

















 Copy Link
Copy Link Share on X
Share on X Share on Facebook
Share on Facebook Share on LinkedIn
Share on LinkedIn


Always Active
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Build intelligent AI systems that automate decisions, accelerate innovation, and scale business growth.
Design, build, modernize, and scale digital products that drive business growth.
Build secure, scalable, and intelligent platforms that power modern enterprises.
Build intelligent, connected, and autonomous systems that operate in the real world.
Flexible engineering capacity with predictable delivery, ownership, and outcomes.
Uncover the transformative potential of digital and mobile solutions for your industry

 Last Updated: May 4, 2026
Apr 7, 2026
Last Updated: May 4, 2026
Apr 7, 2026  607
607  26 min. Read
26 min. Read



Key Takeaways
Has your agentic AI deployment been live long enough to process real workflows, orchestrating tasks, and executing decisions around the clock?
The real question is: what did you actually get for the million dollars you invested?
If you do not have a clear answer, the problem is not the technology. It is the absence of measurement. And in enterprise AI, that becomes the most expensive silence.
According to research from IBM and Oracle, by 2027, business leaders expect AI agents to make twice as many independent decisions in business processes as they do today. McKinsey estimates that effective, scaled agentic AI deployments could deliver productivity improvements of three to five percent annually and lift growth by ten percent or more. Many organizations report ROI at a use-case level, yet struggle to translate that into enterprise-wide financial impact, largely due to fragmented pilots, weak data foundations, and the absence of any coherent measurement discipline.
The gap between what agentic AI promises and what enterprises actually capture is not a gap in capability. It is a gap in accountability. Organizations that close it are the ones that treat measurement as a design decision, not an afterthought.
This blog lays out a complete framework for measuring productivity gains from agentic AI deployments, one that speaks the language of the boardroom as clearly as it speaks to engineering and operations. By the time you reach the conclusion, you will have a named, repeatable model that your leadership team can table at the next quarterly review.

Most enterprises arrive at agentic AI carrying the measurement habits of every system that came before it. They track uptime, ticket resolution rates, API call volumes, and model response times. These are the right metrics for the wrong technology.
Agentic AI is fundamentally different from robotic process automation, from rule-based workflows, and from the generative AI assistants that preceded it. An agentic system does not respond to prompts. It reasons, plans, sequences tool use, self-corrects mid-execution, and pursues multi-step goals with limited human input. That is a different category of capability entirely, and it demands a different category of measurement.
Consider how enterprise measurement has evolved across three generations of automation:
| Generation | Technology | What Was Measured |
| First | RPA and Rule-Based Automation | Task throughput, cost per transaction, error rate |
| Second | Generative AI and Copilots | Prompt quality, user adoption rate, time saved per task |
| Third | Agentic AI | Workflow outcomes, decision quality, business impact, autonomy level |
Most organizations are using first-generation metrics to evaluate third-generation technology. The result is a persistent measurement illusion: dashboards full of activity data, and boardrooms full of unanswered questions about actual business value.
McKinsey’s analysis of leading agentic AI deployments found that organizations realizing meaningful impact have abandoned volume metrics entirely. Instead, they track conversation quality, task-completion accuracy, escalation precision, and what McKinsey calls learning velocity: how effectively agents incorporate feedback and adapt to changing conditions. These are outcome signals, not activity signals, and the distinction matters enormously for how agentic AI effectiveness gets evaluated across the enterprise.
The Core Principle
If a metric cannot be traced to a business outcome, it is instrumentation data. Instrumentation data tells you the system is running. It does not tell you where it is going.
Many organizations declare AI deployments successful well before any rigorous analysis has been completed. The claims are genuine. The measurement behind them often is not.
Three structural forces drive this gap between perception and reality.
Organizations that prioritize innovation tend to amplify early wins and quietly archive early AI failures. A pilot that improves one workflow by forty percent becomes a headline. The five workflows where the agent underperformed are filed under “learnings.” Culture is not the enemy of measurement, but unchecked, it becomes a distorting lens.
Investor and board reporting cycles create a structural incentive to surface positive AI stories. When there are no agreed standards for what a successful agentic AI deployment looks like, reporting becomes selective. The metrics chosen tend to be the ones that confirm the narrative rather than test it.
The enterprise AI industry has not yet converged on a common measurement vocabulary. What one organization calls a productivity gain, another treats as a baseline expectation. Without agreed-upon industry benchmarks, evaluation is subjective by default, and subjective evaluation almost always leans optimistic.
Self-Assessment: Five Signs Your AI Measurement Is Theater, Not Science
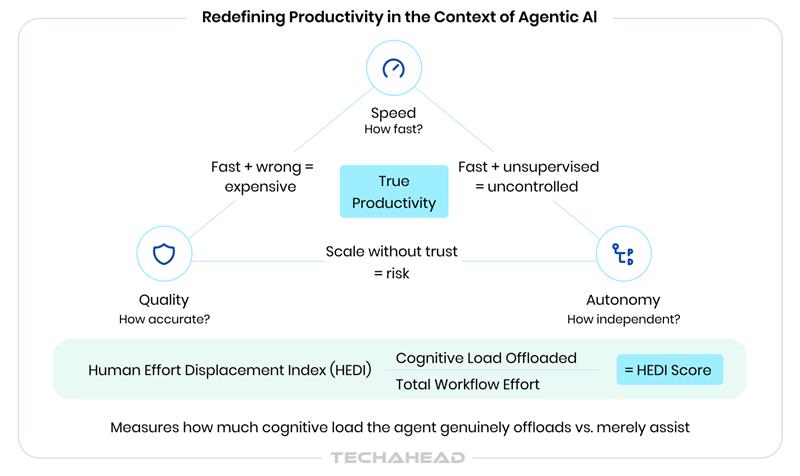
Before any framework can be applied, the term productivity needs to be redefined for the agentic context. Most enterprise leaders equate productivity with speed. Speed matters, but in isolation, it is a trap. A fast agent producing inaccurate outputs at scale is not productive. It is expensive.
Agentic AI productivity operates across three dimensions simultaneously, and the productive value of any deployment lives at the intersection of all three:
| Dimension | Definition | The Risk of Measuring It Alone |
| Speed | Task completion time versus documented human baseline | Fast plus wrong equals expensive at scale |
| Quality | Accuracy, compliance, and usability of outputs without rework | Quality without speed gains loses the efficiency argument |
| Autonomy | Percentage of tasks completed without human override or correction | High autonomy on low-value tasks is not a productivity win |
Fourth concept: Human Effort Displacement Index
A composite measure of how much human cognitive load, decision-making time, and manual effort an agent is genuinely offloading, as distinct from merely assisting. An agent that helps a human complete a task faster is an assistant. An agent that removes the human from the loop for an entire category of work is a productivity multiplier. These require different metrics and produce different ROI calculations.
Productivity from agentic AI must also be measured at three levels simultaneously, because progress at one level can mask failure at another.
Most organizations measure only at the task level and declare victory. The business outcome signal, which is the only signal the board actually cares about, lives one or two levels above where most enterprise AI measurement currently operates.
Google Cloud’s framework for evaluating production agentic AI systems makes a point that too few enterprises act on: for multi-step agentic workflows, you must evaluate the trajectory, the sequence of reasoning and tool calls, not just the final output. An agent that reaches the right answer through flawed reasoning is not a reliable agent. It got lucky.
Here is the complete technical metrics stack, organized into four categories. Each category targets a different layer of agent behavior, and all four are required for a complete picture of agentic AI performance.
| Metric | Definition | Target at Maturity |
| Task Completion Rate (TCR) | Percentage of tasks fully completed without human override | Above 85 percent |
| Task Success Rate (TSR) | Percentage of completed tasks meeting defined quality thresholds | Above 90 percent in production |
| Step Accuracy Rate | Percentage of individual steps in multi-step pipelines executed correctly | Above 95 percent |
| Retry and Fallback Rate | How often the agent loops back, fails mid-task, or triggers an exception | Below 10 percent |
| Plan Adherence | Whether the agent executed its planned sequence of tool calls in the correct order | Track deviation trend |
| Metric | Definition |
| Average Task Duration | Time per task measured against the documented human baseline for that process |
| Throughput Rate | Number of tasks handled per hour or per day at production scale |
| End-to-End Latency | Total time from task initiation to final resolution across the full agent trace |
| Pipeline Completion Rate | End-to-end workflow success rate across multi-agent orchestration sequences |
| Planning Efficiency | Whether the agent minimizes unnecessary reasoning steps by using tools effectively |
These are the metrics that matter most to enterprise risk and compliance functions, and the ones most commonly absent from early-stage AI dashboards.
| Metric | Definition | What to Watch |
| Human Override Rate | How often humans correct or take over agent actions | Track the trend downward. A sudden spike signals a regression. |
| Agent Escalation Rate | How often tasks are routed to human queues | Should decline as the agent matures and learns |
| Argument Hallucination Rate | How often the agent invents parameters for a function call, it does not have context for | Critical in financial and regulated environments |
| Error Severity Index | Frequency multiplied by the downstream business cost of errors | A few high-severity errors can erase all efficiency gains |
| Consistency Score | Given the same input ten times, how much does the agent’s tool usage path vary? | High variance indicates reasoning instability |
| Metric | Definition |
| Trace Coverage | Percentage of agent actions that are fully logged and inspectable at the step level |
| Mean Time to Detect (MTTD) | How quickly anomalous or underperforming agent behavior is identified |
| Audit Trail Completeness | Percentage of autonomous decisions with a full reasoning chain logged, critical in regulated industries |
| Learning Velocity | How quickly the agent measurably improves after feedback, retraining, or recalibration |
Learning Velocity is the metric most organizations forget. It is also the one that separates agents that compound in value from agents that plateau at their initial deployment performance.

Technical metrics are the foundation. Business KPIs are the building blocks. The two must be connected by design, not assembled after the fact. What follows is a role-differentiated view of the business KPIs that enterprise AI programs should be producing, organized by the executive audience that acts on each one.
Is your organization ready for AI adoption? Read our blog on AI Readiness Assessment to find out.
Frameworks earn their place when they do something lists cannot: they create sequence. They force an organization to do things in the right order, which is rarely the order that feels most natural. The PACE Framework is a four-stage model for measuring productivity gains from agentic AI deployments that works for a startup deploying its first agent and for an enterprise managing a portfolio of fifty. Unlike traditional ROI models, PACE separates autonomy from cost impact, which is critical for agentic systems.
PACE stands for Performance Baseline, Autonomy Measurement, Cost-Impact Calculation, and Evolution Tracking. Each stage builds on the one before it, and none can be skipped without compromising the integrity of what follows.
Nothing in the PACE Framework works without this stage, and this stage must happen before deployment begins. Document the current state of every process the agent will touch with precision:
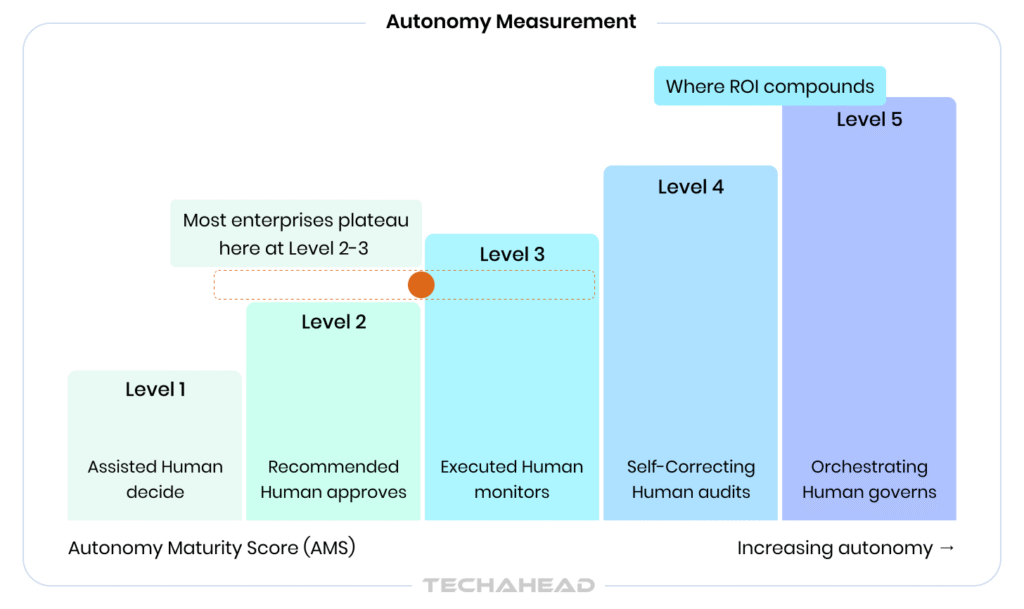
The first thirty to ninety days of a deployment are the autonomy measurement phase. The central question is not whether the agent is performing tasks. It is how genuinely autonomous that performance is. The Autonomy Maturity Score (AMS) provides a structured answer on a five-level scale:
| AMS Level | Description | Human Role |
| Level 1 — Assisted | Agent provides suggestions; human makes all decisions | Decides |
| Level 2 — Recommended | Agent recommends actions with rationale; human approves | Approves |
| Level 3 — Executed | Agent executes tasks; human monitors and can intervene | Monitors |
| Level 4 — Self-Correcting | Agent executes and corrects its own errors; human audits periodically | Audits |
| Level 5 — Orchestrating | Agent coordinates other agents; human governs the system | Governs |
Track the AMS at thirty, sixty, and ninety days. The trajectory is more informative than the point-in-time score. An agent that moves from Level 2 to Level 4 in ninety days is scaling correctly. An agent that stays at Level 2 after three months has an adoption or capability problem that needs diagnosis before the Cost-Impact Calculation will mean anything.
Starting at month three, with sufficient data volume and a clear autonomy trajectory, the Cost-Impact Calculation becomes meaningful. Two formulas anchor this stage.
Productivity Gain Formula
Productivity Gain (%) = [(Human Baseline Output Cost − AI-Augmented Output Cost) divided by Human Baseline Cost] x 100.
AI ROI Formula
AI ROI (%) = [(Total Business Value Gained − Total AI Investment Cost) divided by Total AI Investment Cost] x 100
The PACE Framework is a continuous discipline. Quarterly evolution tracking answers three questions that determine the future investment case for every deployed agent:
Evolution Tracking turns agentic AI from a project into a program. It shifts the organizational posture from “did this work?” to “how do we make this work better and where do we expand next?” That shift is what separates enterprises that build durable AI capability from those that cycle through expensive pilots indefinitely.
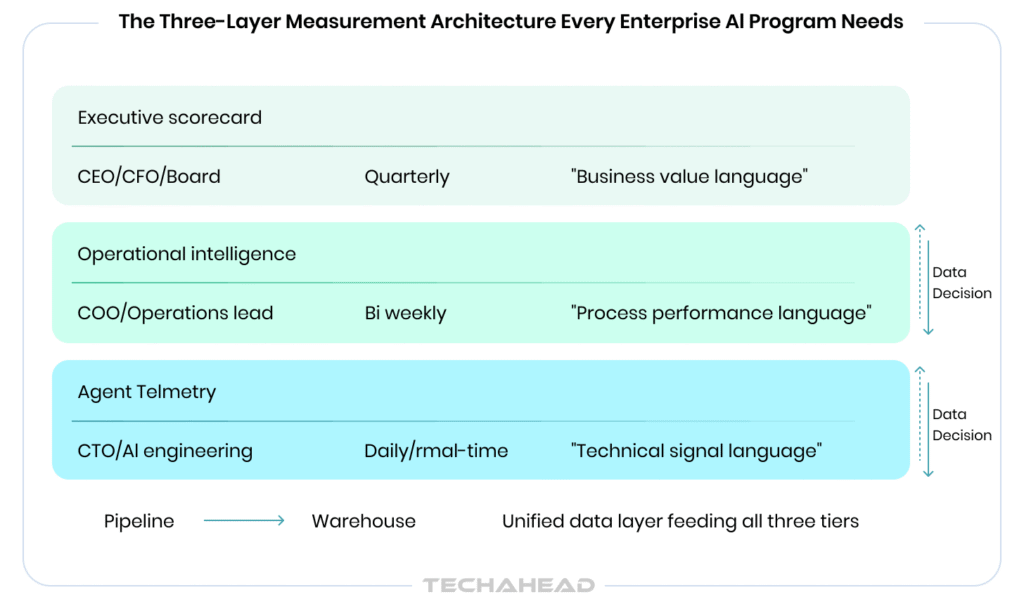
The metrics exist. The formulas exist. What many organizations are missing is the AI infrastructure to collect, aggregate, and surface this information to the right people in the right format at the right cadence. The solution is a three-layer measurement architecture that mirrors the organizational levels it serves.
Raw operational data: logs, traces, token usage, latency, step-by-step execution records, error events, and tool call sequences. This layer captures what the agent actually did, in granular detail, at every step. LLM observability platforms handle this layer. The primary audience is the AI engineering team and ML operations function. Review cadence: continuous, with automated alerting on anomaly thresholds.
Aggregated KPIs derived from the telemetry layer: Task Completion Rate trends, SLA status, throughput curves, override rate patterns, and pipeline health scores. This layer answers the question: is the deployment performing as expected across the operational environment? BI integration tools connect agent logs to operational dashboards.
Distilled business outcomes: ROI tracking against baseline, cost avoidance realized, FTE equivalent output delivered, PACE Framework progress score, and portfolio-level AI health across all agents. This layer speaks the language of the boardroom.
These are the patterns that appear consistently across agentic AI programs that fail to demonstrate value. Some are technical. Most are organizational. All of them are avoidable with a structured approach.
The measurement discipline described in this framework does not need to be built all at once. It needs to be built in the right sequence. Here is a phased roadmap that applies to organizations at any stage of their agentic AI journey.
Deliverable: An AI Measurement Charter. A single-page internal document that defines what success looks like, how it will be measured, and who owns each metric, is agreed upon before go-live.
Deliverable: A 30-Day Agent Performance Report covering technical metrics, early AMS progression, and the first business signal.
Deliverable: A Quarterly AI ROI Report in boardroom-ready format, tracking the PACE Framework through all four stages.
Deliverable: An Annual AI Maturity and ROI Assessment that feeds directly into the capital allocation decision for the following year’s AI investment.
Use this checklist before any agentic AI deployment to assess measurement readiness. If more than two items are unchecked, the deployment plan is incomplete.
Readiness Questions:
The organizations pulling ahead in the agentic AI era share a common discipline. They did not start with the most sophisticated agents. They started with the clearest measurement frameworks. They knew what success looked like before they deployed, they instrumented to capture it from day one, and thus, collaborated with an experienced Agentic AI company that built the governance structures to drive trustworthy results.
Measuring productivity gains from agentic AI deployments is not a technical challenge. It is an organizational one. It requires engineering, operations, and finance to share a vocabulary. It requires leadership to treat measurement as a pre-deployment decision rather than a post-deployment rationalization. And it requires the intellectual honesty to report on what the agents are actually delivering, not what the investment case projected they would deliver.
Enterprise AI success metrics are not a reporting exercise. They are a management system. The companies that build it correctly will not just be able to answer the question in board meetings. They will be able to answer the more important question that follows: where should we expand next, and what will it return?

The AI measurement view should sit at three levels: strategic adoption, business velocity, and financial return. Specifically: AI Adoption Rate (percentage of target workflows live versus the roadmap commitment), Decision Velocity (how much faster the organization moves from data signal to action after deployment), Employee Productivity Lift (output per employee in AI-augmented teams versus matched non-augmented teams), and the AI Maturity Score (where the program sits on a defined capability scale for competitive benchmarking).
ROI calculation for agentic AI requires two inputs that most organizations get wrong: a complete cost picture and a pre-deployment baseline. The formula is straightforward: Total Business Value Gained minus Total AI Investment Cost, divided by Total AI Investment Cost, multiplied by 100. The errors happen on both sides of that equation. Total AI Investment Cost must include licensing, compute, integration, maintenance, reskilling, and change management. Total Business Value must include labor cost avoided, error cost reduced, revenue accelerated, and compliance cost avoided.
There is no universal benchmark because task completion rate depends heavily on the complexity of the workflow and the maturity of the deployment. As a general reference point, well-configured production agents in operations-heavy workflows typically reach above 85% task completion at maturity, with task success rates. The more useful question is not what the rate is at a single point in time, but whether it is improving. Google Cloud’s production framework identifies plan adherence and argument hallucination rate as the two metrics that surface agent problems fastest track both alongside completion rate from day one. A declining completion rate after an initial high is a reliability signal. A completion rate that is high but paired with a high human override rate means the agent is completing tasks that humans are then correcting, which is a quality problem disguised as a completion success.
AI productivity metrics live at the technical and operational layer: task completion rates, latency, throughput, override rates, and learning velocity. They tell engineering and operations teams whether the agent is functioning correctly and improving over time. AI business KPIs live at the outcome layer: FTE equivalent output, cost per task, revenue impact attribution, decision velocity, and SLA adherence. They tell the organizations whether the AI program is delivering value. The critical error most enterprises make is treating these as two separate conversations. The organizations that struggle most with AI measurement are those that try to show the board everything instead of translating operational metrics into five to eight strategic indicators that inform decisions. Every technical metric needs a named business owner who translates it into a business decision; that translation layer is what separates a measurement program from a reporting exercise.
An agent is ready to scale when it has demonstrated four things simultaneously over a sustained period: a Task Completion Rate consistently above 85 percent, a Human Override Rate that has declined to below 10 percent and is stable, a positive Learning Velocity trajectory (still improving, not plateauing), and a positive ROI calculation that includes all cost categories. In Autonomy Maturity Score terms, an agent at Level 3 or above has earned the confidence required for expansion. The pattern that consistently works in enterprise agentic AI adoption is to take one high-value use case to full production first, validate the measurement framework, then scale to additional workflows once multi-user authorization and governance are proven. Scaling an agent that has not yet earned its ROI case in a single workflow simply distributes the measurement gap across a larger surface area.
We use cookies to ensure our website functions properly, improve performance, and provide a personalized experience. You can choose which types of cookies to allow below.
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Help us understand site traffic and user interactions so we can improve performance and usability.
Enable enhanced functionality and personalization such as language or region preferences.
Used to deliver relevant ads, track campaign performance, and measure advertising effectiveness.