

















 Copy Link
Copy Link Share on X
Share on X Share on Facebook
Share on Facebook Share on LinkedIn
Share on LinkedIn


Always Active
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Build intelligent AI systems that automate decisions, accelerate innovation, and scale business growth.
Design, build, modernize, and scale digital products that drive business growth.
Build secure, scalable, and intelligent platforms that power modern enterprises.
Build intelligent, connected, and autonomous systems that operate in the real world.
Flexible engineering capacity with predictable delivery, ownership, and outcomes.
Uncover the transformative potential of digital and mobile solutions for your industry

 Last Updated: Apr 30, 2026
Jan 13, 2022
Last Updated: Apr 30, 2026
Jan 13, 2022  13872
13872  7 min. Read
7 min. Read



Key Takeaways
Uber has changed the way we transport, forever – Uber app architechture<strong
Without owning a single car, they have triggered a revolution in the public transport industry, empowering millions of drivers to earn more money, and become micro-entrepreneurs.
As we all know, Uber is an app that connects customers (or riders) with drivers: A customer can book an Uber cab anywhere, anytime, and the nearest available cab will come to that customer and take them to their destination.
A business model can’t be more simple than that! But the way Uber has scaled, and expanded to almost every major nation in the world (except Antarctica), their success story is indeed incredible, and out of the world.
An idea that originated when their founders: Travis Kalanick and Garrett Camp found themselves stuck in Paris, because there was no cab available due to heavy snow. They asked a question: “What if you could request a ride simply by tapping your phone?”
And today, this simple question and thought have swelled to 95 million customers, 4 million drivers and $26 billion worth of gross bookings per year, with 1.44 billion rides completed in a year! (source)
In the US alone, Uber has grabbed a market share of around 70%, and 25% of Americans use Uber at least once per month. After launching in 2009, within 13 years, Uber is now present across 10000 cities, 69 nations, and counting.

How did they do this? What is their secret of operational excellence, and what goes behind that trip, which helps the customers to reach their destination?
In this blog series, we will understand Uber app architecture and design, and find out how they are able to deliver a consistent performance: every single day.
Let’s dive straight into the technical and operational world of Uber!
That trip from Destination A to Destination B seems pretty simple, and straightforward, but behind this trip, there are thousands of servers, coding, architecture and system design for ensuring 100% success.
And since the trip is always in motion, geographical data is paramount, and GPS is the main technology for that.
In order to understand and decode Uber’s backend, it’s important to know about their service-oriented architecture, which forms the foundation for their backend service.
When Uber launched in 2009, they had a monolithic architecture with a backend platform, frontend platform, and database. They used Python for coding application servers, and for all asynchronous tasks, a framework based on Python was used.
However, such monolithic architecture failed to scale, and help in real-time deliverability of services, which was the most important aspect for Uber. Monolithic architecture helped Uber to successfully operate in only one city: San Francisco.
But when it came to scaling and expanding, monolithic architecture failed to deliver.
In 2014, Uber transitioned completely to a service-based architecture system , wherein the backend, frontend, and database were integrated into one robust system. Service-based architecture supports both synchronous and asynchronous applications, fetches real-time information, and is best suited for location-independent services and requests, which was the base of Uber’s operations.
And this service-based architecture empowered Uber to scale exponentially, and become more agile, powerful and successful.
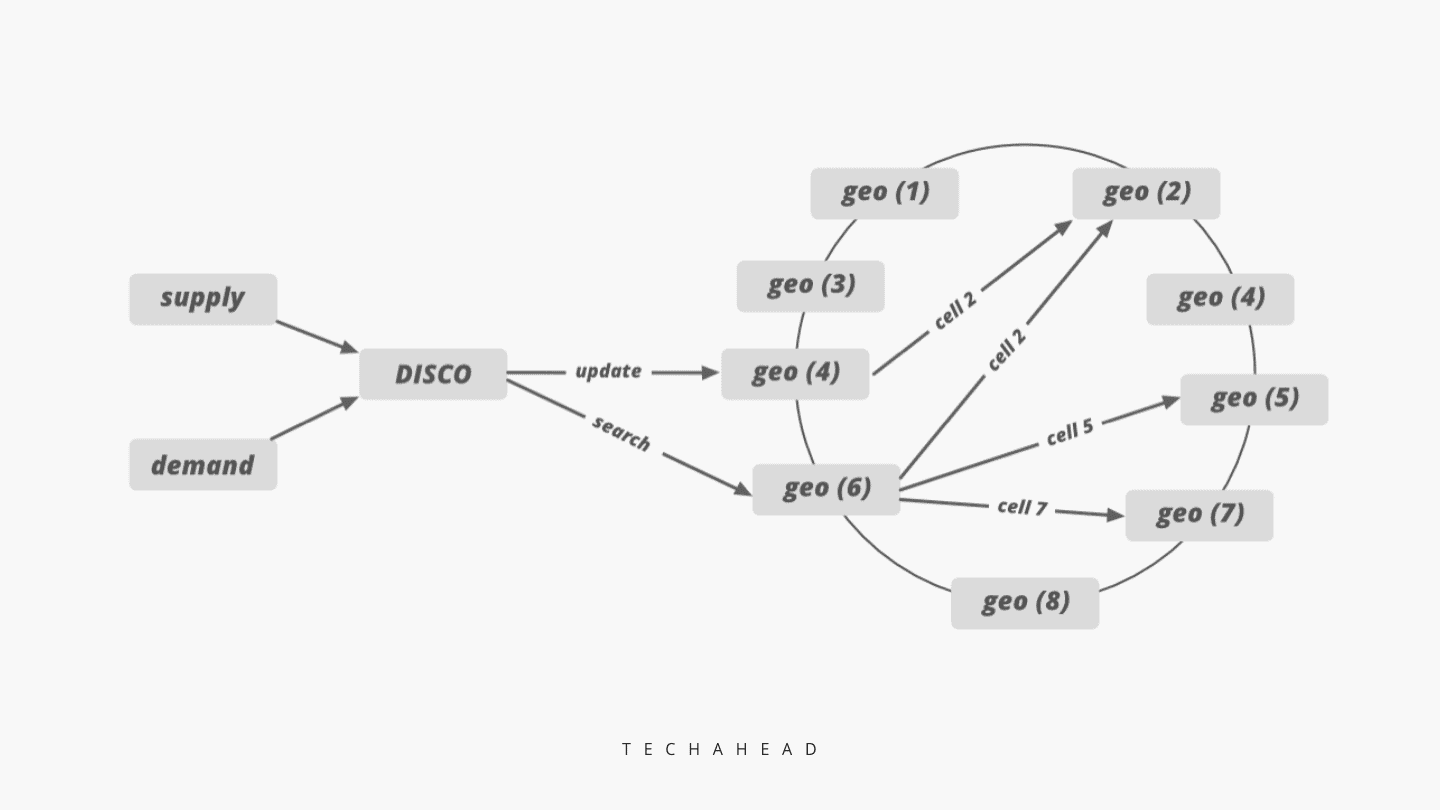
One of the biggest challenges and tasks for Uber is to connect the demand with the supply: Uber app should find out which nearby cabs are available for service, or completing their trips, and then connect them with the riders or customers who are requesting the cab.
To fulfill this critical requirement, and to connect the demand with the supply, Uber has incorporated a Dispatch system (Dispatch optimization or DISCO), that works amazingly well, and helps Uber customers to quickly and efficiently book their next ride.
And mobile phones, maps and GPS technology are the foundations based on which DISCO works.
This is now DISCO works:
Three most important objectives of DISCO are:
And to fulfill these objectives, and for a successful dispatch, Uber used Google S2 library.
Since Earth is spherical, it becomes very tough to do summarization and approximation of a location by only using latitude and longitude stats.
This is the reason that Uber uses Google S2 library, which divides the entire map location into tiny cells (say 1km x 1 km cell), and then provides a unique ID for every such cell.

Using such unique ID based tiny cells, Uber can quickly find out which cabs are nearby to that customer, who has just fired the Uber app for booking a ride.
The Google S2 library will filter out all conditions, conduct spatial indexing of points, polylines, and polygons, and quickly inform Uber about the nearby supplies (cabs) and this forms the basis of Uber’s dispatch system or DISCO.
Since Google has already extensive coverage of global maps, details about almost every geographical location, Uber leverages this information and is able to find out the distances, computing centroids and implement snap rounding for quickly finding out the nearby cabs.
With Snap Rounding, which is a geometric technique, any application can swiftly use accurate coordinate representations to implement a service request, robustly.
Now, after understanding Uber’s service-oriented architecture, and their DISCO or Dispatch System along with the role of Google S2 library in using geographical data, we know how Uber is able to find the nearest cab for the customer.
But how does Uber match a driver with the rider? This happens after using the unique ID of the tiny cells that acts as a sharding key in DISCO.
This is how it happens:
In the next part, we will understand and decode the system design of Uber’s backend architecture and decode more details about the components of DISCO to find out how Uber actually works.
Are you searching for Uber app developers– expert programmers who can develop and launch similar applications like Uber? Get in touch with our team, where passionate, talented and experienced programmers, project managers and system architects are building the next disruptive mobile application, and unleashing a digital transformation for startups, enterprises and corporations.
We use cookies to ensure our website functions properly, improve performance, and provide a personalized experience. You can choose which types of cookies to allow below.
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Help us understand site traffic and user interactions so we can improve performance and usability.
Enable enhanced functionality and personalization such as language or region preferences.
Used to deliver relevant ads, track campaign performance, and measure advertising effectiveness.