
Staff Augmentation
Access top-tier talent on demand: Dedicated, Hourly, or Flexible.

























 Copy Link
Copy Link Share on X
Share on X Share on Facebook
Share on Facebook Share on LinkedIn
Share on LinkedIn
We’re now living in a time where technology can do more than just respond to what we type or say; it can also recognize facial expressions, understand images, and interpret sounds, all at the same time. This is the power of multimodal AI, a new wave of artificial intelligence that combines different types of data to create interactions that feel more natural and intuitive, almost like talking to another person.
The journey really picked up speed in 2023 with the release of GPT-4, which marked a major step forward by handling both text and images. Fast forward to today, and the latest model, GPT-4o Vision, has taken things even further, enabling experiences that are remarkably lifelike. Over the past year, multimodal AI has become one of the most talked-about innovations in the world of generative AI, thanks to its potential to transform how we interact with machines.
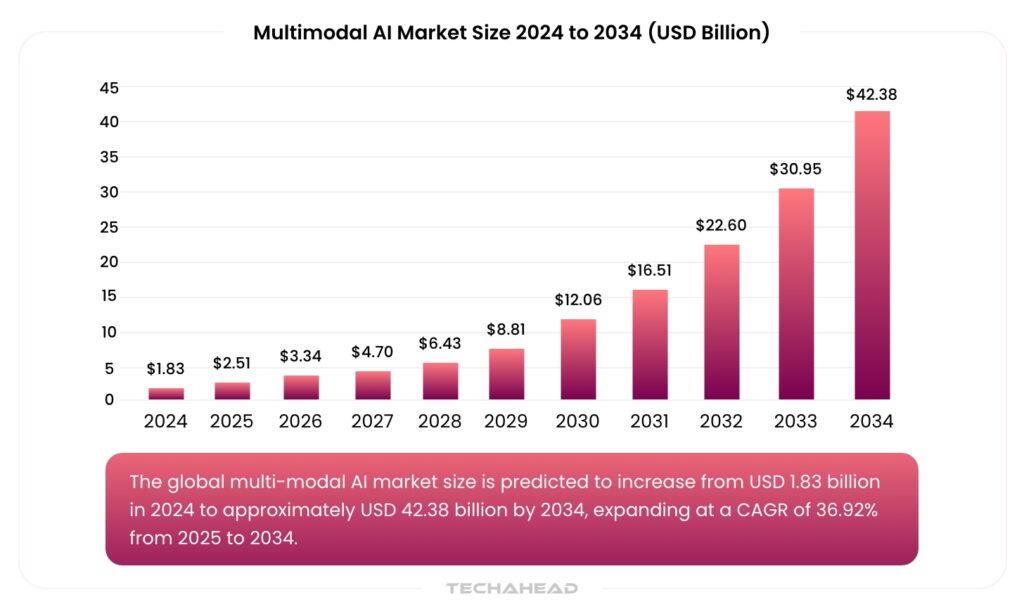
This rising interest is reflected in the numbers. In 2024, the global multimodal AI market was valued at $1.83 billion, and it’s projected to soar to over $42 billion by 2034, growing at an impressive annual rate of nearly 37%. Businesses are already taking notice. From retail environments using AI-powered assistants that respond to what customers are looking at to customer service platforms that understand not just what people say but how they feel, multimodal AI is being tailored to fit real-world needs in powerful ways.
In this blog we’ll learn about what multimodal AI is, how large multimodal models are built and trained, and how you can adapt this technology to fit your business with the help of TechAhead.
What is Multimodal AI?
Multimodal AI refers to advanced artificial intelligence systems that can simultaneously process, interpret, and integrate multiple types of data, or modalities, such as text, images, audio, video, and other forms of sensory input. This cross-modal capability enables AI to extract meaning from various sources and combine them to form a deeper, more holistic understanding of information.
In contrast to unimodal AI, which is designed to handle only a single data type, like text or image. Multimodal models fuse diverse streams of input, allowing for richer interpretation and more versatile functionality. This integration significantly enhances the model’s ability to perform complex tasks that mimic human perception and cognition more closely.
Why Multimodal AI Matters: Enhancing Intelligence Through Data Fusion
The real strength of multimodal AI lies in its ability to leverage complementary data to overcome limitations associated with analyzing just one modality. By merging inputs from various sources, these systems can make more accurate predictions, resolve ambiguities, and generate context-aware outputs.
For example, a model might receive an image of a mountain landscape and then generate a descriptive caption that outlines its features, such as snow-covered peaks or lush green valleys. Conversely, if given a text-based description, the same model can visualize and generate an image that aligns with that narrative. This bidirectional capability across data types unlocks a wide range of possibilities in industries like media, healthcare, retail, and education.
From Unimodal to Multimodal: The Evolution of Generative AI
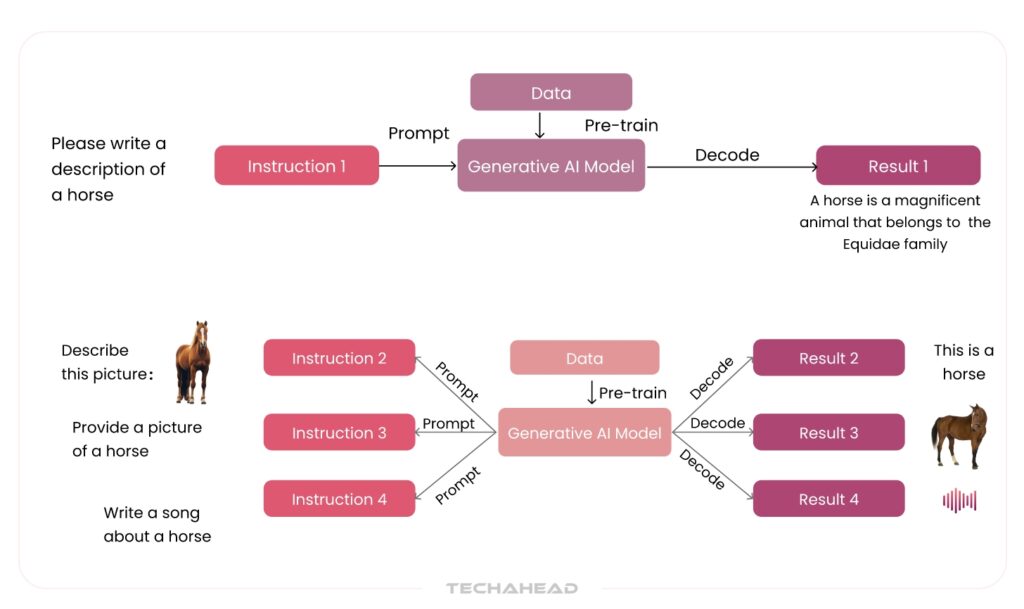
The journey began with models like ChatGPT, launched by OpenAI in November 2022. This early version was an unimodal model; it accepted text inputs and produced text outputs, excelling at natural language tasks like summarization, translation, and dialogue generation.
However, the landscape quickly evolved. Tools like DALL·E marked a turning point, introducing multimodal functionality by allowing users to input text prompts and generate corresponding images. With the release of GPT-4o, OpenAI further expanded ChatGPT’s capabilities by enabling it to process and respond to text, images, and audio, making it a fully multimodal interface.
Expanding Applications of Multimodal AI
Generative AI is transforming how industries operate by unlocking powerful new capabilities across diverse domains. Its ability to autonomously generate content, simulate scenarios, and optimize processes is driving innovation at an unprecedented pace. Let’s explore some of the most impactful use cases:
Content Creation and Social Media Optimization
Generative AI is becoming an indispensable asset. It enables brands to produce high-quality, tailored content more quickly than ever before. From drafting content and marketing copy to brainstorming creative campaign ideas. AI tools are taking over the more repetitive tasks, freeing up human teams to focus on strategy and innovation.
Social platforms such as LinkedIn and Microsoft Teams are already adopting AI features that suggest engaging headlines, generate visuals based on written prompts, and personalize posts to better connect with target audiences. These capabilities help marketers craft stories that not only reflect their brand voice but also resonate with the right demographics. The result? Smarter campaigns, stronger engagement, and more consistent brand messaging across digital channels.
Healthcare Innovation and The Role of Synthetic Data
Multi-model generative AI is playing a pivotal role in advancing healthcare solutions. One of its most impactful uses is in creating synthetic patient data, artificial datasets that mimic the characteristics of real medical records without exposing sensitive personal information. This allows researchers and developers to train machine learning models while complying with strict privacy regulations.
Beyond data generation, AI is accelerating the drug discovery process by designing potential molecular compounds and forecasting how they’ll interact with the human body. It also assists in medical imaging, improving resolution and helping detect anomalies that might otherwise go unnoticed. Moreover, AI can model treatment outcomes and predict patient responses, enabling more accurate, data-informed clinical decisions and paving the way for personalized medicine.
Automating Workflows and Boosting Enterprise Efficiency
In the business world, efficiency is everything, and this is where generative AI excels. Automating time-consuming tasks helps companies run leaner operations. Whether it’s generating code, writing technical documentation, or drafting internal reports, AI is cutting down on manual work and accelerating delivery timelines.
Customer service is another area that’s being reimagined. AI-powered chatbots are becoming more responsive and context-aware, allowing them to engage with customers in a more natural, conversational manner. These systems learn from previous interactions and adjust over time, improving their ability to resolve issues quickly and effectively.
On the enterprise side, generative AI supports intelligent process automation, helping businesses make better use of their resources while maintaining flexibility and responsiveness in day-to-day operations.
Transforming Creative Work in Arts and Entertainment
In industries like art, music, film, and design, AI tools are helping creators bring their visions to life. With platforms like DALL·E, MidJourney, and Runway ML, artists can turn simple text prompts into visually striking artwork, storyboards, or animations, offering a new dimension to idea generation and design exploration.
In film and media production, AI is being used to assist with script development, scene planning, and even video editing. All this reduces production timelines and opens up new creative possibilities. Musicians are also experimenting with AI-generated melodies and harmonies, using them as a foundation to build innovative soundscapes. Instead of replacing the artist, AI serves as a collaborative partner, expanding creative boundaries and offering new tools for expression.
Improving Training Data and Promoting AI Transparency
Strong AI systems rely on clean, representative data, and this is another area where generative AI is making a difference. By enriching and balancing datasets, it helps developers build models that are not only more accurate but also more inclusive. This is particularly valuable in areas where data is scarce or skewed, such as in medical diagnostics or financial forecasting.
At the same time, there’s growing demand for explainability in AI systems, especially in industries where decisions carry significant consequences. Generative AI supports explainable AI initiatives by helping visualize how decisions are made and flagging potential sources of bias. This transparency builds trust and ensures that AI technologies are used responsibly, ethically, and in alignment with human values.
Core Concepts of Multimodal A
Multimodal generative AI represents a significant leap forward from traditional large language models (LLMs). Unlike text-only models, these systems are designed to process and synthesize information from multiple data formats, such as text, images, audio, video, and even code. This added complexity not only increases the technical sophistication of the models but also dramatically broadens their application scope.
At the heart of these models lies the transformer architecture, a groundbreaking neural network framework introduced by Google researchers. Transformers revolutionized the AI field by introducing mechanisms like attention and encoder-decoder pipelines, which allow models to dynamically focus on the most relevant pieces of data across sequences. This is what enables the models to generate coherent, context-aware outputs even when juggling inputs from various modalities.
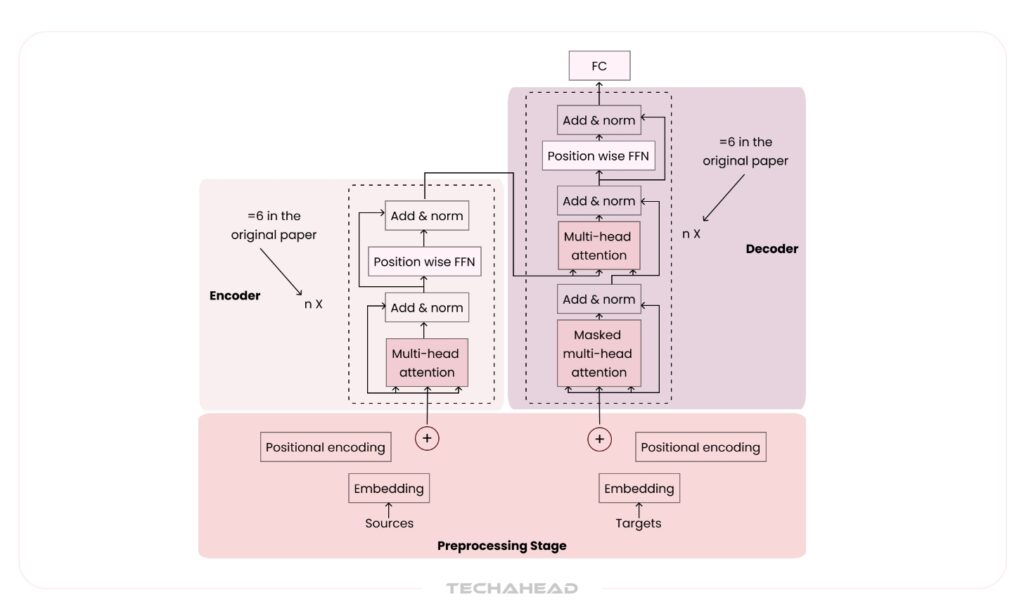
How Multimodal AI Understands Diverse Data Types?
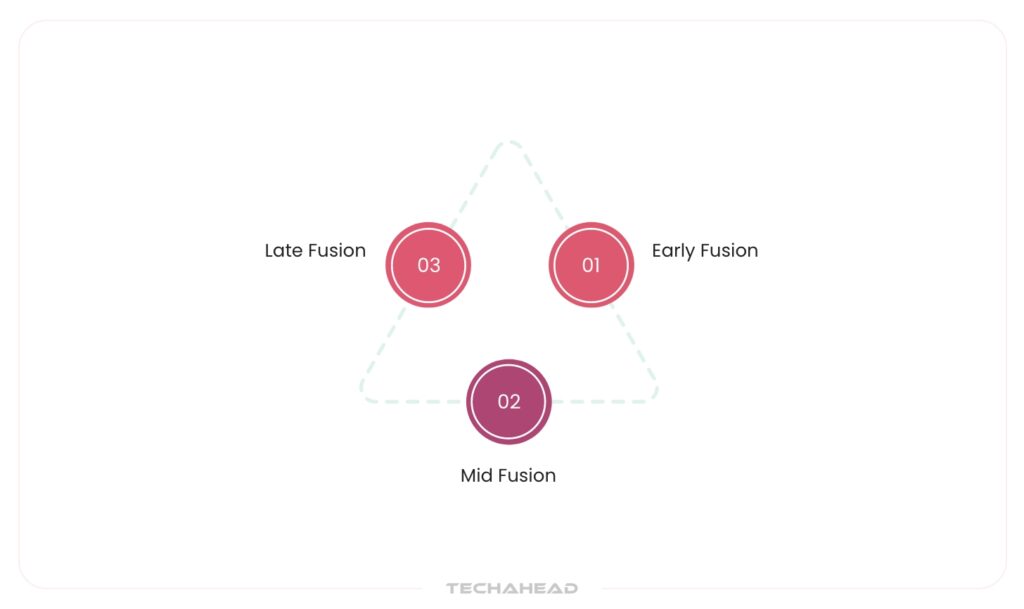
Multimodal AI stands out due to its ability to perform data fusion. The process of integrating information from different modalities to create a unified and richer understanding of the data. The ultimate aim is to generate smarter, more informed predictions by supporting the complementary strengths of each data type. For example, combining a medical image with a radiology report offers more insight than either alone.
Depending on when and how the data is merged within the model pipeline, data fusion techniques are typically divided into three main categories.:
Early Fusion
In early fusion, inputs from different modalities, images and text, are first encoded into a shared representation space before any significant modeling begins. This common space allows the model to interpret all input types uniformly, regardless of their original format.
This technique is powerful for tasks where the modalities are tightly coupled, such as generating image captions or answering questions based on visual inputs. Since the information is blended right from the beginning, the model can learn cross-modal correlations more deeply, making it more context-aware and semantically aligned across data types.
Mid Fusion
Mid fusion, sometimes referred to as hybrid fusion, merges data during the model’s internal processing stage. Here, each modality may undergo initial processing through separate encoders. Then, within the architecture, usually in specially crafted fusion layers. The outputs of these encoders are integrated.
This method gives the model a chance to preserve the uniqueness of each modality early on, while still enabling intermodal interaction at a deeper level. It’s particularly useful in tasks where different types of data provide distinct but interconnected insights, such as pairing spoken dialogue with facial expressions in emotion recognition.
Late Fusion
In late fusion, each modality is handled by its dedicated model or sub-network. Once the models produce their outputs, a post-processing algorithm or decision layer merges them to produce the final result.
This approach is generally easier to implement and is well-suited for scenarios where the modalities are loosely related or independent. For instance, combining a financial report (text) with market trend graphs (visuals) might not require deep cross-modal entanglement, making late fusion more efficient and interpretable.
Choosing the right data fusion strategy
There is no universal blueprint for multimodal fusion that fits every use case. Each task has its own requirements in terms of context, complexity, and data dependency. As such, selecting the right strategy: early, mid, or late fusion, often involves a trial-and-error approach. Developers need to experiment with different fusion architectures and training strategies to determine what works best for their specific objectives.
What remains clear, however, is that effective data fusion lies at the core of building powerful multimodal systems. The better a model can merge diverse inputs into a coherent understanding, the more accurate, versatile, and intelligent its outputs become.
Understanding Multimodal AI through Different Models
Multimodal AI can express itself in multiple formats ranging from text-to-image, text-to-audio, and audio-to-image to combinations of all these modalities, including text-to-text interactions. While the outputs may differ across these applications, the fundamental mechanics behind these models remain largely consistent. They all rely on converting different types of inputs into a shared representational format that machines can interpret and generate from.
To better understand how this works in practice, let’s zoom in on the specifics of these models.
Text-to-Image Models

The Diffusion Process
At the core of most text-to-image models is a technique known as diffusion modeling. This process starts with what’s essentially random visual noise, like static on a TV screen, also called Gaussian noise. Initially, this noise contains no meaningful structure.
However, as the model begins to denoise the image step-by-step, it starts shaping the randomness into something visually coherent. On its own, early diffusion models lacked purpose; they could generate images, but often those outputs were irrelevant or unrecognizable. That’s where the addition of textual prompts came into play.
Guiding Visual Generation with Language
By incorporating textual inputs, such as “a golden retriever sitting in a park,” the model gains a semantic direction. Essentially, the system uses this text to guide the transformation of noise into a clear and relevant image. So, when given the word “dog,” it learns to shape the noise into a familiar and accurate depiction of a dog.
This is possible because both text and images can represent the same underlying concept. A written word and its corresponding visual representation, like “dog” and a dog photo, point to the same real-world idea. This shared meaning becomes the bridge between modalities.
Vector Representations
The model achieves this cross-modal alignment by converting both text and images into mathematical vectors, essentially high-dimensional coordinates that encode meaning. These vectors capture not just superficial features, but the essence of the content.
For example, vectors for the words “puppy,” “dog,” and “canine” would be placed close to each other in the model’s semantic space, just as images of various dog breeds would cluster together. This allows the AI to match text prompts with the most conceptually similar visual content, even if the exact words or image formats vary.
Audio-to-Image
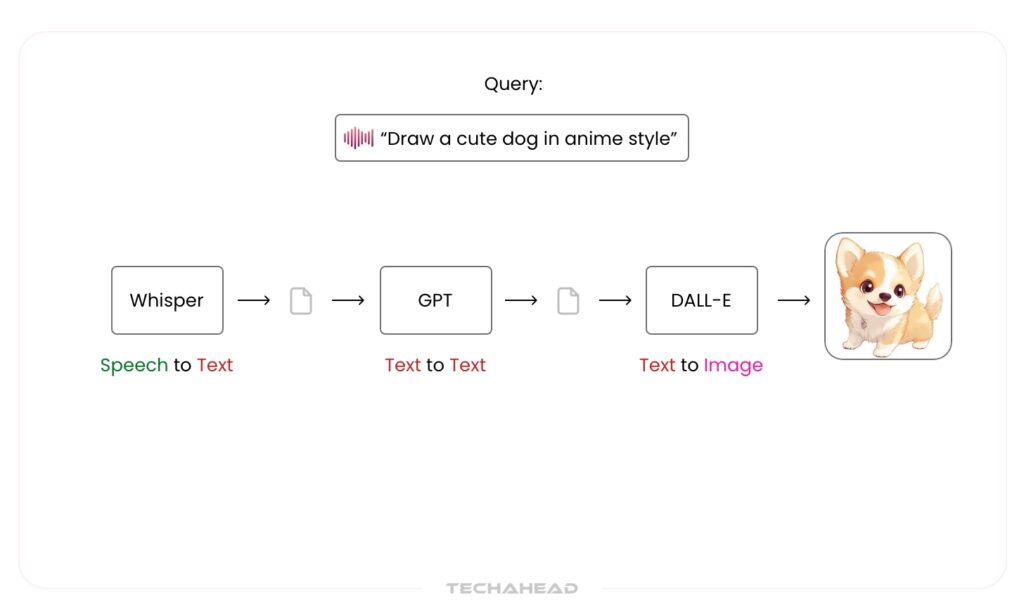
Unlike text-to-image generation, the process of creating images directly from audio is more intricate and less mature. Currently, no single model directly transforms audio into visuals. Instead, the task involves a pipeline of multimodal transformations, usually broken into three main stages:
Translating Audio to Text
Audio is typically first transcribed into text using speech recognition models. Text serves as a sort of universal language for AI, making it easier to connect and interpret different data types. This is because text can express fine-grained details and structured information more precisely than raw audio or images.
For example, if someone describes a scene verbally“a sunset over a mountain range,” the system first turns this description into written text. This textual representation becomes the anchor for the next phase.
Leveraging Text-to-Image Capabilities
Once the audio has been translated into a descriptive prompt, the text is then fed into a pre-trained text-to-image model, which generates the corresponding image. The image that results reflects the conceptual understanding extracted from the original spoken input.
Although this approach seems indirect, it’s currently the most reliable method for bridging the gap between sound and visuals, due to the strong semantic representation that text provides.
Learning Through User Feedback and Multi-Output Training
The exact mechanics of how models determine whether to output text, images, or both remain partially opaque. However, it’s likely that during training, these models are exposed to scenarios where multiple output types are valid. Users may select which outputs they find most useful, effectively teaching the model over time to predict the most context-appropriate output, whether it’s a generated sentence, an image, or both.
This iterative, feedback-driven learning process helps the model improve in predicting and producing coherent, relevant visuals from varied inputs, including spoken language.
Real-World Use Cases of Multimodal AI

Multimodal AI stands out for its versatility, offering advanced capabilities that extend far beyond the limitations of traditional, unimodal systems. By combining inputs, multimodal AI can interpret complex scenarios, enhance human-machine interaction, and deliver smarter, context-aware solutions. Let’s explore how this transformative technology is being applied across various industries and domains:
Smarter Computer Vision
Traditional computer vision focuses on identifying objects in static images. However, multimodal AI pushes these capabilities further by incorporating additional context, such as sound, text, or spatial data, to make more accurate and informed judgments.
For instance, recognizing a dog in an image becomes far more reliable when the system also processes the accompanying barking sound. Similarly, integrating facial recognition with natural language processing (NLP) can significantly enhance identity verification in high-security environments. This layered understanding makes image analysis more precise, dynamic, and applicable to real-world scenarios like surveillance, smart cities, and autonomous vehicles.
Industrial Intelligence
In industrial settings, multimodal AI enables data-driven decision-making by analyzing inputs from various sources like machinery sensors, maintenance logs, and real-time video feeds. This helps companies monitor production lines, detect quality deviations early, and predict equipment failures before they occur.
In the healthcare sector, multimodal systems merge patient vital signs, lab results, medical histories, and imaging data (like X-rays or MRIs) to support more accurate diagnoses and personalized treatment plans. Meanwhile, in the automotive industry, in-cabin cameras and biometric sensors work in tandem to track driver fatigue, detecting signs such as drooping eyelids, erratic steering, or prolonged yawning. If the system senses drowsiness, it can recommend pulling over or suggest an alternate driver.
Enhanced Language Understanding
Multimodal AI also plays a crucial role in natural language processing (NLP) by introducing emotion-aware capabilities. Instead of relying solely on spoken or written words, these systems interpret tone of voice, facial expressions, and body language to assess a user’s emotional state more accurately.
For example, if a user’s voice sounds strained and their expression looks angry, the AI can infer stress or frustration and adjust its response accordingly, perhaps by offering reassurance or escalating to a human agent. This emotionally intelligent interaction is vital in sectors like mental health, virtual assistants, and online learning platforms.
Moreover, by integrating speech and written input, the AI can help users refine pronunciation, improve language fluency, and better understand dialects in real-time.
Robotics
Robots must operate in real-world settings where relying on a single type of data isn’t enough. Multimodal AI equips them to perceive their surroundings using a combination of cameras, microphones, LIDAR, GPS, and pressure sensors. This allows robots to not only see and hear but also respond to different stimuli in meaningful ways.
For example, in a warehouse, a robot might analyze voice commands, avoid obstacles using visual inputs, and recognize delivery instructions printed on packages. This multi-sensory approach is critical in applications like autonomous delivery, smart manufacturing, and elderly care assistance.
Augmented and Virtual Reality (AR/VR)
In AR and VR applications, multimodal AI unlocks deeply immersive and intuitive interactions by synchronizing audio, visuals, motion, and touch. In augmented reality, combining sensor data with gesture and voice recognition allows users to interact with digital elements as if they were real—think virtual interior design apps that adjust furniture based on voice input and room layout.
In virtual reality, this synergy creates dynamic environments where users can engage with responsive avatars, experience realistic haptic feedback, and receive tailored experiences based on eye tracking, facial expressions, or even heart rate. This opens new frontiers in gaming, remote training, therapy, and virtual collaboration.
Advertising and Marketing
Multimodal AI is revolutionizing how brands connect with their audiences by enabling hyper-personalized and data-informed marketing campaigns. By analyzing a mixture of user-generated content through AI can uncover deeper insights into consumer behavior and preferences.
This allows marketers to craft campaigns that are not only visually appealing but also emotionally resonant. For instance, analyzing a user’s tone in product feedback combined with image sentiment can help tailor promotions that reflect their mood or lifestyle, ultimately increasing engagement and conversion rates.
Seamless User Experiences
Multimodal AI enables a shift from rigid input formats to natural, flexible interactions that mirror human communication. Users no longer need to describe problems in detail; simply uploading a picture or sharing a voice note can be enough for the AI to understand the context and provide solutions. These things can enhance the user experience of the users for better usage of mobile applications.
For example, imagine uploading a photo of your fridge and receiving recipe suggestions based on what’s inside, or recording the sound your car engine makes to help diagnose a mechanical issue. These hands-free, frictionless experiences make technology more accessible and user-friendly.
Disaster Responses and Crisis Management
In high-stakes environments such as natural disasters, multimodal AI improves response effectiveness by aggregating information from multiple sources, including satellite imagery, social media updates, sensor networks, and ground reports.
This fusion of data allows emergency teams to assess damage zones, identify at-risk populations, and allocate resources efficiently. Real-time insights help responders make quick, informed decisions that could ultimately save lives and reduce damage.
Intelligent Customer Support
Customer service is being transformed by multimodal AI, enabling support systems to go beyond simple text chats. These systems can analyze a customer’s voice tone, facial cues, and message sentiment to understand mood and urgency more accurately.
This results in smarter chatbot interactions that feel more human. For example, a user could report a damaged product by speaking their complaint and uploading a photo. The AI processes both inputs, confirms the issue, and initiates a replacement, all without human intervention. This not only improves customer satisfaction but also reduces service costs and resolution time.
Conclusion
Artificial intelligence is no longer limited to understanding just words or recognizing images in isolation. With the rise of multimodal AI, machines can now process and connect different types of information all at once. This shift is changing how we interact with technology in everyday life. Whether it’s improving customer support, personalizing online shopping experiences, or enhancing security systems, multimodal AI makes these interactions feel more natural and human-like. But as we open the door to smarter, more intuitive machines, we must also step carefully.
Combining various data sources introduces new challenges, including the risk of bias, privacy issues, and the chance of misunderstanding complex inputs. In this blog, we’ll break down what multimodal AI is, how it works, where it’s being used, and why it’s important to approach its growth with both excitement and responsibility.

FAQs
What’s the difference between generative AI and multimodal AI?
Generative AI focuses on creating new content like text, images, or music. Meanwhile, multimodal AI deals with understanding and working across different types of data at the same time, such as combining text with images or audio. While generative models often work with a single data type (text-only or image-only), multimodal models blend multiple formats to produce more accurate and versatile outputs.
Is ChatGPT a multimodal AI?
Yes, ChatGPT has multimodal capabilities. Thanks to its GPT-4o model, it can now process and respond to a variety of input types, not just text, but also images and voice. You can upload pictures, speak your questions, and even get spoken answers back, making the interaction more dynamic and natural.
What does edge AI mean?
Edge AI refers to running AI directly on local devices like smartphones, sensors, or cameras without needing to send data back to a central server or cloud. This makes data processing faster, reduces internet bandwidth use, and keeps sensitive information more private.
What does multimodal mean in NLP?
In the context of natural language processing (NLP), multimodal refers to combining text with other types of input, like speech, images, or video, to improve how machines understand and generate language in context.
What are LLMs in AI?
LMMs, or Large Multimodal Models, are a key part of generative AI. They allow users to include different data formats, along with text, in their prompts, enabling the model to better understand the full context and provide more accurate results than models limited to just one type of input.


