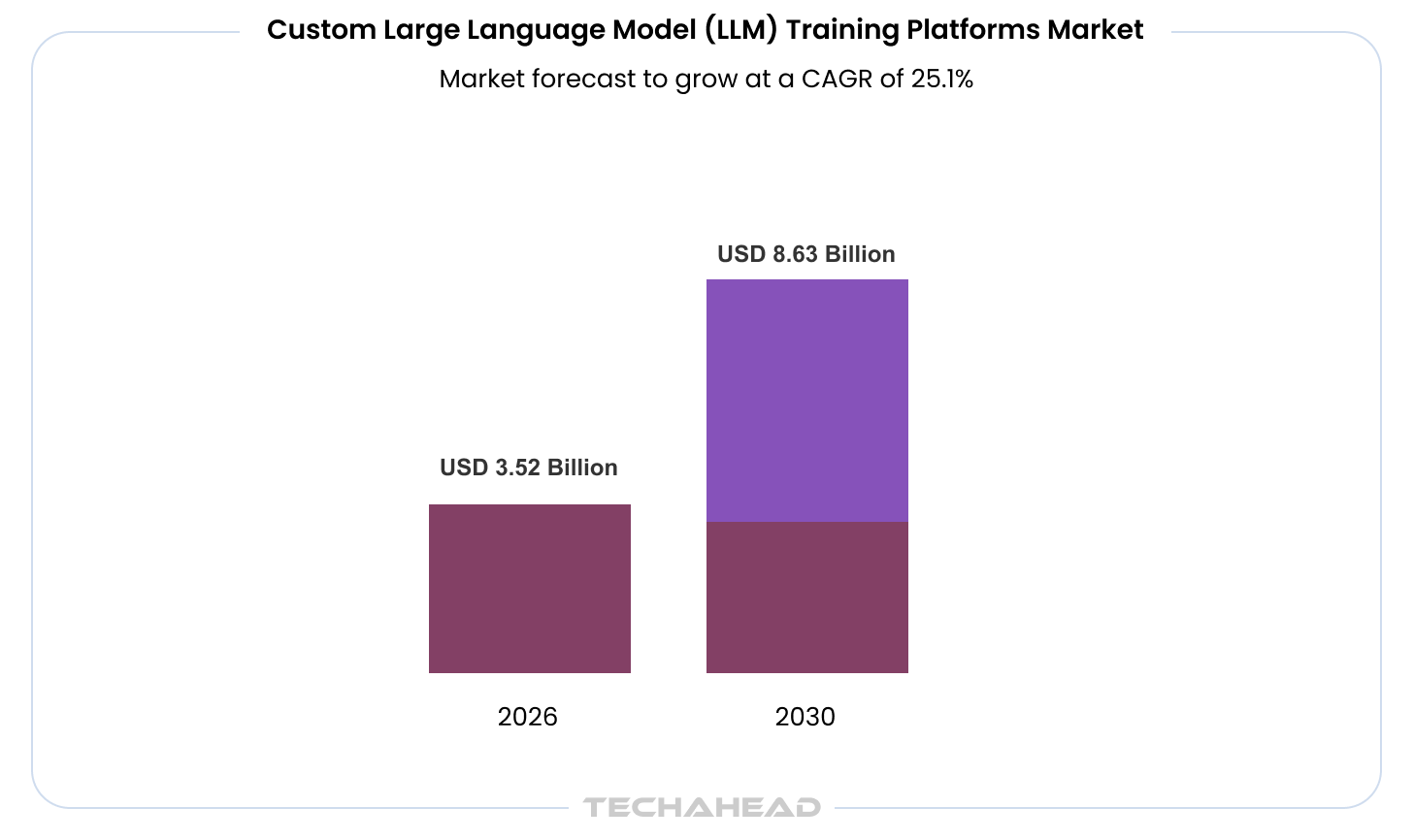
At the same time, the stakes are only getting higher. Generative AI is not a marginal improvement layer—it is a multi-trillion-dollar shift. Recent estimates suggest it could add $2.6 trillion to $4.4 trillion annually across enterprise use cases, a figure comparable to the entire GDP of the United Kingdom. The infrastructure enabling this shift is expanding just as rapidly. The custom LLM training platform market alone is projected to grow from $2.82 billion in 2025 to $3.52 billion in 2026, reflecting a 24.9% annual growth rate, driven by demand for domain-specific models, scalable fine-tuning, and secure enterprise deployments.
This is exactly where most cost assumptions start to break.
This guide gives you the numbers without the vagueness. Whether you are evaluating a $75K fine-tuning engagement or a $3M+ ground-up pretraining initiative, the cost model below will help you build a defensible budget and survive the CFO conversation.
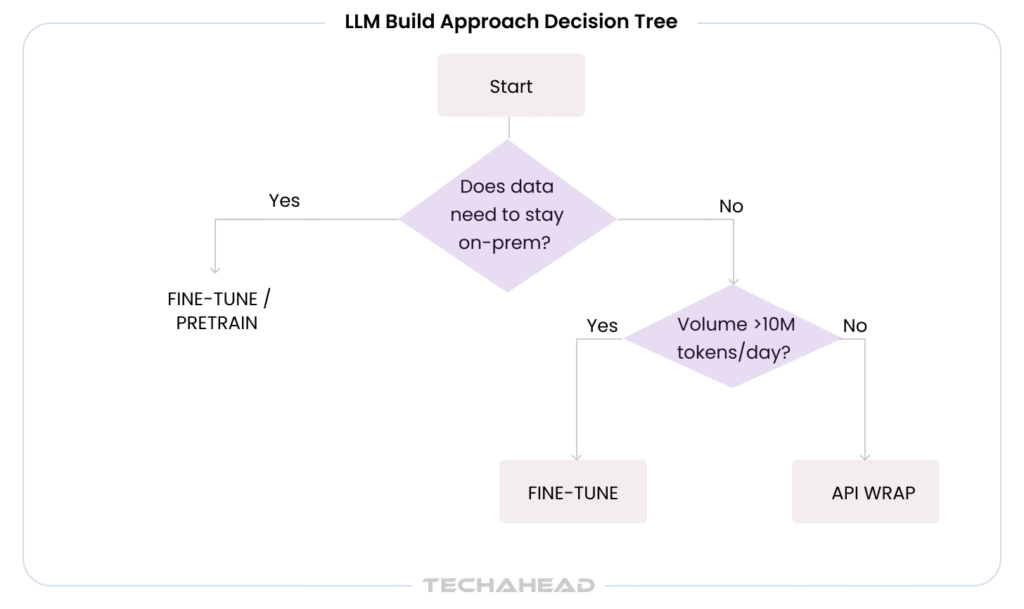
There is no single answer to “how much does a custom LLM cost?” because there is no single type of custom LLM project. The approach you choose determines roughly 80% of your total cost structure before you hire the first engineer.
You call GPT, Claude, or Gemini via API, engineer your prompts, and add retrieval-augmented generation (RAG) on top. The model itself is someone else’s problem. You own the orchestration layer like system prompts, context injection, output parsing, guardrails.
When it makes sense: Internal productivity tools, low-volume customer-facing bots, proof-of-concept builds, scenarios where PII never enters the prompt.
Cost driver: Engineering time is almost entirely software development (API integration, RAG pipeline, evaluation harnesses). Token costs at scale are the main operational risk as GPT runs roughly $5 per million input tokens, and a 10-million-token/day deployment costs $1,500/day before you add output.
TechAhead delivered an AI-powered fitness coaching app that uses GPT-based APIs to generate personalized workout plans and natural-language coaching feedback. During scoping, the team identified that scaling the product with an API-only approach could create cost pressure/ Therefore, they introduced a hybrid architecture that reserved API calls for conversational coaching while shifting structured workout generation to a more efficient model layer. This approach helped balance performance, cost, and user experience.
You start from a pretrained checkpoint, like Llama 3.1, Mistral 7B, Falcon 40B, and adapt it on your domain data using supervised fine-tuning (SFT) or parameter-efficient methods like LoRA/QLoRA. You own the weights, you deploy on your own AI infrastructure, and the model understands your vocabulary, tone, and task structure.
When it makes sense: Domain-specific document understanding, regulated industries requiring on-premise deployment, moderate-volume inference where API token costs are prohibitive, and use cases where proprietary data cannot leave your environment.
Cost driver: Data preparation is typically 30–50% of total project cost. Compute is modest relative to pretraining — a Llama 3.1 70B fine-tune with LoRA on 4× H100s takes approximately 15 hours at roughly $180 in raw GPU cost. Engineering and evaluation hours dominate the budget.
You train a model on your proprietary corpus from random initialization. You control the architecture, tokenizer, pretraining objective, and data distribution. This is the path for organizations that need a model that reflects institutional knowledge at a level no fine-tune can match, or that require the IP ownership of every weight.
When it makes sense: Large regulated enterprises with massive proprietary corpora (legal, medical, financial), companies building an LLM product they intend to commercialize, or defense and intelligence contexts where no third-party weights are acceptable.
Cost driver: Compute is the floor, not the ceiling. Engineering, data acquisition, and annotation costs can exceed compute by a factor of two or three. A 7B-parameter model trained from scratch on cloud GPUs starts at $50K–$500K. A 70B model starts at $1.2M–$6M. These are compute-only figures.
The table below reflects realistic 2025 project economics for a U.S. enterprise engagement with proper evaluation, MLOps integration, and security review. Offshore or hybrid resourcing reduces engineering costs 30–50%; the compute figures do not change.
| Approach | Engineering Effort | Compute Cost | Data Cost | Timeline | Total Range |
| Prompt engineering / API wrapping | 400–800 hrs | $0–$5K (API fees) | $5K–$20K (curation, eval sets) | 4–10 weeks | $75K–$150K |
| Fine-tuning open-source (7B–13B) | 800–1,600 hrs | $1K–$15K | $30K–$100K | 8–16 weeks | $150K–$400K |
| Fine-tuning open-source (70B) | 1,200–2,400 hrs | $15K–$80K | $80K–$250K | 12–24 weeks | $300K–$750K |
| Full pretraining (7B) | 2,000–4,000 hrs | $50K–$500K | $100K–$500K | 16–32 weeks | $400K–$1.5M |
| Full pretraining (70B+) | 4,000–10,000 hrs | $1.2M–$6M | $500K–$2M+ | 6–18 months | $2M–$10M+ |
Engineering rates assumed at $150–$250/hr for a U.S.-based team. Data costs include acquisition, cleaning, annotation, and evaluation set construction. Compliance adders not included — see the compliance section below.
The most expensive mistake engineering leaders make is scoping a fine-tuning project based on GPU cost calculators alone. A 7B fine-tune may cost $300 in GPU time and $120,000 in data & engineering labor. Compute is not the constraint. Talent and data are.
GPU cost is frequently cited as the headline number, but it is rarely the largest line item in a fine-tuning project. It is the largest line item in pretraining. The table below uses 2025 cloud spot/on-demand pricing for A100 80GB (~$3–$5/hr) and H100 80GB (~$7–$12/hr).
| Model Size | Approach | GPU Hours (est.) | A100 Cost | H100 Cost | Typical Training Time |
| 7B (fine-tune, LoRA) | Fine-tuning | 15–60 hrs | $45–$300 | $105–$720 | Hours–2 days |
| 13B (fine-tune, LoRA) | Fine-tuning | 40–120 hrs | $120–$600 | $280–$1,440 | 1–3 days |
| 70B (fine-tune, LoRA) | Fine-tuning | 80–400 hrs | $240–$2,000 | $560–$4,800 | 1–7 days |
| 7B (pretrain from scratch) | Pretraining | 20,000–100,000 hrs | $60K–$500K | $140K–$1.2M | 2–4 weeks |
| 13B (pretrain from scratch) | Pretraining | 50,000–250,000 hrs | $150K–$1.25M | $350K–$3M | 1–3 months |
| 70B (pretrain from scratch) | Pretraining | 250,000–1M hrs | $750K–$5M | $1.75M–$12M | 3–8 months |
| 175B+ (pretrain from scratch) | Pretraining | 2.5M–10M hrs | $7.5M–$50M | $17.5M–$120M | 6–18 months |
H100 is 3× more cost-efficient per training dollar for LLM workloads despite higher hourly rates. For fine-tuning, A100s offer better dollar-per-result economics. For 70B+ pretraining, H100/H200 clusters are the correct choice. Spot pricing can reduce costs by 40–60% for fault-tolerant training jobs.
The point most boards miss: a 7B fine-tune may cost $300 in GPU time and $120,000 in data and engineering labor. Compute is not the constraint. Talent and data are.
Do you have a customized AI project idea and want to know the total budget for making it live? Read our enterprise AI app development cost that dive deep into all the parameters that influence your budget.
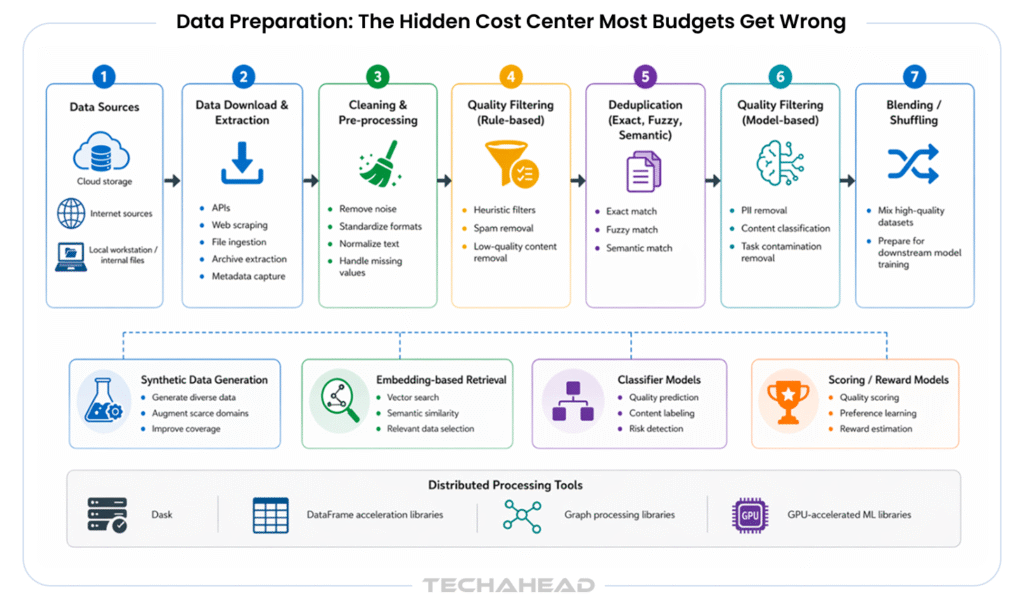
In our experience scoping LLM projects at enterprise scale, data preparation is the single most underestimated cost category. Clients who budget $50,000 for data routinely spend $150,000–$250,000 once the full scope becomes clear.
Here is why the number grows:
1. Raw data is rarely training-ready. Internal documents contain formatting artifacts, inconsistent schema, PII that must be scrubbed, and domain noise that degrades model performance. Expect 40–80 hours of data engineering per 10GB of raw text.
2. Annotation is expensive at quality. High-quality instruction-tuning datasets require subject matter expert annotators. Healthcare annotation from credentialed reviewers runs $80–$150 per sample.
Legal review runs $100–$200 per sample. A 5,000-sample SFT dataset in a regulated domain costs $400K–$1M in annotation alone before you write a line of training code.
3. RLHF multiplies the cost. Reinforcement learning from human feedback requires comparison pairs, preference annotations, and multiple annotation rounds. Producing 600 high-quality RLHF annotations costs approximately $60,000 — roughly $100 per annotation. For a production-quality alignment pass on a 70B model, budget $500K–$2M for data alone.
4. Evaluation datasets are not free. A robust evaluation harness requires curated held-out sets, adversarial examples, and domain benchmarks. Most teams spend 15–20% of total data budget on evaluation — and skip it when budgets compress, creating post-deployment failures.
TechAhead’s sports club management engagement centered on unifying fragmented member data and improving personalization workflows for a mid-market sports organization. During scoping, the team identified that the client’s source data required significantly more preparation than initially assumed, including schema normalization, PII handling, and deduplication before model fine-tuning could begin. The final architecture was adjusted to account for these data quality realities and to support reliable personalization and scheduling recommendations at scale.
Rule of thumb: Data preparation will consume 30–50% of your total project budget. If your current estimate has it below 25%, rebuild the budget.

Delivery is not deployment. Once your model is in production, costs continue:
Self-hosted inference for a 7B–13B model on a single A100 costs $1,500–$5,000/month running 24/7. A 70B model requiring 4–8 GPUs runs $15,000–$40,000/month. Enterprise-scale deployments (70B+ with high concurrency) typically run $50,000–$150,000/month.
Organizations often start on cloud (AWS, GCP, Azure H100s at $4–$12/hr) and migrate to bare-metal once traffic patterns stabilize — reducing inference costs by 40–60%.
Models degrade. Domain language evolves. Regulatory language changes. Plan for quarterly evaluation cycles and semi-annual retraining passes:
Annual model maintenance typically runs 15–25% of original build cost. A $400K fine-tuning project carries $60K–$100K/year in ongoing model operations costs.
TechAhead delivered an AI-driven news personalization platform designed to surface highly relevant content recommendations for a media company’s readers. The solution combined LLM-based content curation, machine learning, and NLP to improve feed relevance and positive content discovery. As with any recommendation system, ongoing monitoring and periodic model refreshes are important to sustain performance as content distributions evolve.
Defaulting to an API wrapper is not always wrong. It is often the correct first step. But there are five scenarios where the economics and requirements tip decisively toward a custom model:
Our team at TechAhead offers full custom LLM development services covering all three build tiers — from API-wrapped RAG systems to ground-up pretraining for enterprise clients with strict data residency requirements.
TechAhead delivered an AI-driven employee referral platform that helps organizations streamline referral workflows with personalized recommendations and automated hiring support. As the platform evolved, the team considered the tradeoffs between API-based LLM calls and more efficient model architectures to balance scale, cost, and task-specific performance. The final solution emphasized reliability and efficiency for large-volume referral matching and employee engagement workflows.
Compliance is not a line item that appears in most LLM cost calculators. It should be. For regulated industries, compliance can add $100K–$500K to total project cost — and is non-negotiable.
SOC 2 Type II: If your LLM processes customer data in a SaaS context, your buyers’ security teams will require it. Preparing for and maintaining SOC 2 Type II costs $30,000–$80,000 in the initial year (readiness assessment, auditor fees, tooling) and $10,000–$40,000 annually thereafter. TechAhead’s infrastructure is SOC 2 Type II certified, which means clients building on our platform inherit a significant portion of the compliance posture.
HIPAA: Healthcare AI deployments require Business Associate Agreements, access controls, audit logging, encryption at rest and in transit, and breach notification procedures. Adding HIPAA compliance to an LLM deployment adds $50,000–$200,000 in engineering and legal cost, plus ongoing compliance monitoring. De-identification of training data (a prerequisite for using patient records) can add $100K–$400K in specialist annotation cost alone.
ISO 42001 (AI Management Systems): The newest standard on the list, ISO 42001 addresses AI governance, risk management, and transparency for AI systems. Achieving certification requires documenting model governance frameworks, bias assessments, data lineage, and incident response procedures. Expect $75,000–$150,000 for initial certification and $25,000–$50,000/year to maintain. TechAhead holds ISO 42001 certification — one of the few LLM development partners that can deliver this as a shared control for client deployments.
GDPR/CCPA: If your training data includes EU or California resident data, legal review of data use rights, model memorization audits, and right-to-erasure workflows add $30,000–$80,000 to project scope.
Aggregate Compliance Cost for Regulated Deployments
Healthcare or financial services LLM deployment: $200,000–$600,000 added to baseline build cost. Project compliance costs in before the kickoff — not after legal review.
The talent market for LLM engineers is the most competitive it has ever been. Average AI engineer salaries reached $206,000 in 2025 — a $50,000 increase over the prior year. LLM fine-tuning specialists command a 25–40% premium above that baseline. Here is what a production-grade LLM team looks like:
| Role | Function | Hourly Rate (U.S.) | Annual Salary Equivalent |
| LLM Architect | System design, model selection, training strategy | $200–$300/hr | $280K–$400K |
| Senior ML Engineers (2–3) | Training pipelines, evaluation, fine-tuning | $175–$250/hr | $240K–$320K each |
| Data Engineers (1–2) | Pipeline construction, data cleaning, deduplication | $150–$200/hr | $180K–$250K each |
| MLOps Engineer | Serving infrastructure, monitoring, CI/CD | $160–$220/hr | $200K–$280K |
| Prompt Engineers (1–2) | System prompt design, evaluation, red-teaming | $120–$180/hr | $150K–$220K each |
| Domain Annotators | Data labeling, quality review (project-based) | $80–$150/hr | Variable |
A typical fine-tuning engagement requires 4–6 full-time equivalent engineers for 3–5 months. At blended U.S. rates, that is $500,000–$900,000 in talent cost alone before compute and data. This is why most enterprise clients hire LLM developers through a specialist partner rather than build and maintain an in-house team — the talent acquisition cost, equity premiums, and bench utilization math rarely work for a single project.
Offshore and hybrid team models reduce blended rates to $60–$120/hr. TechAhead’s 240-person team operates across U.S. and offshore engineering centers, allowing clients to access senior LLM architect oversight without full U.S. burdened headcount costs for the entire delivery team.

A CFO evaluating a $500,000 LLM fine-tuning investment needs a different frame than an engineer evaluating model quality. Here is how to structure the ROI case:
Cost reduction argument. If the model replaces or augments a workflow currently handled by humans or expensive API calls, quantify it. A 70B legal contract review model that reduces outside counsel review time by 30% on a $2M/year legal spend returns $600,000/year. The $500K build cost pays back in 10 months.
Risk reduction argument. For compliance-sensitive workflows, a custom model with controlled outputs and full audit trails reduces regulatory risk. A single regulatory action in financial services or healthcare can cost $5M–$50M. A $300K model investment that reduces that risk by even 5% carries a substantial expected value.
Competitive differentiation argument. If the model encodes institutional knowledge that competitors cannot replicate through API calls — proprietary data, internal processes, historical decision patterns — the model becomes a durable competitive asset, not an expense.
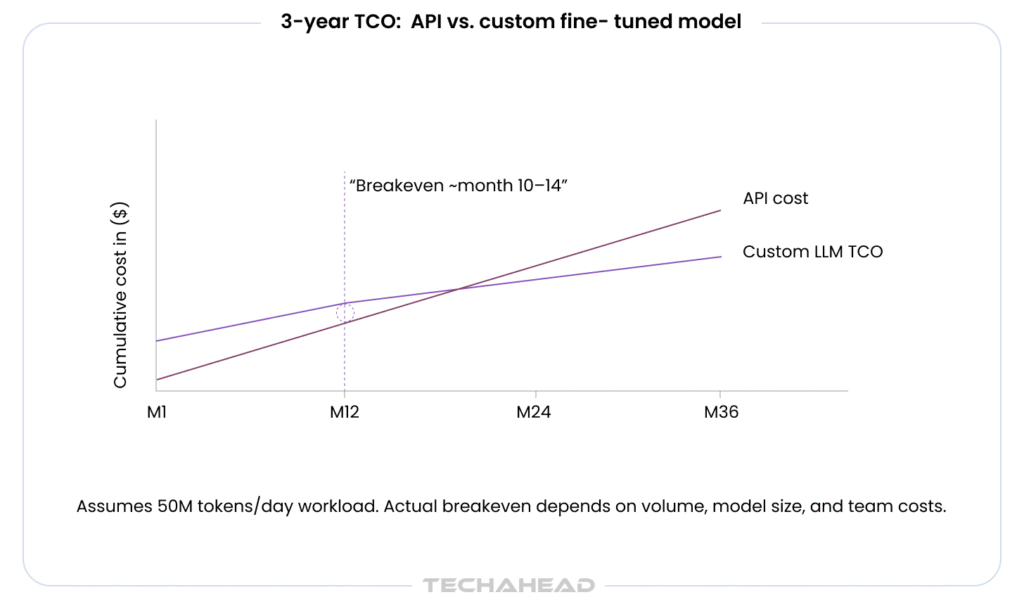
Build the 3-year TCO. Year one is always worst. By year three, the fine-tuned model has been retrained twice, the inference infrastructure is optimized, and the team has moved to a maintenance-only cadence. The 3-year all-in cost for a well-scoped fine-tuning project typically runs 30–40% of the equivalent API spend for the same workload volume.
To understand how LLM development integrates with broader enterprise AI strategy, explore TechAhead’s generative AI and agentic AI services — from RAG architectures to autonomous agent workflows built on top of custom model layers.
The ranges in this guide span orders of magnitude because LLM projects legitimately span orders of magnitude in scope, compliance requirements, and data readiness. The most expensive mistake engineering leaders make is scoping a fine-tuning project based on GPU cost calculators and ignoring data, talent, and compliance.
The second most expensive mistake is over-building. Most enterprise use cases do not need a 70B pretrained model. A well-scoped fine-tuned 13B model with a rigorous evaluation harness outperforms an over-parameterized model with poor data quality every time.
TechAhead has delivered LLM projects for clients including Disney, American Express, AXA, and ESPN — across regulated industries and at enterprise scale. Our engagements start with a scoping exercise that produces a defensible cost model before a dollar is committed to development.
If you are in the early stages of evaluating a custom LLM build, explore our custom LLM development services or request a scoping call with our LLM architecture team. We will tell you whether a $100K fine-tune solves your problem before you budget for a $2M pretraining project.

Custom LLM development costs range from $75,000 for a basic prompt-engineered API integration to $10M+ for a full 70B+ pretraining project. The most common enterprise engagement — fine-tuning a 7B–70B open-source model — runs $150,000–$750,000 all-in, including data preparation, engineering, evaluation, and initial deployment. The single biggest variable is data preparation, which alone accounts for 30–50% of total project cost in most engagements.
Fine-tuning is almost always significantly cheaper. A Llama 3.1 70B fine-tune with LoRA on 4× H100s costs approximately $180 in raw GPU time and $150,000–$400,000 in total project cost. Building a comparable 70B model from scratch starts at $1.75M–$12M in compute alone, before data and engineering. The only scenarios where pretraining makes economic sense are: you need full IP ownership of the weights, your proprietary corpus is so large and unique that no fine-tune can adequately adapt a base model, or you are building an LLM product for commercial sale.
For fine-tuning, GPU costs are relatively modest: a 7B model fine-tune costs $45–$720 depending on whether you use A100s or H100s, and runs in hours to 2 days. A 70B fine-tune costs $240–$4,800 and takes 1–7 days. For pretraining, GPU cost is the dominant budget item: a 7B model from scratch costs $60K–$1.2M in GPU compute; a 70B model costs $750K–$12M. H100s are approximately 3× more cost-efficient per training dollar than A100s for large pretraining runs.
Data preparation is consistently the most underestimated cost. Clients who budget $50,000 for data routinely spend $150,000–$250,000 once the full scope is known — PII scrubbing, schema normalization, expert annotation, and evaluation set construction all add up. In regulated industries, annotation alone for a 5,000-sample fine-tuning dataset can cost $400K–$1M. After data, compliance is the second most overlooked cost: HIPAA, SOC 2, and ISO 42001 together can add $200,000–$600,000 to a healthcare or financial services LLM deployment.
Timeline depends directly on the build approach: a prompt-engineered API integration takes 4–10 weeks; a 7B–13B fine-tune takes 8–16 weeks; a 70B fine-tune takes 12–24 weeks; full pretraining of a 7B model takes 16–32 weeks; and a 70B+ pretraining project takes 6–18 months. These timelines assume adequate data readiness. In our experience, data preparation alone adds 4–8 weeks to the typical enterprise fine-tuning project that did not budget sufficient time for data audit and cleaning.
If your data is not sensitive, your volume is below ~10M tokens/day, and your use case does not require domain-specific accuracy, a third-party API is the right starting point. Custom development becomes economically compelling when: (1) data cannot leave your environment due to compliance requirements, (2) you need latency under 500ms for user-facing applications, (3) volume exceeds the API breakeven threshold — typically 50M–100M tokens/day, or (4) your domain requires accuracy that general-purpose models consistently fail to deliver. Run a 3-year TCO comparison, not a year-one cost comparison.
Plan for 15–25% of your original build cost annually. A $400K fine-tuning project carries $60K–$100K/year in ongoing model operations. This includes: model drift monitoring ($20K–$50K/year), quarterly evaluation cycles ($10K–$30K per cycle), semi-annual retraining passes (20–30% of original training cost), and ongoing prompt and system-level engineering (2–4 hours/week). Self-hosted 70B models also carry $15,000–$40,000/month in inference infrastructure costs before maintenance.
We use cookies to ensure our website functions properly, improve performance, and provide a personalized experience. You can choose which types of cookies to allow below.
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Help us understand site traffic and user interactions so we can improve performance and usability.
Enable enhanced functionality and personalization such as language or region preferences.
Used to deliver relevant ads, track campaign performance, and measure advertising effectiveness.