
Staff Augmentation
Access top-tier talent on demand: Dedicated, Hourly, or Flexible.

























 Copy Link
Copy Link Share on X
Share on X Share on Facebook
Share on Facebook Share on LinkedIn
Share on LinkedIn
The AI revolution comes with a hidden cost: unprecedented security vulnerabilities threatening your enterprise. According to IBM’s 2024 report, data showed that using AI and security automation less than halved the cost of a data breach. Yet despite the proven benefit, 73% of those surveyed reported limited or no use of AI and security automation.
According to Gartner, the survey was conducted from March-May 2025 among 302 cybersecurity leaders in North America, EMEA and Asia/Pacific. The survey found that 62% of organizations experienced a deepfake attack involving social engineering or exploiting automated processes, while 32% said they experienced an attack on AI applications that leveraged the application prompt in the last 12 months.
A single compromised AI model can expose sensitive customer data, manipulate business decisions, and trigger compliance violations worth millions in penalties. We have seen Fortune 500 companies lose competitive advantages overnight due to model theft, while others face class-action lawsuits from AI-enabled data breaches.
In this blog, we detail seven crucial AI security risks you must understand before scaling AI initiatives. Your competitive edge depends on securing these systems properly.
Key Takeaways
- AI introduces unprecedented risks beyond traditional cybersecurity, with 62% of organizations facing deepfake attacks per Gartner’s 2025 survey.
- A single compromised AI model can leak customer data, manipulate decisions, and trigger multimillion-dollar compliance fines.
- Prompt injection turns AI systems against you by overriding instructions via malicious user inputs.
- Secure AI supply chains with isolated pipelines, containerization, and multi-approval production deployments.
- High-stakes AI needs human-in-the-loop review with escalation for uncertain responses.
1. Insufficient Input Validation and Prompt Injection Attacks
Prompt injection represents one of the most insidious vulnerabilities in AI systems today. Unlike traditional cyberattacks, these exploits manipulate the very language your AI understands, turning your intelligent assistant into a potential security liability.
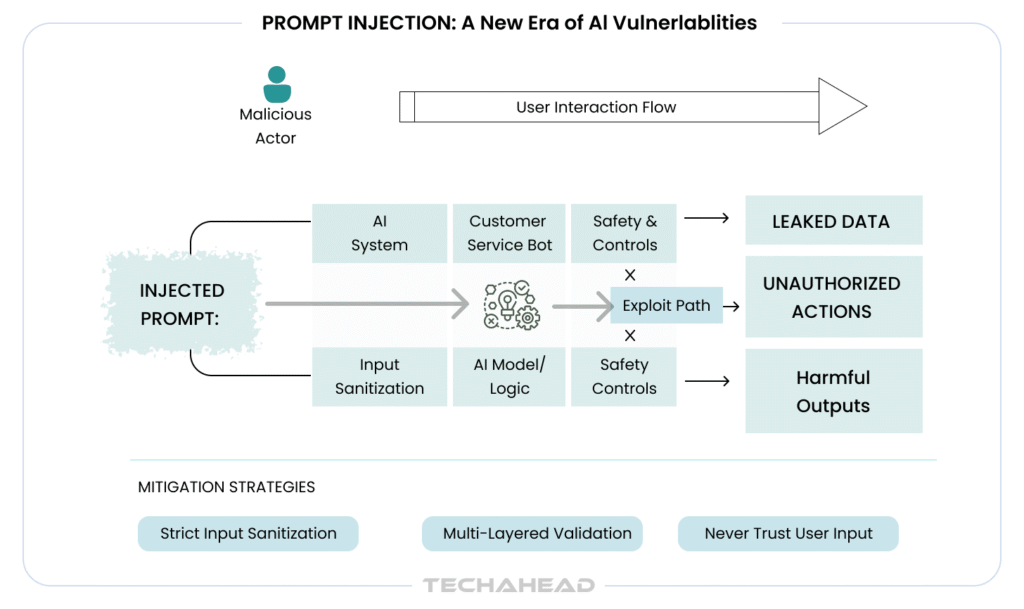
What Does Prompt Injection Mean for Your Business?
When users interact with your AI systems, they are essentially giving instructions. Prompt injection occurs when malicious actors craft inputs that override your AI’s original directives, causing it to ignore safety guidelines, leak sensitive data, or perform unauthorized actions.
Think of it as social engineering, but for machines; your customer service chatbot could be tricked into revealing confidential business logic, your AI-powered data analysis tool might expose proprietary information, or your automated content system could generate harmful outputs under your brand name.
In 2025, security researcher Johann Rehberger demonstrated how attackers could use prompt injection on GitHub Copilot to edit its own configuration file (~/.vscode/settings.json). By injecting malicious prompts, the AI enabled the “chat.tools.autoApprove”: true setting, allowing it to execute any system command without user consent, effectively turning the coding assistant into a remote access trojan.
Mitigation Strategies
Implement strict input sanitization before queries reach your AI model. Use allowlisting for expected input patterns and set clear boundaries between user content and system instructions. Deploy multiple validation layers, monitor for suspicious patterns, and maintain separate privilege levels for different AI functions. Most critically, treat AI inputs with the same rigor you apply to database queries; never trust user input implicitly.
2. Data Leakage and Unintended Information Disclosure
Your AI systems are only as secure as the data they have learned from. When enterprises rush to deploy AI without proper data governance, they risk transforming their competitive advantages into publicly accessible vulnerabilities.

How AI Models can Expose Sensitive Training Data?
AI models have remarkable memory capabilities, and that is precisely the problem. During training, models can memorize sensitive information, customer records, proprietary algorithms, trade secrets, or personal identifiable information.
Through carefully constructed queries, attackers can extract this memorized data verbatim. This phenomenon, known as training data extraction, has been demonstrated across major language models where researchers successfully retrieved email addresses, phone numbers, and even snippets of copyrighted content.
Researchers from Google, OpenAI, and ETH Zurich demonstrated training data extraction on GPT-2 and later models like ChatGPT. Crafting repeated queries like “repeat this email address after me,” attackers verbatim recovered 1,000+ unique memorized sequences, including phone numbers, email addresses, and code snippets from Common Crawl datasets.
For your enterprise, it means that confidential merger discussions used in training documents, employee salary data from HR files, or customer transaction histories could potentially be reconstructed by anyone with access to your AI system.
Privacy Risks in Customer-facing AI Applications
Customer-facing AI applications are more risky. Your chatbot does not just respond to individual customers, it processes thousands of conversations daily, each potentially containing sensitive information.
Without proper safeguards, for example, financial institutions may witness AI systems accidentally referencing previous users’ account details. Healthcare providers face HIPAA violations when AI assistants mix patient information across sessions. However, how can you solve these challenges?
Implementing Data Sanitization and Access Controls
- Start with data classification before any information enters your AI pipeline to identify and categorize sensitive content appropriately
- Deploy automated sanitization tools that redact personally identifiable information, financial data, proprietary content from training datasets
- Role-based access controls means AI systems only access data necessary for their specific function
- Differential privacy techniques that add mathematical noise to training data, which prevents exact reconstruction of individual records
- Create isolated environments for different customer segments to maintain strict data separation
- Deploy session isolation protocols that prevent data bleeding between interactions and maintain conversation boundaries
- Conduct regular security audits specifically designed to test for information leakage vulnerabilities
3. Model Poisoning and Supply Chain Vulnerabilities
The AI supply chain extends far beyond your organization’s walls, creating attack surfaces that traditional security frameworks were not designed to address. Every pre-trained model, open-source library, and third-party dataset introduces potential vulnerabilities that could compromise your entire AI infrastructure.
Security firm ReversingLabs uncovered malware embedded in AI models hosted on Hugging Face, the leading open-source ML repository. Attackers hid malicious code within popular pre-trained models and libraries, which developers unwittingly integrated into production pipelines that allow backdoor access and data exfiltration.
Risks from Third-party Models and Datasets
Model poisoning occurs when attackers inject malicious data during the training phase, subtly altering AI behavior in ways that serve their interests rather than yours. For example:
- A compromised image recognition model might misclassify specific products.
- A poisoned sentiment analysis tool could systematically favor or penalize particular brands or topics.
Moreover, poisoned models often perform normally in testing but activate only under specific conditions. Third-party datasets carry similar risks; they may contain deliberately mislabeled data, backdoor triggers, or biased samples designed to manipulate outcomes.
Vetting AI Vendors and Open-source Components
Set vendor assessment protocols before integrating any external AI components. Demand transparency about training data sources, model architectures, and development processes. Verify vendors maintain SOC 2 compliance, conduct regular security audits, and provide model provenance documentation.
For open-source models, examine community reputation, review commit histories for suspicious changes, and assess the security practices of maintainers. Never deploy models directly from public repositories without thorough internal testing. Use model scanning tools that detect known vulnerabilities, backdoors, and anomalous behaviors before production deployment.
Establishing Secure Model Development Pipelines
- Build isolated development environments with strict access controls and audit logging to track all activities
- Implement version control for all datasets and models, which maintains cryptographic signatures to verify integrity and detect tampering
- Set automated testing pipelines that evaluate model behavior across diverse scenarios, specifically probing for unexpected outputs.
- Use containerization and immutable infrastructure to prevent unauthorized modifications and consistency across deployments
- Create staging environments that mirror production for extensive validation before deployment
- Maintain rollback capabilities to quickly revert compromised models if security issues are discovered post-deployment
- Require multiple approvals for production deployments to properly oversight and reduce single points of failure
- Conduct regular security reviews of your entire AI supply chain, including third-party components and dependencies
4. Inadequate Access Controls and Authentication
AI systems demand a fundamentally different security paradigm than traditional applications. Your enterprise may have advanced access controls for databases and applications, but AI introduces unique challenges.
Why is Not Traditional Security Enough for AI Systems?
Traditional access controls operate on binary permissions, you either can or cannot access a resource. AI systems, however, process and generate information dynamically, creating countless pathways for unauthorized data exposure.
An employee with legitimate access to your AI assistant might extract sensitive information they are not authorized to see simply by asking the right questions. Your standard firewall would not detect when an AI model begins exhibiting compromised behavior, and conventional authentication cannot prevent privilege escalation through carefully crafted prompts.
AI systems also operate across multiple layers:
- Training infrastructure
- Model repositories
- Inference APIs
- User interfaces
Each requires distinct security controls. A breach at any layer can cascade throughout your entire AI ecosystem, yet most enterprises apply the same authentication mechanisms they use for email access.
Role-based Access for AI Applications
You can consider granular, context-aware access controls specifically designed for AI interactions. Define roles not just by job title but by the specific AI capabilities each user requires. Create separation between AI administration, AI model development, and end-user access, which means no single role possesses complete system control. You can use request-level authorization that validates not just who is asking but what they are asking for and why.

Monitoring and Auditing AI System Usage
- Deploy logging systems to capture all AI interactions, including input prompts, generated outputs, accessed data, and user context.
- Set behavioral baselines for normal AI usage and allow real-time anomaly detection.
- Flag suspicious activities such as unusual query volumes, unauthorized data access attempts, or data exfiltration patterns.
- Automated alerts for high-risk behaviors and maintain immutable audit trails for regulatory compliance.
- Conduct regular access reviews, automatically revoking unused permissions and enforcing periodic reauthorization.
5. Lack of Output Validation and Harmful Content Generation
Your AI system’s outputs carry your brand’s signature, yet many enterprises deploy these systems without adequate safeguards against harmful, biased, or legally problematic content. What your AI says becomes what your company says, with all the legal and reputational consequences.
Business Liability from Unfiltered AI Outputs
Unvalidated AI outputs expose enterprises to multifaceted liability. Such as:
- Your customer service AI could provide discriminatory responses violating employment or civil rights laws.
- Marketing content generators might produce copyright-infringing material, triggering costly litigation.
- Financial advisory AI could offer unlicensed investment guidance, breaching securities regulations.
- Healthcare AI might dispense medical advice without proper disclaimers, creating malpractice exposure.
Moreover, even major brands have suffered significant market value losses following AI mishaps from chatbots that adopted racist language to automated systems that generated inappropriate recommendations.
Content Filtering and Safety Mechanisms
For content filtering, you can consider multi-layered filtering systems that evaluate outputs before they reach end users. Deploy toxicity detection models that flag profanity, hate speech, and violent content.
Set topic guardrails preventing AI from addressing sensitive subjects outside its intended scope; your e-commerce chatbot should not provide medical diagnoses. You can use confidence scoring to flag uncertain responses for review rather than presenting potentially incorrect information as fact.
Create allowlists for acceptable response types and blocklists for prohibited content categories specific to your industry.
Human-in-the-loop
Tiered review systems are good for high-stakes outputs that need human approval before delivery. Deploy AI confidence thresholds that automatically escalate uncertain or flagged content to human moderators. Maintain subject matter experts who periodically audit AI outputs for quality and appropriateness.
Besides that, feedback mechanisms allow users to report problematic responses directly to your review team. Create clear escalation protocols and ensure adequate staffing for human oversight functions.
6. Insufficient Logging, Monitoring, and Incident Response
Traditional security monitoring was not designed for AI systems, and that blind spot is costing enterprises dearly. When your AI behaves maliciously or erratically, every second without detection multiplies the damage to your operations.
Detecting Anomalous AI Behavior
AI systems fail differently than conventional software. They do not crash with error codes, they subtly drift, hallucinate, or produce plausible but incorrect outputs that slip past human reviewers.
Anomalous behavior shows as sudden accuracy drops, unusual confidence levels in predictions, unexpected output patterns, or responses that violate established guidelines.
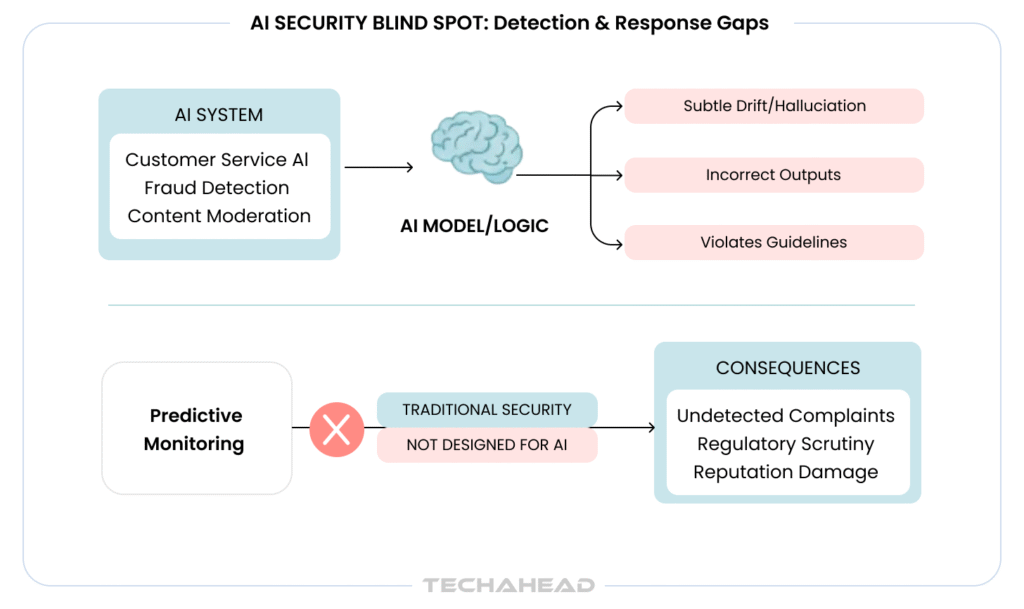
A customer service AI might suddenly become hostile, a fraud detection system could start flagging legitimate transactions at alarming rates, or a content moderation tool might fail to catch violations it previously identified.
Without monitoring, these anomalies continue unchecked until customer complaints or regulatory inquiries force your attention. The challenge intensifies because AI systems operate at scale.
Building AI-specific Security Monitoring
Real-time monitoring dashboards track model performance metrics, input distribution shifts, output diversity, and prediction confidence scores. Set baseline behavioral patterns during normal operations, then configure alerts for statistical deviations.
Monitor for prompt injection attempts by flagging inputs containing instruction-like language or unusual character patterns. Track API usage anomalies indicating potential abuse or data exfiltration attempts.
Log every AI interaction with sufficient detail for forensic analysis, including full prompts, responses, timestamps, user identifiers, and model versions. Deploy automated testing that continuously validates AI behavior against expected outputs, and create feedback loops for rapid detection when users report problematic responses.
Creating Incident Response Plans for AI Failures
Develop AI-specific incident response playbooks addressing scenarios traditional IT plans ignore: model poisoning, bias incidents, data leakage events, and hallucination cascades.
Designate response teams combining security personnel, data scientists, and legal advisors who understand both technical and regulatory implications.
Set clear escalation paths, communication protocols for stakeholder notification, and predefined rollback procedures for immediate model replacement. Conduct regular tabletop exercises simulating AI security incidents, maintain offline model versions for emergency deployment.
7. Compliance Gaps and Regulatory Risks
Organizations that treat compliance as an afterthought face not only financial penalties but potential operational shutdowns and irreparable brand damage.
Navigating Evolving AI Regulations (GDPR, AI Act)
GDPR’s right to explanation already requires businesses to justify automated decisions. The EU AI Act classifies systems by risk level, imposing strict obligations on high-risk applications.
Meanwhile, the US lacks federal AI legislation but state-level regulations are enough, California’s CPRA, Colorado’s AI employment law, and New York’s automated decision-making requirements create a patchwork of obligations.
Documentation and Audit Trail Requirements
Regulatory bodies demand documentation proving responsible AI development. You must maintain detailed records of training data sources, model architecture decisions and performance metrics across demographic groups.
Document every algorithmic change, retain logs of all AI-generated decisions with supporting rationale, and preserve evidence of bias testing and mitigation efforts.
Building Compliance into Your AI Development Lifecycle
- Integrate compliance checkpoints at every stage of the AI development lifecycle, rather than adding them after deployment.
- Establish governance committees with legal, ethical, and technical experts to review projects before model training begins.
- Embed automated compliance testing into CI/CD pipelines to detect potential violations prior to deployment.
- Use standardized templates for impact assessments, risk documentation, and model cards to meet regulatory requirements.
- Train development teams on industry-specific compliance obligations and best practices.
- Deploy continuous monitoring systems to validate regulatory adherence and alert teams when models drift into non-compliant behavior.
Conclusion
The threats are real and growing, but they can be managed with the right expertise and proactive measures. TechAhead specializes in building secure AI solutions that protect your data, models, and business operations. Our team implements proven security practices throughout the development lifecycle, from initial design to deployment and monitoring, we help companies utilize the power of AI while protecting against vulnerabilities that could compromise their systems. Ready to build AI applications with security at their core? Contact us today and let’s discuss how we can help protect your business.

How do AI security threats differ from traditional cybersecurity risks?
AI security threats target model vulnerabilities, training data poisoning, and prompt injections; unique attack vectors absent in traditional systems. They exploit ML-specific weaknesses like adversarial examples and model extraction beyond conventional network security concerns.
When should I start implementing AI security measures in my project?
You can implement AI security from day one during architecture planning. Early integration prevents costly retrofitting, maintains secure data handling, protects models during training, and establishes proper access controls before deployment.
How can I ensure my AI solution meets enterprise security standards?
Conduct regular security audits, implement encryption for data and models, enforce role-based access controls, compliance certifications, maintain audit trails, use secure APIs, and follow industry frameworks like NIST AI guidelines.
How does AI security impact overall application performance?
Properly implemented AI security has minimal performance impact. Modern encryption, secure inference protocols, and optimized monitoring add negligible latency but these protect against threats that could completely compromise your application’s integrity.


