

















 Copy Link
Copy Link Share on X
Share on X Share on Facebook
Share on Facebook Share on LinkedIn
Share on LinkedIn


Always Active
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Build intelligent AI systems that automate decisions, accelerate innovation, and scale business growth.
Design, build, modernize, and scale digital products that drive business growth.
Build secure, scalable, and intelligent platforms that power modern enterprises.
Build intelligent, connected, and autonomous systems that operate in the real world.
Flexible engineering capacity with predictable delivery, ownership, and outcomes.
Uncover the transformative potential of digital and mobile solutions for your industry

 Last Updated: Jun 4, 2026
Jun 4, 2026
Last Updated: Jun 4, 2026
Jun 4, 2026  283
283  16 min. Read
16 min. Read



Key Takeaways
Users sign up, engage briefly, and quietly disappear. The average education app retains less than 4% of users after 30 days. Duolingo does not have that problem. Duolingo closed 2025 with 52.7 million daily active users; record highs for the platform. That is not a marketing win. It is an engineering one. Behind every personalised lesson, every well-timed reminder, and every streak-saving nudge is a machine learning infrastructure that makes over a billion individualised decisions every single day. No two users get the same experience. No lesson is served without the system first calculating what you know, what you are about to forget, and what will keep you engaged for one more session. This blog breaks down exactly how that system works: the algorithms, the architecture, and the decisions behind it. More importantly, it surfaces what enterprise product teams can learn from it and apply to their own ML pipelines.
Language learning has one of the highest dropout rates in digital education. Education apps face retention rates as low as 2.2% across the category. Early in Duolingo’s history, it was no different. The core problem is simple: every learner is different.
Manual curation cannot solve this at scale but writing personalized lesson plans for over 100 million active monthly learners across 40+ languages is humanly impossible. So here ML pipelines come in. Instead of building one course for everyone, Duolingo builds a system that continuously adapts; adjusting difficulty, timing, and content for each individual user automatically and asynchronously between learning sessions. That shift, from static courses to intelligent pipelines, is what separates Duolingo from every competitor.

Most enterprise applications collect logs; Duolingo harvests behavioral intelligence. Every complete session, incorrect tap, and paused exercise is fed directly back into the ML pipelines that shape what a user sees next. With over 100 million monthly active learners, this feedback loop generates a proprietary data moat that no academic research lab can replicate.
With more than over 100 million active monthly learners, Duolingo has the world’s largest collection of language-learning data at its fingertips. However, the real advantage is not the volume; it is the granularity. For each user-word interaction, Duolingo captures:
Every trace captures a particular exchange between a user and a word, including results, response times, and the amount of time that has passed since the user last saw that word.
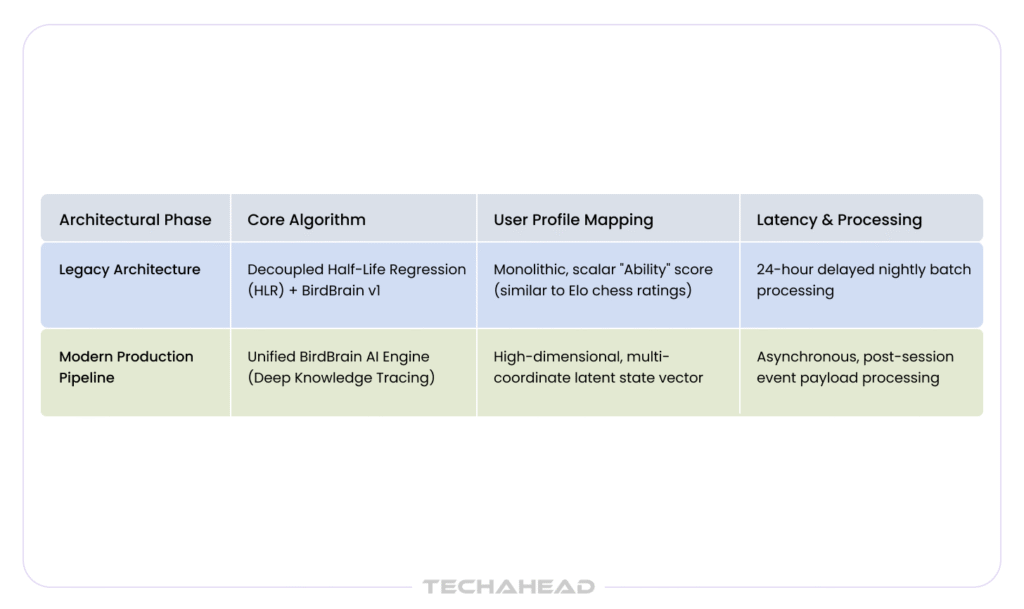
One of the more counterintuitive engineering decisions Duolingo made was to treat incomplete sessions as valuable data. Roughly 20% of lessons started on Duolingo are not completed, and Duolingo was pretty sure that people were not quitting at random.
In many cases, they likely quit once they hit material that was especially challenging or daunting. So when Birdbrain v2 scaled, Duolingo moved away from rigid 24-hour nightly batch processing. Instead, the architecture processes post-session payloads asynchronously within minutes, turning even an incomplete or abandoned session payload into an immediate tracking signal.
Built using the PyTorch framework on AWS, Duolingo’s pipeline executes tens of billions of inference predictions every single day. Depending on the complexity of the task, individual models are trained on slices ranging from 100,000 to over 30 million data points.
By orchestrating their data pipeline via high-performance cloud clusters, utilizing Amazon S3 as an immutable data lake, and utilizing Apache Spark for continuous batch processing, Duolingo successfully runs a closed-loop data flywheel.
This is the data flywheel in practice: more users generate more data, better data trains better models, better models improve the experience, and a better experience brings more users. At Duolingo’s scale, that loop compounds daily.
The science of forgetting is not new. In 1885, psychologist Hermann Ebbinghaus established that memory decays exponentially after learning; fast at first, then slowing over time. Conventional spaced repetition techniques, such as the Leitner box system, depended on predetermined intervals; review after one day, then three days, then seven days.
The flaw is obvious: a fixed schedule treats every learner and every word the same. A native Spanish speaker learning French forgets “bonjour” at a completely different rate than an English speaker learning Mandarin. Static rules cannot capture that.
HLR is a model for spaced repetition that combines psycholinguistic theory with modern machine learning techniques, indirectly estimating the “half-life” of words in a student’s long-term memory. The half-life of a word is the point at which a learner has a 50% chance of forgetting it. HLR’s job is to calculate that moment precisely, and schedule a review just before it arrives. The model factors in several variables for every word, for every user:
Compared to the conventional Leitner system, the HLR model decreased the error in predicting student recall by more than 45%. In a large-scale A/B test, users served by the HLR algorithm showed a 12% increase in daily engagement. The dataset used to develop and validate HLR contained 13 million Duolingo student learning traces.
It is important to understand what HLR does not do. It does not decide which exercise you practice next. While Duolingo originally ran HLR to calculate the ‘when’ and a separate system to handle the ‘what’, modern iterations of BirdBrain have completely unified these pipelines. Today, BirdBrain runs a single, consolidated deep learning model that predicts both vocabulary half-life and structural content selection at the exact same time.
If HLR answers when to show you a word, Birdbrain answers what to show you next. Birdbrain is continuously improving the learner’s experience with algorithms based on decades of research in educational psychology, combined with recent advances in machine learning.
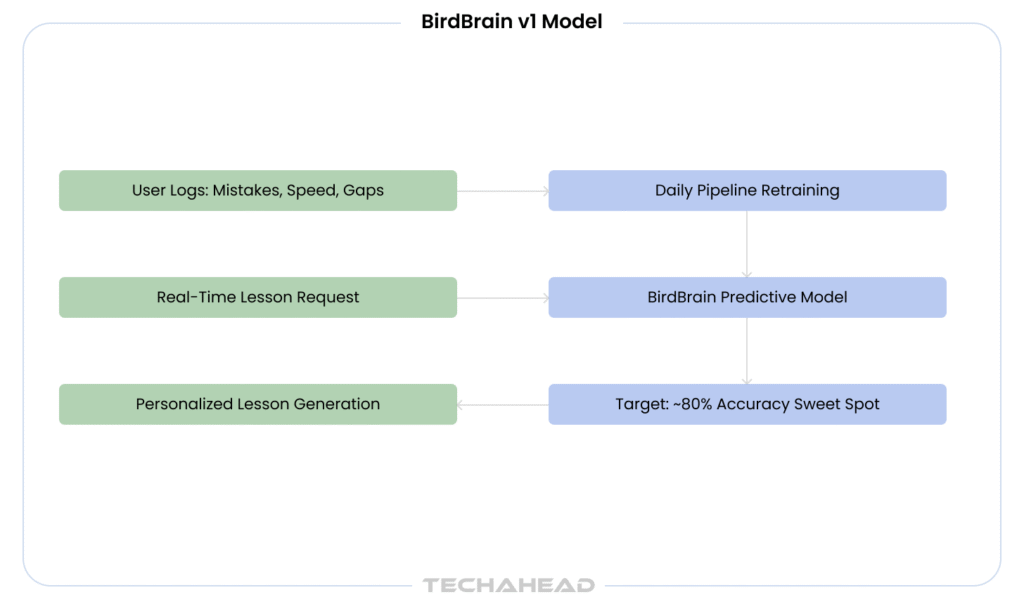
The original Birdbrain tracked two values per user: an ability score and a difficulty score for each exercise. The logic mirrored how chess rankings work:
When a learner gets an exercise wrong, the system lowers the estimate of their ability and raises the estimate of the exercise’s difficulty. The reverse happens when a learner answers correctly.
If a beginner learner gets a hard exercise correct, the ability and difficulty parameters can shift dramatically. However, if the model already expects the learner to be correct, neither parameter changes much. Surprising outcomes carry more information, and the model weights them accordingly.

The jump from V1 to V2 replaced a simple score with a full learner profile. Birdbrain V2 is backed by a recurrent neural network model, specifically an LSTM, which learns to compress a learner’s entire history of interactions into a set of 40 numbers.
Every time a learner completes another exercise, Birdbrain updates this vector based on its prior state, the exercise completed, and whether they got it right. The model is never static; it evolves with every single tap.
This is where V2 pulls far ahead of V1. The richness of this representation allows the system to capture, for example, that a given learner is great with past-tense exercises but is struggling with the future tense. A single ability score could never surface that distinction.
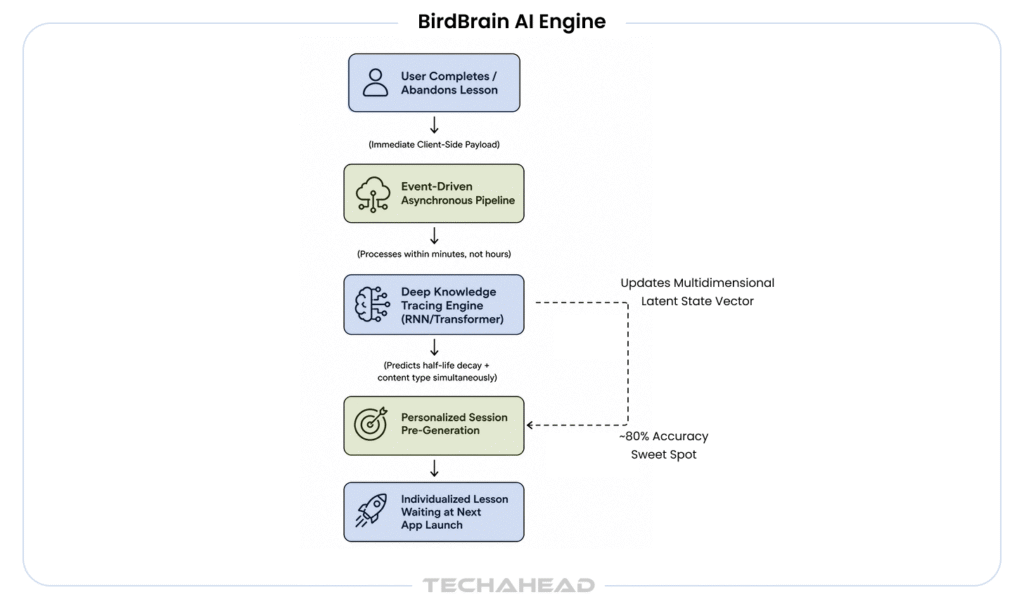
Duolingo processes 1 billion exercises every single day; each one fed through Birdbrain, which in 14 milliseconds decides what a specific user should see next, based on their exact history of right answers, wrong answers, hesitations, and time gaps between sessions.
That is not a generalised recommendation. It is an individual decision, made for every learner, on every exercise. No human curriculum designer could ever replicate.
For years, Duolingo could tell you that your answer was wrong. What it could not do was explain why, or let you practise a real conversation. Duolingo turned to OpenAI’s GPT Models to fill these gaps with two new features: Roleplay, an AI conversation partner, and Explain My Answer, which breaks down the rules when you make a mistake. These are packaged into a new subscription tier called Duolingo Max.
Previously, a missed answer gave learners nothing to work with beyond the correct solution. The Explain My Answer feature gives users the chance to learn more about their response in a lesson, whether their answer was correct or incorrect; tapping a button after certain exercises opens a chat with Duo to get an explanation on why their answer was right or wrong.
Static exercises cannot replicate the pressure of an actual conversation. The Roleplay feature guides users through different scenarios such as ordering coffee at a café in Paris, or discussing future vacation plans with an AI that is both responsive and interactive. After the conversation, users receive AI-powered feedback on the accuracy and complexity of their responses, along with tips for future conversations.
GPT-4 does not operate without guardrails; human experts write the scenarios that users see in Roleplay, make sure the initial prompt is aligned with where the user is in their course, write the initial message in the chat, and tell the AI model where to take the conversation. The LLM handles the dynamic generation.
Indeed, behind every well-timed reminder is a machine learning system making a real-time decision about what to say, and when.
When sending practice reminders, it used to be that notifications were selected from the pool at random. Duolingo wondered if they could help more learners stay motivated by making the algorithm smarter; finding the best notification to send to each user each day.
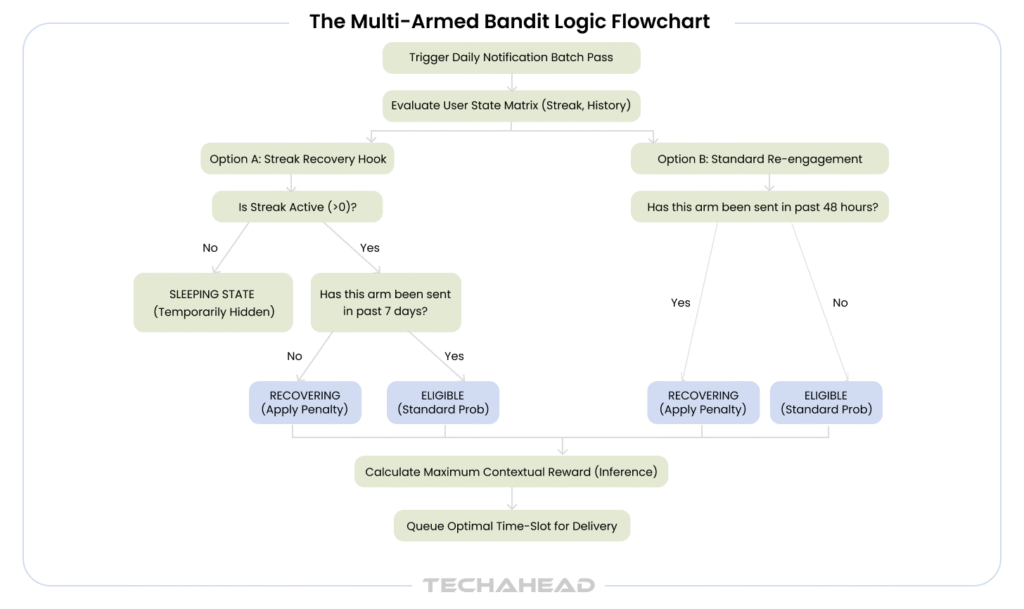
Standard bandit algorithms assume every option is available to every user at all times. Duolingo’s situation is more complex.
As a result, each user effectively receives a personalized notification strategy based on historical response patterns, content preferences, current streak status, and platform behaviour.
Duolingo did not build a perfect ML system on day one. They built one that could be measured, challenged, and improved continuously. These seven decisions explain how:
Most teams log completed sessions. Duolingo logs everything. Roughly 20% of lessons started on Duolingo are not completed, and Duolingo was pretty sure that people were not quitting at random.
In many cases, they likely quit once they hit material that was especially challenging. So Birdbrain v2 began streaming data throughout the lesson in chunks, rather than waiting for completion. An abandoned session is not wasted data. It is one of the clearest signals that something was too hard.
Early in its optimization path, Duolingo split its infrastructure; running HLR for timing and BirdBrain for content type. However, managing disparate pipelines for millions of concurrent users introduced significant sync friction and compute overhead.
The ultimate engineering win came when Duolingo absorbed the spaced-repetition memory decay tracking directly into a unified BirdBrain neural network.
For enterprise leaders, the lesson is clear: start with modular components, but consolidate interdependent pipelines as you scale to dramatically reduce backend complexity.

Personalisation is useless if it is too slow to serve. By rewriting their Session Generator in Scala, Duolingo reduced lesson generation latency from 750ms to 14ms. That is a 98% reduction.
Degraded performance also dropped from around two hours per quarter to zero downtime in the months following the rewrite. Speed and stability improved together. Latency belongs on the same priority list as model accuracy.
More data does not always mean better models. We will use a sliding window because just two weeks of data is plenty given the number of users, tests, and languages to train our models. Recent behaviour is more predictive of current learning state than data from months ago. Training on less, more relevant data also keeps compute costs manageable and retraining cycles fast.
Early in its lifecycle, Duolingo used a third-party tool to manage experiments. Eventually, the expense became too great and they reached the limits of what the tool could support. Testing was so core to the business that they needed to run the infrastructure in-house.
On a given week, it is not uncommon for Duolingo to have a few hundred experiments running simultaneously, from updating a single button to rolling out a major feature like Leaderboards. That volume requires infrastructure you control entirely.
Duolingo relies on data from A/B tests to make informed decisions, with three key principles guiding their testing: learners first, test everything, and prioritise ruthlessly.
Through countless iterations, A/B testing, and a bandit algorithm, the team generated dozens of small and medium-size wins that amounted to substantial gains in DAU year after year. No single test moved the needle dramatically. The discipline of running hundreds of them did.
Duolingo is committed to sharing publications and data with the broader research community; it allows them to uncover new insights and apply existing theories. Open-sourcing their HLR dataset and publishing their bandit algorithm paper attracts research talent, surfaces external improvements to their models, and builds credibility that compounds into a long-term hiring and partnership advantage. At Duolingo’s scale, transparency is not generosity. It is a strategy.
Duolingo’s story is not really about language learning. It is about what happens when an engineering team treats personalisation as an infrastructure problem, not a feature.
The data flywheel, the two-model architecture, the 98% latency reduction, the hundreds of concurrent experiments; none of these happened by accident. They were deliberate, compounding decisions made over a decade of iteration. The result is a system that handles tens of billions of daily automated inference predictions at a cost and speed no human tutor could match.
The question for your team is not whether ML pipelines like this are possible. They clearly are. The question is whether you have the architecture, the experimentation culture, and the engineering foundation to build one.
That is exactly where TechAhead comes in. As an AWS Advanced Tier Partner and official OpenAI Services Partner, with 16+ years of experience in scalable AI and ML systems and education app development. We help product teams move from idea to production-ready pipeline without the trial and error.
Ready to build an ML-powered product that gets smarter with every user interaction? Our team of AI & ML engineers has helped 1,200+ global brands turn user data into intelligent, personalised product experiences. Let’s build yours.

A data flywheel is a self-reinforcing loop where more users generate more data, better data trains better models, and better models attract more users. Abandoned sessions are especially valuable; they signal exactly where users struggled, giving the model precise difficulty signals that completed sessions alone can never provide.
It depends on complexity and scale. A foundational personalisation pipeline starts at $75,000-$150,000 for mid-sized products, scaling into six or seven figures for real-time, multi-model architectures. The more important cost question is not what it costs to build it right; it is what churn and lost engagement cost when you do not.
Most enterprise teams see early engagement signals: improved retention, session length, and reduced churn within three to six months of deployment. Meaningful revenue impact follows within twelve months, as the model accumulates enough behavioural data to make consistently accurate predictions. The flywheel compounds significantly after the first year.
Start with behaviours directly tied to your core retention metric. Track session completion, drop-off points, and response accuracy before anything else. These three signals tell you what is working, what is losing users, and where difficulty is misaligned; giving your first model enough signal to make meaningful personalisation decisions immediately.
Yes. Most mature products can adopt ML personalisation incrementally, starting with a recommendation layer or notification optimisation engine that sits alongside existing infrastructure. A full rebuild is rarely necessary. What matters is clean behavioural data, clear retention metrics, and an API-accessible architecture. TechAhead specialises in exactly this kind of phased ML integration.
We use cookies to ensure our website functions properly, improve performance, and provide a personalized experience. You can choose which types of cookies to allow below.
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Help us understand site traffic and user interactions so we can improve performance and usability.
Enable enhanced functionality and personalization such as language or region preferences.
Used to deliver relevant ads, track campaign performance, and measure advertising effectiveness.