
Staff Augmentation
Access top-tier talent on demand: Dedicated, Hourly, or Flexible.

























 Copy Link
Copy Link Share on X
Share on X Share on Facebook
Share on Facebook Share on LinkedIn
Share on LinkedIn
“If you buy my entire argument that we’ve got a new commodity—it’s tokens—and the job of every economy and every firm in the economy is to translate these tokens into economic growth, then if you have a cheaper commodity, it’s better.” – Satya Nadella (CEO, Microsoft)
AI agents are no longer a pilot project, they are production infrastructure. 79% of enterprises have already adopted AI agents, with 88% planning to increase AI-related budgets in the next 12 months, according to PwC’s 2025 survey. Yet the costs are spiraling fast. Enterprise AI agent deployments already range from $50,000 to $200,000 on average and that is before runaway loops, token spirals, and redundant calls quietly compound your monthly bill.
The global agentic AI market is projected to grow from $5.2 billion in 2024 to $196.6 billion by 2034. The investment is accelerating. However, without a cost framework, scaling agents means scaling losses.
This blog breaks down exactly why enterprise agent costs explode, and the framework to cap them.
Key Takeaways
- AI agent costs compound across multiple hidden layers.
- Token spirals turn single calls into dozens through context and replanning.
- Bloated system prompts waste millions of tokens daily.
- Track tokens, tool calls, iterations for workflow cost baselines.
- Cap workflow totals to prevent budget overruns.
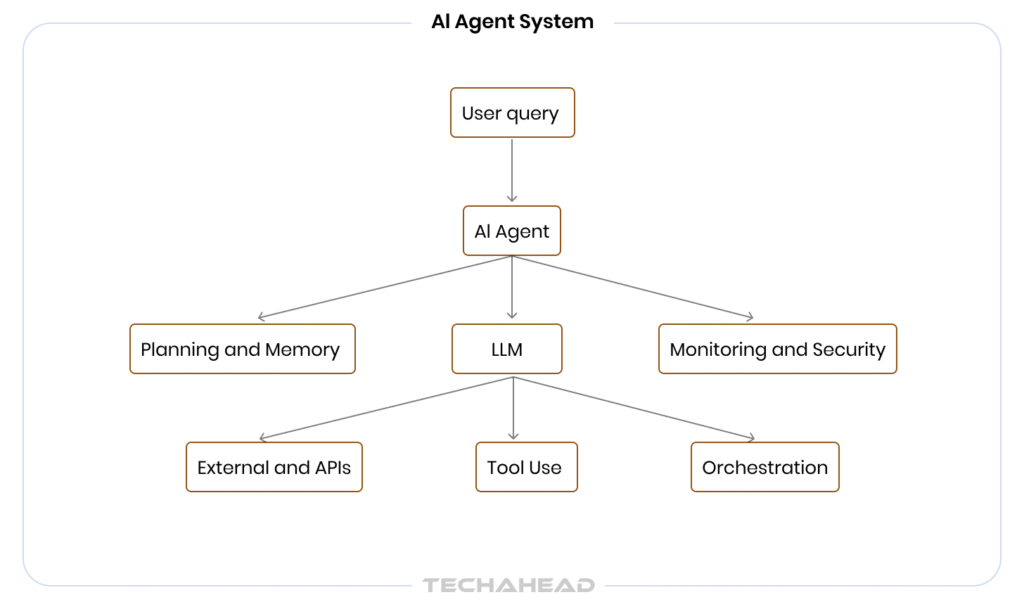
What are AI Agent Costs Made Of?
AI agent costs are not a single line item; they are a stack of compounding charges that catch most enterprises unprepared.
At the core, token consumption drives the largest share. Every input prompt, retrieved document, tool output, and model response burns tokens. For GPT-4o, that runs $2.50 per million input tokens and $10 per million output tokens; agents generate far more output than a simple chatbot.
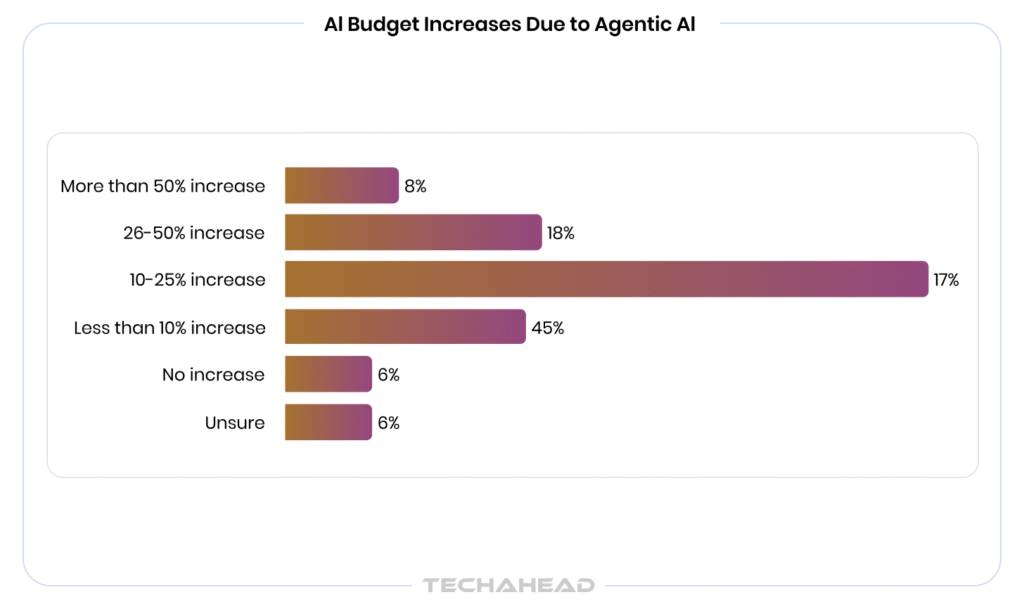
Source: PwC
Beyond tokens, costs break down into four layers:
- Compute costs: model inference per API call
- Orchestration overhead: agent loop iterations, retries, and re-planning cycles
- Tool execution costs: database queries, web searches, and third-party API calls
- Memory and storage: vector database reads/writes for retrieval-augmented agents
As of March 2026, GPT-4o pricing remains stable at $2.50 per 1M input and $10.00 per 1M output. However, most enterprise agents now utilize Prompt Caching, which cuts the cost of repeating context (like system prompts or RAG documents) by 50% ($1.25 per 1M). A single enterprise workflow running 10,000 agent tasks daily can silently accumulate $25k monthly before any optimization is applied.
So, understanding this stack is the first step to controlling it.
The “Token Spiral” Problem: How One Agent Call Becomes Thousands?
For example, you trigger one agent task. Simple enough, right?
However, that agent needs context, so it pulls memory. Then it calls a tool. That tool returns a long output, which gets fed back into the prompt. The agent is not sure, so it re-plans. Then call another tool. Then summarizes. Then verifies. What started as one API call is now 47!
This is the token spiral; and it is the #1 reason enterprise AI bills look nothing like early estimates.
The worst part? It happens silently, at scale, across hundreds of concurrent workflows. And by the time you notice, the damage is done.

Runaway Loops, Redundant Calls, and Other Silent Budget Killers
Not all cost problems announce themselves. These three failure patterns operate invisibly, quietly multiplying your token consumption while your traditional monitoring dashboards show “Green.”
Runaway Loops: When Agents Cannot Stop Themselves
Agents are designed to retry until they succeed. However, when they hit an ambiguous instruction, an unclear tool response, or a failing API, they loop. One agent stuck in a retry cycle can rack up thousands of API calls in minutes. Without a hard iteration cap, there is no ceiling on what it spends.
Redundant Calls: Paying for the Same Answer Twice
Most enterprise agent systems have no memory of what was already fetched. So when two parallel agents need the same data, they both go and get it independently. At scale, it means you are paying for duplicate retrievals, duplicate model inferences, and duplicate tool executions constantly.
Context Bloat: The Cost Nobody Tracks
Every time an agent passes information to the next step, the context window grows. Old tool outputs, previous reasoning traces, and retrieved documents all accumulate. Agents end up processing thousands of tokens of irrelevant history just to answer a simple follow-up question.
Why Do These Go Undetected?
None of these show up as errors. Your system logs report success. Your dashboards show healthy uptime. Meanwhile, your bill doubles every two weeks, and nobody knows why.
How Poor Prompt Design Multiplies Your Costs at Scale?
Most enterprises underestimate how much a badly written prompt costs them.
A vague instruction forces the agent to ask clarifying questions, re-plan, or attempt multiple approaches before landing on the right answer.
Every one of those attempts burns tokens.
Bloated system prompts are equally damaging. Stuffing 2,000 tokens of unnecessary context into every single call across 50,000 daily tasks adds millions of wasted tokens to your monthly bill.
Poor output formatting instructions are another silent killer. When agents return unstructured responses, downstream systems fail to parse them, triggering costly re-runs. So, good prompt design is not a quality concern. It is a direct cost control method.
A Framework for Sustainable AI Agent Budgeting at Scale
Controlling AI agent costs long-term requires more than spend alerts. It requires a structured budgeting framework built into your architecture from day one.
1. Set Cost Baselines Per Workflow
Before you can cap costs, you need to know what “normal” looks like. Instrument every agent workflow to track:
- Tokens consumed per task (input + output separately)
- Number of tool calls per agent run
- Average iterations per completion
- Cost-per-outcome, not just cost-per-call
It gives you a cost fingerprint for each workflow, which makes anomalies immediately visible.
2. Tier Your Model Usage by Task Complexity
Not every task needs your most expensive model. Build a routing layer that assigns models based on complexity:
- Simple classification or extraction → GPT-4o Mini, Claude Haiku (~10x cheaper)
- Multi-step reasoning tasks → GPT-4o, Claude Sonnet
- Crucial, high-stakes decisions only → GPT-5.2/5.4 and Claude 4.6 (Opus)
A well-implemented routing layer alone can cut inference costs by 40–60% without any drop in output quality.

3. Enforce Hard Budget Guardrails at Three Levels
To prevent “Denial of Wallet” scenarios, your architecture must enforce limits at every layer of the execution stack.
Task Level
Set a maximum token budget per agent run. If the agent exceeds it, terminate and return a partial result rather than continuing indefinitely.
Workflow Level
Cap total spend per workflow execution. A pipeline should never cost more than a predefined ceiling regardless of complexity.
Organizational Level
Allocate monthly token budgets per team or product line (Chargeback Tags). Treat AI compute like cloud infrastructure with ownership and accountability.
4. Build a Continuous Optimization Loop
Budgeting is not a one-time exercise. Schedule monthly reviews to:
- Identify the top 5 most expensive workflows
- Audit prompt bloat and redundant tool calls
- Renegotiate model tiers as task patterns evolve
Enterprises that treat AI budgeting as an ongoing discipline, not a launch checklist consistently reduce costs by 20–35% quarter over quarter.
Conclusion
AI agents are powerful, but without the right cost architecture, they become expensive liabilities fast. Token spirals, runaway loops, poor prompt design, and over-provisioned models do not just inflate your bill. They quietly erode the ROI that justified your AI investment in the first place. With the right framework, you can build cost-disciplined agents. Are you ready to build AI agents that scale without breaking your budget? TechAhead specializes in AI agent development services, designed for performance. With the right architecture, you can cut agent costs up to 60% while improving output quality. That is not optimization, that is reclaiming what your investment was always supposed to deliver.

Why are my AI agent costs so much higher than my initial API cost estimates?
Initial estimates usually account for single API calls. Real agent costs compound every retry, tool call, memory retrieval, and re-planning cycle adds tokens. Enterprises routinely see 10–30x more token consumption than their baseline projections.
Is it worth investing in prompt optimization purely for cost reasons?
Absolutely. A single poorly structured system prompt deployed across 50,000 daily tasks can waste millions of tokens monthly. Prompt optimization consistently delivers 20–40% cost reductions with no impact on output quality.
Do we need the most powerful model for every agent task?
No, and this is one of the most expensive mistakes enterprises make. Simple extraction, classification, and formatting tasks perform equally well on smaller models like Claude Haiku or GPT-4o Mini at a fraction of the cost.
What is the single biggest cost-saving change an enterprise can make immediately?
Implement a token budget cap at the task level. Setting a hard ceiling on how many tokens any single agent run can consume and terminating gracefully when hit. It is the fastest way to eliminate runaway costs with minimal engineering effort.