







Staff Augmentation
Access top-tier talent on demand: Dedicated, Hourly, or Flexible.






























 Copy Link
Copy Link Share on X
Share on X Share on Facebook
Share on Facebook Share on LinkedIn
Share on LinkedIn
“In the future, intelligence will be everywhere—on the edge, not just in the cloud.” – Jensen Huang, CEO of NVIDIA
As an enterprise leader, you are likely facing mounting pressure to deploy AI solutions that are both secure & cost-effective. The question is not whether to implement AI inference, it’s where (for example: giant models/LLMs or Small Language Models/SLMs). Should you leverage the cloud’s flexibility, deploy models at the edge for real-time processing, or keep everything on-premises for maximum control?
The wrong choice can be expensive! We have seen companies overspend by 300% on cloud inference when on-premises would have been cheaper, and others compromise data security without considering compliance implications. Your inference deployment strategy directly impacts your bottom line. In this guide, we break down the real costs, security measures and practical decision criteria for cloud, edge, and on-premises AI inference. Whether you are managing sensitive financial data or scaling to millions of daily predictions, you will find the framework you need to make an informed decision. Let’s dive in.
Key Takeaways
- AI inference delivers real business value by operationalizing trained models at scale.
- Inference strategy directly impacts latency, security, compliance, and long-term ROI.
- Network latency makes cloud inference unsuitable for ultra-real-time applications.
- Data gravity often makes on-prem inference cheaper than cloud for enterprise datasets.
- Cloud reduces operational burden, while on-prem requires deep infrastructure expertise.
What is AI Inference?
AI inference is the process where a trained machine learning model applies its learned patterns to new, unseen data to generate predictions, or decisions in real time.
According to Grand View Research, the global AI inference market size was estimated at USD 97.24 billion in 2024 and is projected to reach USD 253.75 billion by 2030, growing at a CAGR of 17.5% from 2025 to 2030.
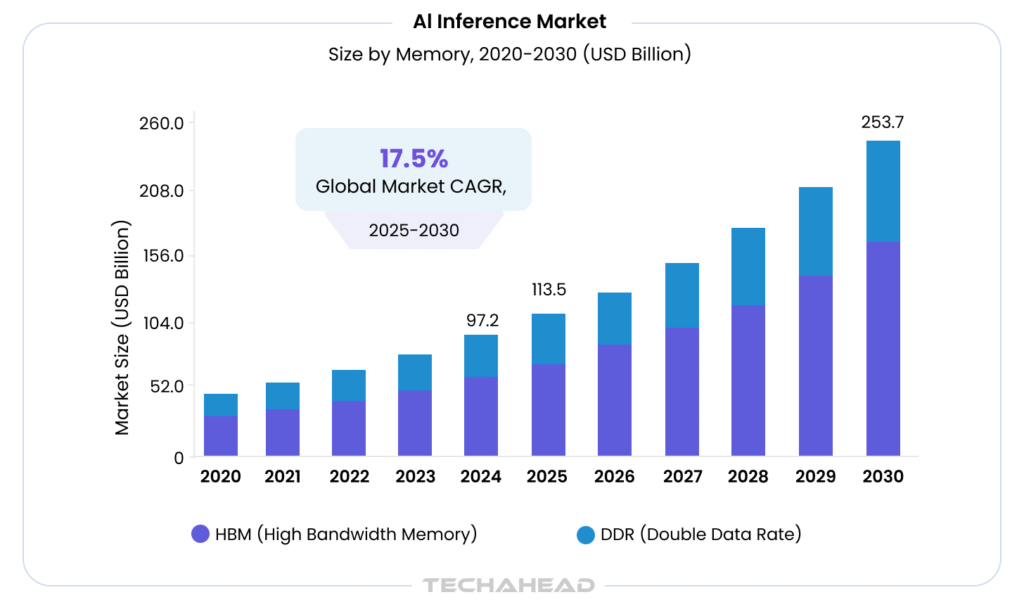
Unlike the resource-intensive training phase, inference focuses on deployment and operational efficiency, which powers enterprise applications like fraud detection, recommendation systems, and autonomous operations. For business leaders, it is the stage that delivers ROI by using scalable AI in production environments.
Key Features of AI Inference
- Real-Time Processing: Delivers instant predictions on live data, essential for time-sensitive enterprise decisions like fraud alerts or autonomous vehicles.
- Low Latency: Optimized for minimal delays, supporting edge use cases where milliseconds matter, such as manufacturing quality control.
- Scalability: Handles varying workloads efficiently, from single queries to millions, ideal for growing enterprise demands.
- Cost Efficiency: Requires far less compute than training, which reduces operational expenses while maintaining high accuracy.
- Model Agnostic: Works across diverse AI models (e.g., LLMs, vision systems) for hybrid enterprise architectures.

What is Cloud Inference?
Cloud inference refers to deploying machine learning models on remote servers managed by cloud service providers (AWS, Google Cloud, Azure, etc.) where predictions are generated by sending data over the internet to these centralized computing resources. The model runs on scalable infrastructure in data centers, with results returned to the requesting application. This approach uses the cloud provider’s computational power and managed services without requiring local hardware investments.
Pros of Cloud Inference
- Massive scalability on demand, easily handle traffic spikes from hundreds to millions of requests without infrastructure planning
- Access to latest hardware (GPUs, TPUs, specialized AI accelerators) without capital expenditure
- Minimal operational overhead with managed services handling updates, security patches, and maintenance
- Pay-as-you-go pricing models align costs with actual usage rather than fixed infrastructure costs
- Global distribution capabilities through multiple data center regions for reduced latency worldwide
- Simplified deployment and iteration, update models centrally without touching edge devices or local infrastructure
Cons of Cloud Inference
- Ongoing operational costs can accumulate significantly at high volumes, potentially exceeding on-premise alternatives
- Latency introduced by network round-trips (usually 50-500ms depending on geography and network conditions)
- Dependency on reliable internet connectivity, service disruptions directly impact inference availability
- Data privacy and regulatory concerns when transmitting sensitive information to third-party servers
- Potential vendor lock-in with proprietary services and APIs that complicate migration
- Network bandwidth costs for transferring large volumes of input data or model outputs
When to Use Cloud Inference?
Cloud inference is the best choice when you are building applications with variable or unpredictable workloads where elastic scaling is essential. It is particularly well-suited for web applications, mobile backends, and batch processing jobs where latency requirements are measured in hundreds of milliseconds rather than single-digit milliseconds. Companies in early-stage development or MVP phases benefit from cloud inference.
This approach excels when your application requires access to large expensive models (like large language models or complex computer vision systems) that would be prohibitively expensive to run on local hardware. Cloud inference also makes sense:
- when your team lacks deep DevOps expertise for managing inference infrastructure
- when you need to serve users across multiple geographic regions
- when regulatory requirements do not prohibit cloud data processing.
Besides that, in 2026, a sub-category is the Sovereign AI Cloud; infrastructure built to ensure data, models, and operations remain entirely within a specific national or legal jurisdiction. Unlike standard public clouds, these are “sovereign-by-design,” protecting against foreign data access laws (like the US CLOUD Act) and geopolitical resilience.
Consider cloud inference for applications like customer service chatbots, document analysis systems, recommendation engines for e-commerce, fraud detection for financial transactions, and any scenario where the business value of predictions justifies network latency.
What is Edge Inference?
Edge inference refers to running machine learning models directly on local devices, such as smartphones, IoT sensors, embedded systems, or edge servers rather than sending data to remote cloud servers. The computational processing happens at or near the data source without constant internet connectivity. This approach keeps data local, reduces latency, and allows AI applications to function independently of centralized infrastructure.
Pros of Edge Inference
- Ultra-low latency – Eliminates network round-trip time for real-time responses like autonomous vehicles, robotics, and augmented reality.
- Privacy and data security – Sensitive data remains on the device, which reduces exposure to breaches during transmission and addressing regulatory compliance requirements like GDPR or HIPAA.
- Reduced bandwidth costs – Minimizes data transmission to the cloud, particularly valuable when processing continuous streams from cameras, sensors, or audio devices.
- Offline functionality – Models continue operating without internet connectivity, essential for remote locations, industrial environments.
- Scalability through distribution – Each device handles its own inference, avoiding centralized issues as the user base grows.
Cons of Edge Inference
- Hardware limitations – Edge devices often have constrained CPU, GPU, memory, and power resources that require model optimization techniques like quantization.
- Model update complexity – Deploying updates across thousands or millions of distributed devices is challenging compared to updating a single cloud endpoint.
- Higher initial device costs – Requires more capable hardware on each device that increases per-unit manufacturing costs.
- Maintenance challenges – Debugging, monitoring, managing models across distributed edge infrastructure is more complex than centralized systems.
- Inconsistent performance – Inference speed and quality vary based on device capabilities that leads to inconsistent user experiences.
When to Use Edge Inference?
Edge inference is the optimal choice when your application requires real-time responsiveness with minimal latency (under 100ms), such as facial recognition for door locks, autonomous vehicle perception systems, or industrial quality control.
It is essential for scenarios demanding offline operation, medical devices in remote clinics, agricultural sensors in rural areas, or military applications in disconnected environments.
Choose edge inference when privacy is paramount and data cannot leave the device due to regulatory requirements, such as health monitoring wearables, smart home cameras, or financial data processing.
It is also cost-effective for high-volume, continuous inference where cloud API costs would become prohibitive, like processing video streams from thousands of security cameras or analyzing sensor data from manufacturing equipment.
Finally, edge inference makes sense when you need consistent performance regardless of network conditions, for applications like voice assistants, AR/VR experiences, or robotics where network interruptions cannot disrupt functionality.
What is On-Premises Inference?
On-premises inference refers to running AI models on infrastructure that you own and control within your organization’s physical facilities or dedicated data centers. This approach gives you complete control over the deployment environment, network access, and data residency, making it the go-to choice for organizations with strict compliance requirements or significant existing infrastructure investments.
However, the #1 reason for On-Prem is Data Gravity. If your enterprise data (ERPs, customer databases) is already on-prem, moving it to the cloud for inference creates massive egress fees and latency. It is often cheaper to bring the model to the data than the data to the model.
Pros of On-Premises Inference
- Complete data control: Sensitive data never leaves your infrastructure, ensuring maximum privacy and compliance with data residency regulations
- Predictable costs at scale: After initial capital investment, per-inference costs are lower for high-volume workloads compared to cloud pricing
- No network dependency: Inference continues even during internet outages, with guaranteed low-latency access from internal systems
- Customization freedom: Full control over hardware selection, model optimization, and infrastructure configuration to meet specific performance requirements
- Security and compliance: Easier to meet stringent regulatory requirements (HIPAA, GDPR, financial regulations) without third-party data processing agreements
Cons of On-Premises Inference
- High upfront capital expenditure: Significant investment in GPU/TPU hardware, servers, networking equipment, and cooling infrastructure before running a single inference
- Ongoing operational burden: Requires dedicated DevOps, MLOps, and infrastructure teams to maintain, update, and troubleshoot the system
- Slower scaling: Procurement cycles for new hardware can take weeks or months. However, in 2026, the rise of AI-in-a-Box solutions (like NVIDIA DGX B200 or specialized “SuperClusters”) and Colocation as-a-Service has shifted the timeline.
- Hardware obsolescence risk: GPU technology evolves rapidly; purchased hardware may become outdated, requiring costly refresh cycles
- Limited flexibility: Difficult to experiment with different model sizes or architectures, but tools like NVIDIA NIM (NVIDIA Inference Microservices) and Kubernetes-native AI fabrics allow on-premise teams to swap out models as easily as in the cloud.
When to Use On-Premises Inference?
On-premises inference makes the most sense when:
- You are operating in highly regulated industries (healthcare, finance, government) where data cannot leave controlled environments
- You have consistent, high-volume inference workloads that justify the capital investment and make per-unit costs competitive
- Data residency requirements mandate that data processing occurs in specific geographic locations or facilities
- You already have existing infrastructure and expertise in data center operations that can be leveraged
- Network latency to cloud services would create unacceptable delays for real-time applications
- You’re running proprietary models that cannot be shared with third-party cloud providers under any circumstances
- Your organization has compliance or security policies that prohibit cloud services entirely
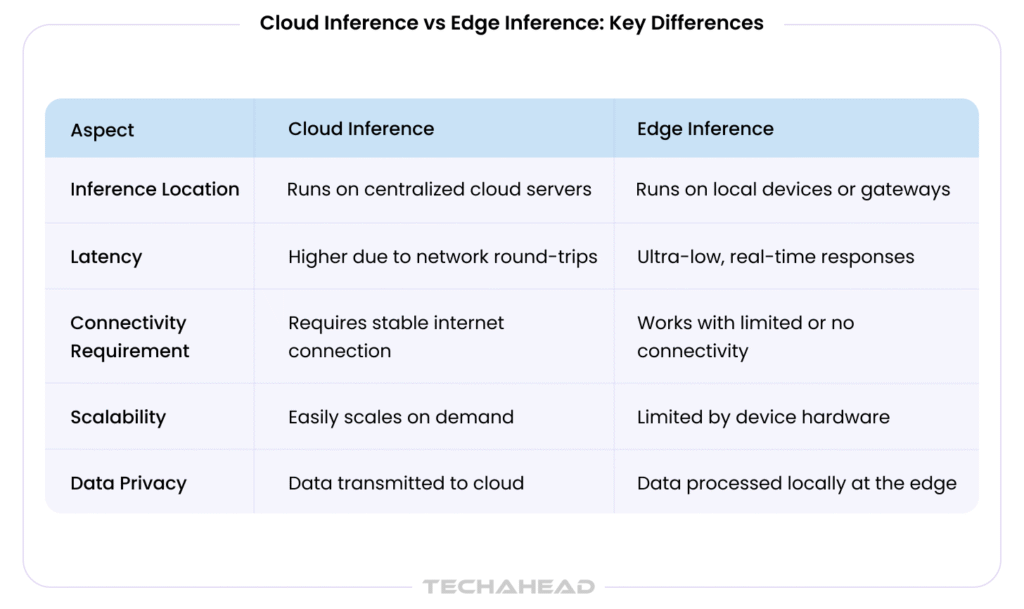
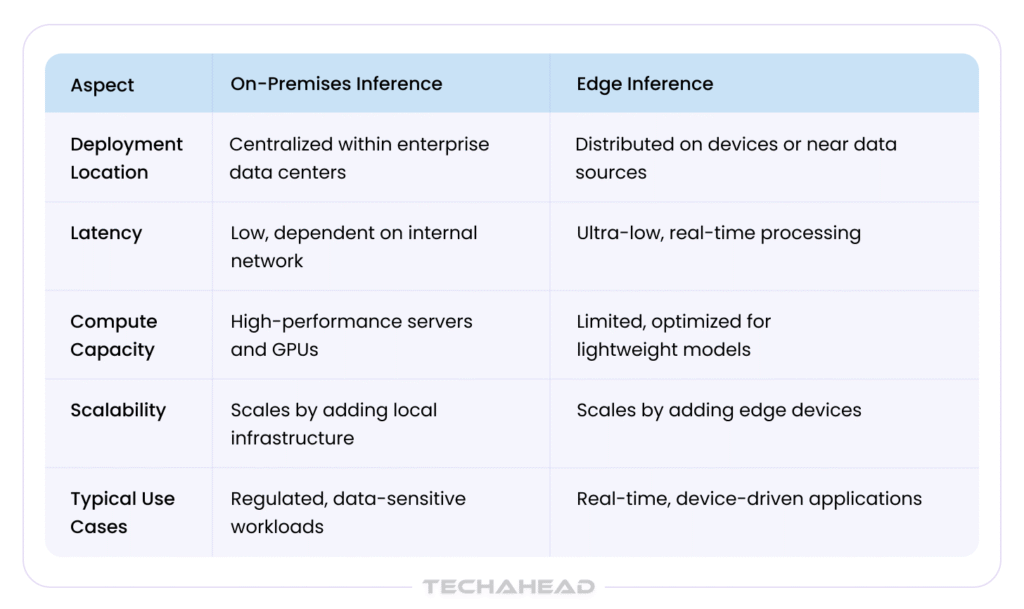
Cloud vs Edge vs On-Prem: Head-to-Head Comparison Table
| Criteria | Cloud Inference | Edge Inference | On-Prem Inference |
| Deployment Location | Centralized cloud data centers | On-device or near-device (IoT, gateways) | Customer-owned data centers |
| Latency | Moderate to high, network-dependent | Ultra-low, real-time | Low to moderate |
| Scalability | Virtually unlimited, elastic scaling | Limited by device hardware | Limited by local infrastructure |
| Data Privacy | Data transmitted to cloud | Data stays at the edge | Full data control on-site |
| Connectivity Dependency | Requires reliable internet | Minimal or no connectivity required | Internal network only |
| Operational Costs | Ongoing usage-based costs | Lower ongoing costs after deployment | High upfront, predictable long-term costs |
| Infrastructure Management | Fully managed by cloud provider | Managed across distributed devices | Fully managed by internal IT teams |
| Model Update & Maintenance | Fast and centralized | Complex, device-by-device updates | Controlled but slower rollout |
| Compute Power | High-performance GPUs/TPUs available | Limited, optimized models required | High, depending on hardware investment |
| Security Control | Shared responsibility model | Strong local security, device-dependent | Maximum security and compliance control |
| Best Use Cases | Large-scale analytics, NLP, recommendation systems | Real-time vision, autonomous systems, IoT | Regulated industries, sensitive data workloads |
| Regulatory Compliance | Depends on cloud region and provider | Easier for data residency | Ideal for strict compliance requirements |
Key Factors in the Decision Model: Cloud vs Edge vs On-Prem AI Inference
Choosing the right inference deployment model needs careful consideration of multiple factors that interact in complex ways. While cost and performance often dominate initial discussions, the optimal choice depends on a nuanced understanding of your organization’s specific constraints, such as:
Data Sensitivity and Regulatory Compliance
Data governance requirements often serve as the first filter in your decision process. Organizations handling protected health information under HIPAA, financial data subject to PCI DSS, or personal data under GDPR face strict limitations on where data can be processed and stored.
- On-premises infrastructure provides the highest level of control to maintain complete audit trails. It means your data never crosses organizational boundaries.
- Cloud providers offer compliance certifications and business associate agreements, but you are still entrusting sensitive data to a third party.
- Edge inference presents an interesting middle ground for certain use cases, processing data locally on user devices without any external transmission.

Inference Volume and Cost Structure
The economics of AI inference shift dramatically based on usage patterns. Cloud inference operates on a pay-per-use model that is economically efficient for variable or low-volume workloads, but costs can escalate quickly at scale.
Running millions of inferences daily on cloud APIs may cost substantially more than operating your own GPU infrastructure.
Generally, on-premises deployment requires significant upfront capital expenditure but offers predictable operational costs that decrease on a per-inference basis as volume increases. The break-even point occurs somewhere between processing tens of thousands to millions of inferences monthly.
On the other hand, edge deployment excels when you need to distribute inference across many endpoints, as the marginal cost per additional device is relatively low.
Latency Requirements and User Experience
Response time can make or break user experience in AI applications. Cloud inference introduces network round-trip latency, ranging from 50 to 500 milliseconds depending on geographic distance and network conditions. For applications like chatbots or document analysis, this latency is generally acceptable. However, real-time applications such as autonomous vehicles, industrial robotics, or augmented reality demand sub-10-millisecond response times that only edge or on-premises deployment can reliably achieve.
Infrastructure Expertise and Operational Capacity
The human capital required to maintain different deployment models varies enormously. Cloud inference outsources most operational complexity to the provider, requiring minimal infrastructure expertise from your team. You consume inference as a service, focusing your engineering resources on application logic rather than GPU cluster management. On-premises deployment demands sophisticated capabilities in hardware provisioning, model optimization, load balancing, monitoring, and disaster recovery.
Besides that, edge deployment introduces different challenges around device management, over-the-air updates, and handling heterogeneous hardware environments.
Scalability and Business Agility
Your ability to respond to changing demands differs fundamentally across deployment models. Cloud infrastructure scales elastically, which allow you to handle traffic spikes without advance planning that sits idle during quiet periods.
This flexibility is invaluable for startups and rapidly growing products.
On-premises scaling requires procurement cycles that can span months from identifying the need to deploying new hardware. Edge deployment scales by distributing computation across endpoints, which works well when your user base grows but struggles when individual inference demands increase beyond device capabilities. The right choice depends on whether your growth will be gradual or volatile.
Conclusion
Your optimal deployment model depends on your specific security requirements, inference volume, latency tolerance, regulatory constraints. Many successful enterprises adopt hybrid approaches; it means cloud for experimentation and edge for latency-critical applications. The key is understanding your priorities and making an informed choice aligned with your business objectives.
Ready to optimize your AI infrastructure strategy? As a top cloud consulting company, TechAhead has helped enterprises across healthcare, finance, and technology navigate complex AI deployment decisions. Our experts can assess your requirements, calculate ROI across deployment models, and build scalable inference solutions tailored to your needs. Schedule a free consultation today.

Can we use a hybrid approach combining multiple deployment models?
Absolutely. Many organizations use cloud inference for development and experimentation, on-premises for their core production workloads, and edge for latency-sensitive mobile features. A hybrid approach lets you optimize each use case independently that manages the added complexity of multiple deployment pipelines.
Can edge devices really run modern large language models effectively?
Current mobile and edge devices can run quantized models up to 3-7 billion parameters reasonably well, but struggle with larger models like 70B+ parameter LLMs. For edge deployment, you will likely need to use smaller, optimized models or implement a hybrid approach where edge handles simple queries and falls back to cloud for complex ones.
How do we handle model updates across different deployment types?
Cloud providers handle updates transparently through API versioning. On-premises requires planned rollout procedures with testing environments and gradual deployment. Edge is most challenging, requiring over-the-air update mechanisms, fallback strategies for failed updates, and handling devices that may be offline during update windows.
Can we switch deployment models later if our needs change?
Switching is easier in some directions than others. Moving from cloud to on-premises or edge requires significant engineering effort to optimize models for constrained environments. Moving from on-premises to cloud is relatively simple.