

















 Copy Link
Copy Link Share on X
Share on X Share on Facebook
Share on Facebook Share on LinkedIn
Share on LinkedIn


Always Active
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Build intelligent AI systems that automate decisions, accelerate innovation, and scale business growth.
Design, build, modernize, and scale digital products that drive business growth.
Build secure, scalable, and intelligent platforms that power modern enterprises.
Build intelligent, connected, and autonomous systems that operate in the real world.
Flexible engineering capacity with predictable delivery, ownership, and outcomes.
Uncover the transformative potential of digital and mobile solutions for your industry

 Last Updated: Jul 17, 2026
Jun 3, 2026
Last Updated: Jul 17, 2026
Jun 3, 2026  410
410  19 min. Read
19 min. Read



Key Takeaways
Most systems do not break gradually. They break all at once; right when it matters most. Discord hit 19 million active communities. Millions of people, connected and talking, at the same time. However, the thing is Discord did not start there.
They started as a startup using an early Node.js prototype and a single MongoDB database. The same stack thousands of startups are running right now.
What changed was not just the code. It was the decisions; when to refactor, what to rebuild, and which problems to solve before they became crises. So this blog breaks down exactly how they did it. And more importantly, what enterprise teams can learn from it.
Discord did not launch with a grand vision of becoming the internet’s communication backbone. It started in 2015 as a fix to a frustration; gamers needed a better way to talk while playing. No lag, no complicated setup, just a clean voice and text chat tool.
That is it. That was the pitch. This is the MVP Architecture Looked Like in 2015
The first version of Discord was simple by design. A single application handling everything (messaging, user management, notifications); all in one place. No fancy distributed systems. No microservices. Just a monolith that worked well enough.
And for a small user base, it held up fine.

To build this monolith quickly, Discord’s founders made a highly strategic choice. Instead of traditional languages like Python or Ruby, they built their core backend using Elixir.
Elixir gave them the best of both worlds: it was fast to write and easy to iterate like Python, but it ran on the Erlang virtual machine (BEAM), which was explicitly designed to handle millions of simultaneous, real-time connections without lagging.
For data storage, they quickly adopted MongoDB. MongoDB gave them incredible flexibility early on; with no rigid database schemas, the team could change data structures and ship features without friction.
However, speed comes with a cost. As users scaled into the millions, that same stack, built for speed, not scale, started cracking under the pressure.
This is the growth nobody planned for; Discord grew fast. Unusually fast. Word spread through gaming communities, streamers started using it, and suddenly millions of users were piling in. By 2017, Discord had crossed 25 million registered users. And the infrastructure? It was still largely the same system built for a fraction of that load.
The monolith started struggling under concurrent connections. Real-time messaging demands low latency. Every millisecond of delay is noticeable. Users felt it. Messages lagged. Voice channels dropped. The experience that made Discord popular was now at risk. The team was not dealing with a gradual slowdown. They were dealing with a system that simply was not designed for what Discord had become.
MongoDB worked beautifully in Discord’s earliest days. However, around November 2015, as the platform hit 100 million stored messages, a critical hardware threshold was breached: the message data and its indexes could no longer fit entirely within the server’s RAM.
Because a real-time chat platform requires a brutal, near-50/50 split of heavy writes (sending messages) and heavy reads (loading histories), MongoDB began thrashing its disks to keep up. Latencies became entirely unpredictable, and traditional sharding mechanisms proved too complex and unstable to solve the core issue.
Discord moved to Apache Cassandra; a distributed NoSQL database built for write-heavy, high-availability workloads. Cassandra offered two things Discord desperately needed:
It was not a perfect fix. Cassandra brought its own problems down the road. However, in that moment, it was the right call; a system that could actually breathe under the load Discord was throwing at it. Sometimes the best architectural decision is not the final one; it is just the one that buys you time to grow into the next problem.
There is a point in every fast-growing product’s life where the monolith stops being an asset and starts being a liability. For Discord, that point came hard and fast.
One bug in one part of the system could ripple across everything. A deployment meant taking risks with the entire application. The codebase had become a tangled web, and untangling it while the product was live, with millions of users, was like replacing an engine mid-flight.
The solution was not just to break the monolith into generic microservices; it was a deliberate strategy of architectural decoupling and fault isolation.
In a traditional monolith, one unhandled exception can crash the entire system. Discord changed this equation entirely by leveraging the Actor Model inherent to Elixir.
Instead of a massive web server handling all operations globally, Discord treated every single chat community (known internally as a “Guild”) as an isolated, lightweight process in memory. If a massive community with 100,000 concurrent users experienced a sudden spike or software glitch, that failure was completely contained within that single process. The rest of the millions of communities on Discord kept flowing smoothly, completely unaffected.
Shipping new features on a monolith is slow. Every change requires testing the entire application. One bad line of code can block a deployment that has nothing to do with it.
Microservices let Discord’s teams deploy independently. The team working on search did not have to wait for the team working on voice. Each service had its own deployment pipeline, its own release cycle. Shipping became faster, safer, and far less stressful.
Microservices are not free; and any enterprise team treating them as a default solution is making a mistake.
A monolith is one thing to monitor, one thing to deploy, one thing to debug. Microservices can mean dozens, sometimes hundreds of services running simultaneously. Each one needs its own logging, monitoring, and failure handling. Without strong DevOps maturity, that complexity becomes a burden fast.
When something breaks in a monolith, you find it in one codebase. When something breaks across microservices, the failure can be anywhere, and tracing it across service boundaries takes time, tooling, and experience.
Before switching, enterprise teams should ask one honest question; is the monolith actually the problem? Or is it just easier to blame the architecture than fix the underlying issues? Microservices solved real problems for Discord. However, Discord had the engineering team, the tooling, and the scale to justify it. For teams that do not; a well-structured monolith still beats a poorly managed microservices setup every single time.
Real-time messaging sounds simple. You type, they see it. Instantly.
However, behind that instant is an enormous amount of engineering. At 45 million concurrent users, even a 200-millisecond delay feels broken. Discord could not afford that; their entire product promise depended on messages arriving fast, every time, without fail.
The answer was WebSockets. And a very deliberate decision about how to use them.
Most teams reach for standard WebSocket libraries, hook them up to a central broker, and consider the job done. For early-stage products, that is completely reasonable. However, generic real-time setups come with massive assumptions about traffic patterns, state management, and reconnection storms.
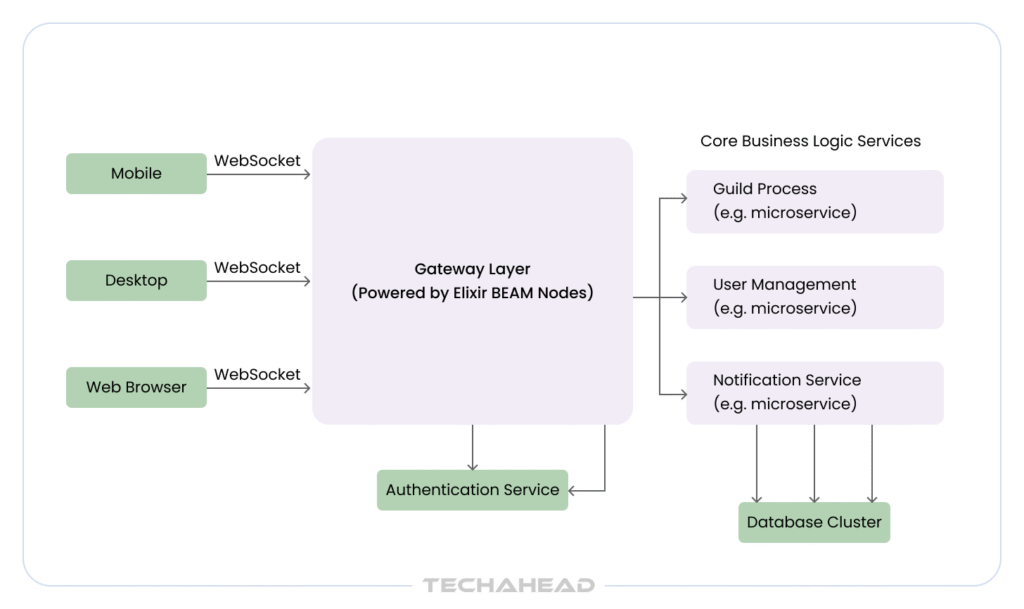
Instead of routing messages directly through standard app nodes, Discord engineered a specialized, distributed entry point called The Gateway Layer.
Powered by an optimized cluster of Elixir nodes, this custom Gateway infrastructure isolates persistent connection management entirely away from the changing business logic. By tailoring exactly how user presence is cached and how disconnects are handled through custom Session Resumption buffers, they ensure a user stepping into an elevator doesn’t trigger a database-crushing reconnection loop when they exit.
Custom Session Resumption
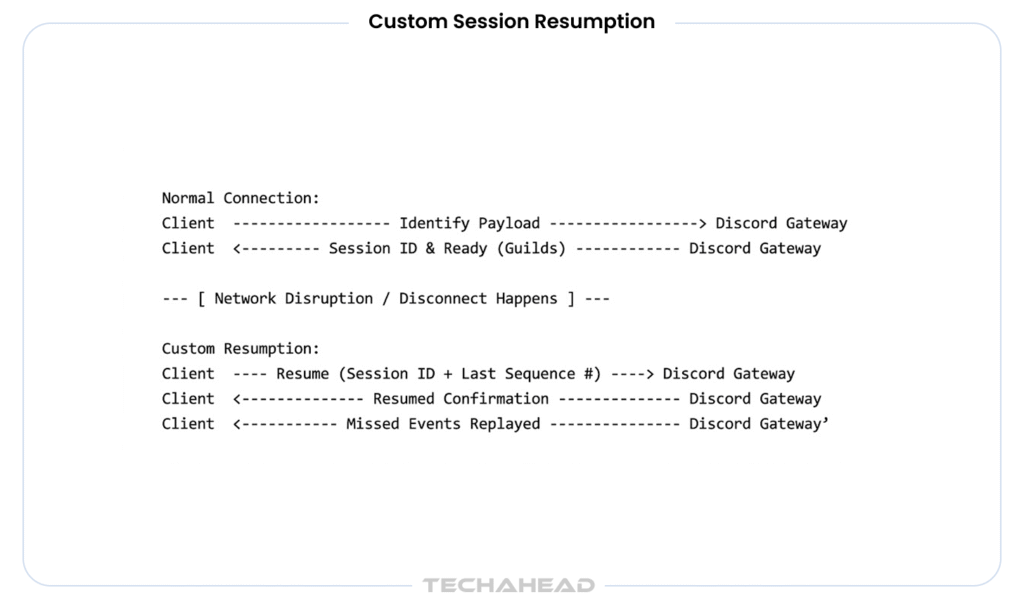
It required significantly more upfront system design work, but it unlocked the predictable, sub-millisecond data routing performance required under true global load.
Every client (desktop, mobile, browser) connects to Discord through the Gateway. It’s the single entry point that manages authentication, maintains persistent connections, and routes events to the right place.
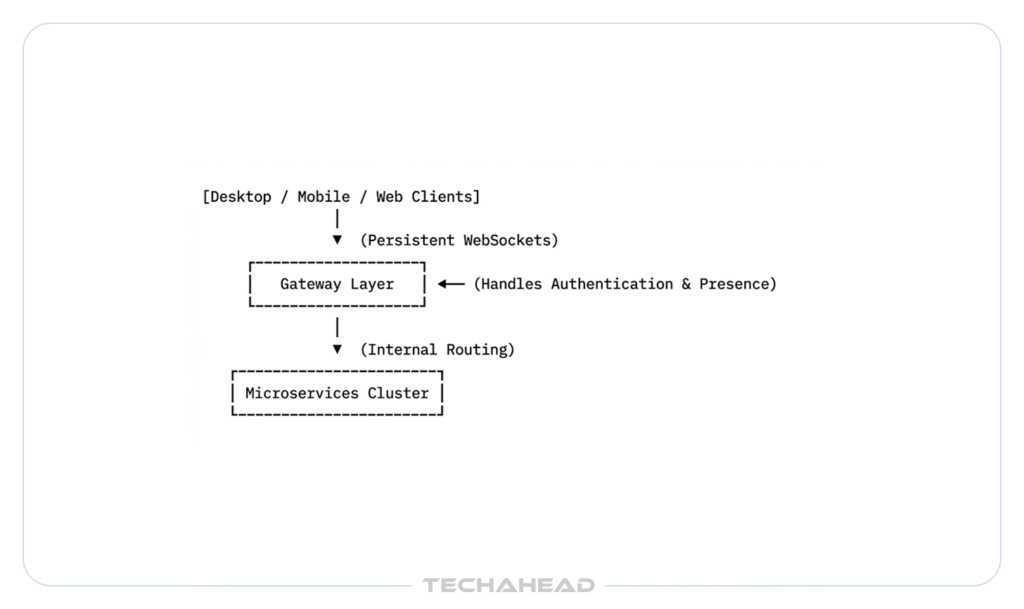
Think of it as a traffic cop sitting at the front of an incredibly busy intersection. Millions of connections arrive simultaneously. The Gateway decides what goes where, keeps sessions alive, and makes sure nothing gets lost in transit.
Separating the Gateway from the rest of the backend was a smart call. It means connection management is handled independently without touching message storage, voice infrastructure, or any other service. One layer does one job. And at scale, that focus is exactly what keeps things fast.
When deciding between a Custom WebSocket Implementation and Off-the-Shelf (OTS) Solutions for a Discord-like app, the choice depends on your scale, budget, and customization needs.
Choosing a programming language is not just a technical decision. It is a bet on how your system will behave when everything is on fire.
Discord bet on Elixir. And it paid off.
Erlang was built in the 1980s for telecom systems; networks that couldn’t afford downtime, ever. The BEAM virtual machine runs millions of lightweight processes simultaneously, each isolated, each fault-tolerant. One process crashes but the rest keep running. That’s exactly the behavior a real-time platform needs.
Every Discord server runs as its own Elixir process, called a Guild Process. It handles all activity for that server independently. One busy server does not slow down another. Clean, isolated, scalable.
BEAM allows code updates on a live, running system. No restart. No downtime. Discord could ship fixes and improvements while millions of users stayed connected.
Elixir got Discord far. However, when Discord needed to process computationally heavy workloads millions of times per second, Elixir started showing its ceiling.
So Discord did not replace Elixir. They extended it with Rust.
NIFs are a way to call native code directly from Elixir. Discord used this to drop into Rust for specific, performance-critical operations without throwing away the entire Elixir infrastructure they’d already built.
It is a surgical approach; keep Elixir managing concurrency and processes. Let Rust handle the heavy lifting underneath. The two languages work together, each doing what it is actually good at.
The results were immediate. Tasks that were creating bottlenecks in Elixir; things like data serialization, permission checking across massive servers, and real-time analytics ran significantly faster once moved to Rust.
Memory usage dropped. Latency improved. And critically, the BEAM VM stayed unblocked; free to keep managing millions of concurrent connections without CPU-heavy tasks getting in the way.
Rust did not save Discord’s architecture. Elixir already provided the concurrency model and fault tolerance that powered Discord’s real-time platform. Rust complemented that foundation by accelerating performance-critical workloads and reducing CPU overhead.
For enterprise owners, it shows that you do not need a one-size-fits-all programming language. Build your core architecture in the language that handles your primary business paradigm best, and drop down into low-level systems languages like Rust only where raw hardware performance is required.
Cassandra saved Discord once. Then it became a problem.
By 2022, Discord was running 177 Cassandra nodes storing trillions of messages. The system that once gave them breathing room had turned into a constant maintenance headache with engineers firefighting database issues instead of building products.
A common misconception is that Cassandra’s underlying storage mechanism failed. In reality, the crisis stemmed from its runtime environment. Cassandra is written in Java, meaning it relies on a Java Virtual Machine (JVM).
At a scale of trillions of messages, massive read requests and heavy compaction workloads forced the JVM into frequent, unpredictable “Stop-the-World” Garbage Collection (GC) pauses. The entire database node would freeze for seconds at a time to clean up memory, causing severe latency cascades across the entire platform.
Discord chose ScyllaDB as its long-term database solution. Because ScyllaDB is API-compatible with Cassandra, the team avoided rewriting their entire data layer. However, under the hood, the differences were massive:
Migrating a massive, live transaction system cannot be done via a simple copy-and-paste. To achieve zero downtime, Discord executed a highly disciplined enterprise migration framework:
The result? Trillions of messages moved seamlessly. Zero downtime. Perfect operational continuity.

Discord’s journey from a gaming chat app to a platform handling 45 million concurrent users was not luck. It was a series of hard, deliberate decisions; many of them made under pressure, with real consequences. Enterprise teams do not need to copy Discord. But they would be smart to learn from them.
Here are 7 architecture lessons you should consider:
Discord started with a monolith an early Node.js web prototype, and a single MongoDB instance. For their initial user base, that was the right call.
Premature optimization is one of the most expensive mistakes an engineering team can make. Building distributed systems before you need them adds complexity, slows development, and burns through engineering hours solving problems you do not have yet.
Discord’s approach was simpler; build what works now, monitor aggressively, and scale when the data says it is time. Not before that.
For enterprise teams, the lesson is clear:
Choosing a programming language is more than a developer preference; it defines your system’s ceiling. Discord’s early bet on Elixir and the BEAM VM fundamentally altered what their infrastructure could handle. The BEAM VM’s concurrency model, millions of lightweight, isolated processes, unlocked capabilities Python simply could not offer. Most enterprise teams treat language choice as a preference. Discord treated it as a strategic decision.
Ask your team honestly: is your current language stack capable of handling 10x your current load? If the answer is uncertain, that uncertainty is worth addressing now, not during a crisis.
MongoDB to Cassandra. Cassandra to ScyllaDB. Discord changed databases twice; it is not because the original choices were wrong, but because each one hit its ceiling. The lesson is that most teams wait too long to plan the next migration. By the time performance problems are visible to users, the engineering team is already behind.
Discord moved to microservices when the monolith became an obstacle, not before. The decision was driven by real pain: slow deployments, cascading failures, teams blocking each other.
Enterprise teams often adopt microservices because it sounds modern. That is the wrong reason. Microservices add operational complexity that smaller teams and simpler systems do not need.
The right question is not “should we use microservices?” It is “what specific problem are microservices solving for us right now?”
One of the clearest wins from Discord’s architectural evolution was fault isolation. When services are independent, failures stay contained. A broken notification service does not kill messaging. A struggling search feature does not drop voice calls. Enterprise systems that lack fault isolation are one bad deployment away from a full outage.
Discord used Elixir until it needed Rust. Used Cassandra until it needed ScyllaDB. They never got attached to a specific tool. When the data showed a better path, they took it, even when it meant significant migration work.
Technology loyalty is a quiet killer in enterprise engineering. Teams hold onto familiar stacks long past the point where they are serving the product. The engineers who scaled Discord asked one question about every technology decision: does this still serve us, or are we serving it?
When massive concurrency spikes began causing unpredictable latency, Discord launched a legendary internal optimization initiative called Project MaxJourney. They did not guess at solutions; they engineered deep custom instrumentation, stack traces, and event-loop metrics to profile their internal processes down to the microsecond. You cannot fix what you cannot see.
For enterprise teams:
Discord’s architecture did not happen in one brilliant moment. It evolved under pressure, through real failures. That is actually the most useful thing enterprise teams can take from this story. You do not need perfect architecture on day one. You need the discipline to keep improving it, the humility to change when the data demands it, and the foresight to plan for the scale you are heading toward.
Discord’s story is not really about Discord. It is about what happens when a system meets reality, and either holds up or falls apart. The teams that scale successfully are not the ones with the biggest budgets. They are the ones that make deliberate decisions early, adapt without ego, and treat architecture as a living thing, not a one-time project. Now, the question is whether your infrastructure is ready for social media app development.
TechAhead is an AWS Advanced Tier Partner, Claude, and OpenAI Services Partner, holding SOC 2 Type II and ISO 42001 certifications. With 16+ years of experience, 2,500+ apps delivered, and enterprise clients like Audi, Disney, and American Express, we build scalable, secure systems for enterprises that perform under real-world load. Let’s talk about your architecture.

Discord handles millions of concurrent users by separating connection management from application logic. Every client connects to a specialized Gateway layer powered by a highly optimized cluster of Elixir nodes. Running on the BEAM virtual machine, the system operates millions of lightweight, isolated processes simultaneously. Each chat community runs as its own self-contained “Guild Process,” ensuring that a massive surge in one server never impacts the speed or stability of another.
Move when the monolith is causing real, measurable pain: slow deployments, cascading failures, or teams constantly blocking each other. Not before. Microservices add serious operational complexity. If your monolith is still serving you well, optimize it first. The switch should be driven by data, not by industry trends.
It depends on your scale and existing architecture. A foundational scalable backend starts from $50,000 for mid-sized applications, scaling into six or seven figures for distributed systems. The bigger cost question is not what it costs to build it right; it is what it costs when it fails.
Start with your system’s core demands. High concurrency? Elixir or Go. CPU-intensive processing? Rust or C++. Rapid iteration with large talent pools? Python or Java. Do not choose based on familiarity alone. The language your team knows best is not always the language your system needs most.
Reactive fixes during a crisis cost three to five times more than proactive architectural investment. Downtime directly impacts revenue, user trust, and brand reputation. Every dollar spent on scalable architecture upfront buys stability, faster deployments, and the ability to grow without rebuilding everything under pressure.
We use cookies to ensure our website functions properly, improve performance, and provide a personalized experience. You can choose which types of cookies to allow below.
Required for core functionality such as security, network management, and accessibility. These cannot be disabled.
Help us understand site traffic and user interactions so we can improve performance and usability.
Enable enhanced functionality and personalization such as language or region preferences.
Used to deliver relevant ads, track campaign performance, and measure advertising effectiveness.